モデルの作成
以下はWebアプリケーション RapidMiner Goについてのドキュメントです。
RapidMiner Goはデータから予測モデルを速く、シンプルに作成できるよう設計されました。必要なものはデータセット(Excelスプレッドシートのような)と予測したいもののみです。とてもシンプルですね!
最初に述べたように、以下のステップで進みます。
- データのアップロード — 関連がありそうなすべてのデータをアップロードします。
- 列の選択 — 予測したい値をもつ列を選択します。
- 入力の選択 — 関係のないデータを削除し、関係があるデータを決めます。
- モデルの選択 — 作成するモデルを一つ以上選択します。
ステップ4までで、一つ以上のモデルを作成できました。この後、 モデルの検証 を行い、目的にもっとも合うものを決めます。
ステップ 1: データのアップロード
プライバシーは大切です。個人情報を含んだデータをアップロードしないでください。
そのような情報を含む列は除外するか、 匿名化 もしくは 仮名化を行うことをおすすめします。
RapidMiner Goは以下の状態のExcelもしくはCSVのスプレッドシートデータを受け付けます。
- 無制限の行
- 最大500列
- 最大50MBのファイルサイズ
もし利用できるデータセットがなく、ただこのアプリケーションを試してみたい場合は、 Use Sample Dataset(サンプルデータセットの使用)ボタンを押し、”Churn Prediction Data”を選択してください。そうでない場合は、 Upload Data(データのアップロード)を押してください。
| CSV | Excel |
|---|---|
|
|
ステップ 2: 列の選択
以下からは、サンプルデータセット”Churn Prediction Data”を用いて説明を行います。このデータは電話会社の顧客に関するもので、サブスクリプションを継続するか、離反するかについてのデータです。
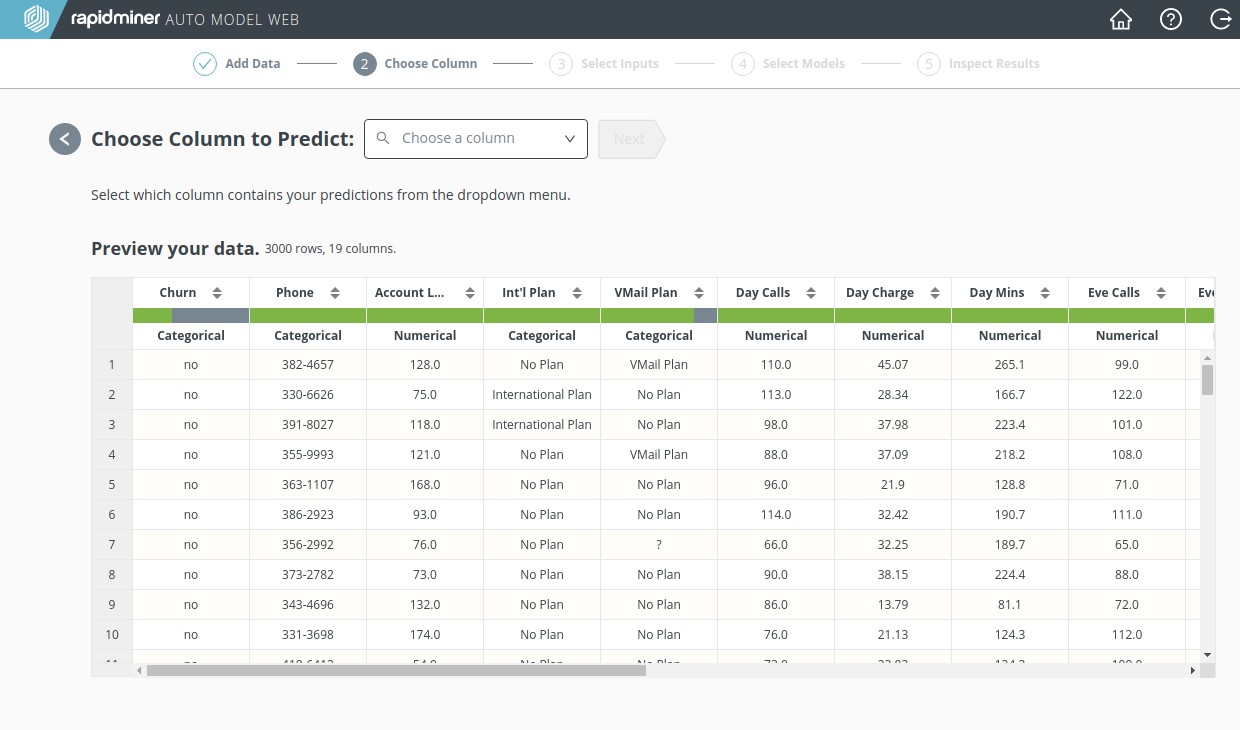
データ列の一つは予測したい値を持ち、このような列を 目的変数(target column) と呼びます。今回の例では、誰が離反するかを予測したいため、目的変数は”Churn”です。ドロップダウンメニューから”Churn”を選択し、 Nextをクリックします。
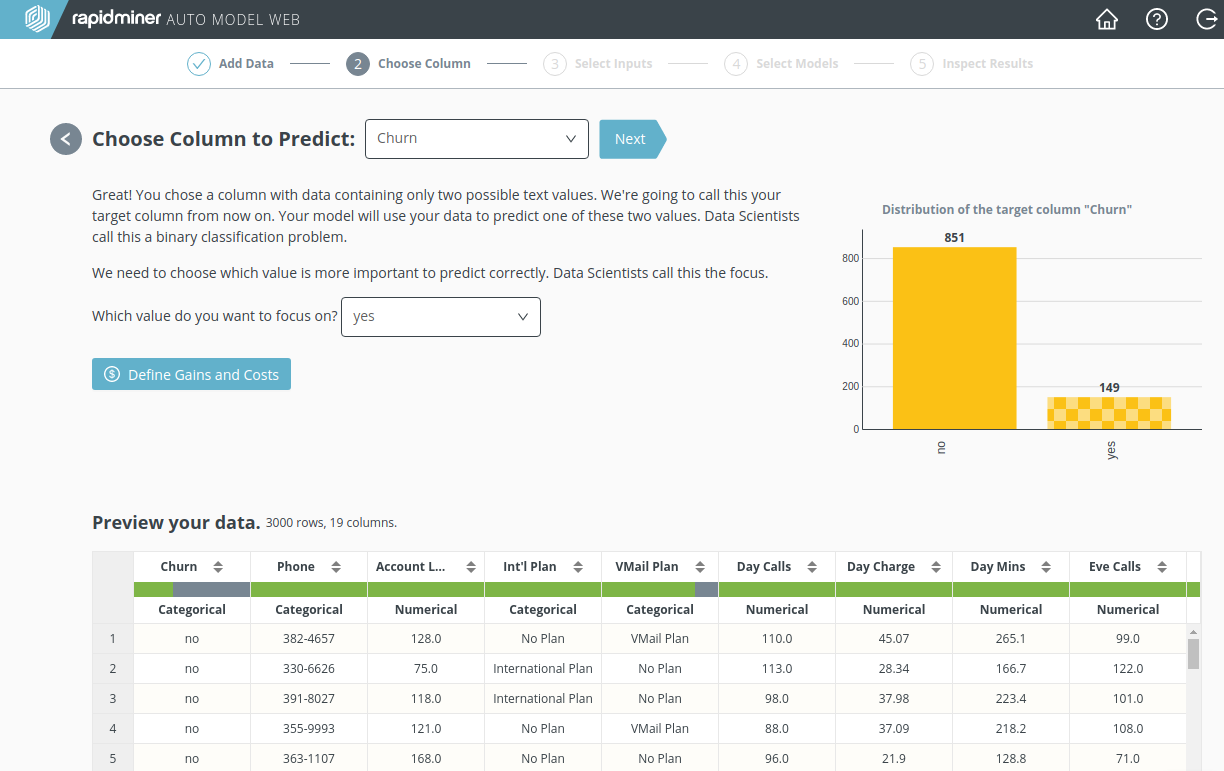
一般的に、目的変数の値は数値(“CustServ Calls”のような)、もしくはカテゴリ値(“Churn”のような)です。目的変数によって、以下の三つのカテゴリに分類されます。
- 二項分類(Binary classification) -(“Churn”のように)二つの値をもつカテゴリデータ
- 多項分類(Multiclass classification) – 三つ以上の値をもつカテゴリデータ
- 回帰(Regression) – (“CustServ Calls”のような)数値データ
列を選択すると、RapidMiner Goは自動的にどのタイプか判別します。各タイプの詳細は、以下を参照してください。
1.二項分類 (二つの値のうちどちらかを予測します)
yes-or-noアンサーの場合もあります。例えば、検査を受けた場合、結果は positive(陽性) か negative(陰性)で表されます:
- Positive : 検査により、求めているものが見つかりました(例:感染)
- Negative : 検査により、求めているものが見つかりませんでした(例:感染していない)
結果がpositive(陽性)なら、検査がさらに必要になる場合がありますが、結果がnegative(陰性)ならそれらは必要ありません。医療は感染症を治療することに重きを置くため、おそらく陽性の結果は重要であり、より注意する価値があるでしょう。
“Churn”は”yes”か”no”の値を持つため、今回の例は二項分類です。また、どの顧客が離反するかを予測したいので”yes”に注目します。
2.多項分類 (三つ以上の値の中から一つを予測します)
目的変数が三つ以上の 数値でない 値を持っていれば、多項分類と呼ばれる問題です。
3.回帰 (数値を予測します)
目的変数が数値で、かつその列の数値を予測したいなら、回帰と呼ばれる問題です。例えば、”Churn Prediction Data”は”CustServ Calls”列をもっており、この列には顧客がカスタマーサービスに電話をかけた回数が入っています。
ステップ 3: 入力の選択
データの全ての列が予測に役立つわけではありません。一部の列を削除することで、モデル作成のスピードが上がり、かつ(または)モデルの パフォーマンスも向上するかもしれません。しかし、どのようにその判断を下せばいいでしょうか? キーポイントは、あなたはパターンを探しているということです。データに変化がなく、認識可能なパターンがない場合、そのデータは役に立ちそうにありません。
RapidMiner Goでは、ある列が役に立つかどうかを四つの指標を用いて判断しています。
- Correlation – 値が目的変数にどのくらい似ているか
- ID-ness – 値が他の値とどのくらい異なるか
- Stability – 値が他の値にどのくらい似ているか
- Missing – 全体にたいして列にどのくらい欠損値があるか
データの質に応じて、各列はそれぞれ緑、黄、赤のタグを付けられます。
| 緑 良い |
黄 検証する必要あり |
赤 悪い |
|---|---|---|
|
|
デフォルトでは、RapidMiner Goは赤もしくは黄のタグを付けられた列を除外しますが、もちろん自由に好きな列を選択もしくは除外することが可能です。通常、デフォルトの状態でうまく動きますが、列に黄のタグが付き、 high correlationと付いている場合は注意してください。
high correlation(相関が高い)問題を理解するために、完全に相関がある極端な例を用いて考えてみます。XとYの二列があるとして、X = Y なら相関は100%でXはYのただの別名ということになります。もしXを予測するなら、Y列は冗長なのでY列を削除するでしょう。相関が100%未満でも、冗長になる可能性があります。次の問いを考えてみてください。予測を行うより先に、相関が高い列のデータにアクセスできるでしょうか? もしそうでないなら、そのデータは役に立ちません。
しかしながら、目的変数に高い相関があるからこそ、その列が予測に役立つ場合があります。もしその列を削除すると、 モデルにダメージを与える可能性があります。確実に言えるのは一つだけです。疑問がある場合は、相関が高い列がある場合とない場合の二つのモデルを作成すると、どちらが良いかを判断しやすくなります。
入力の選択, Churn Prediction Data
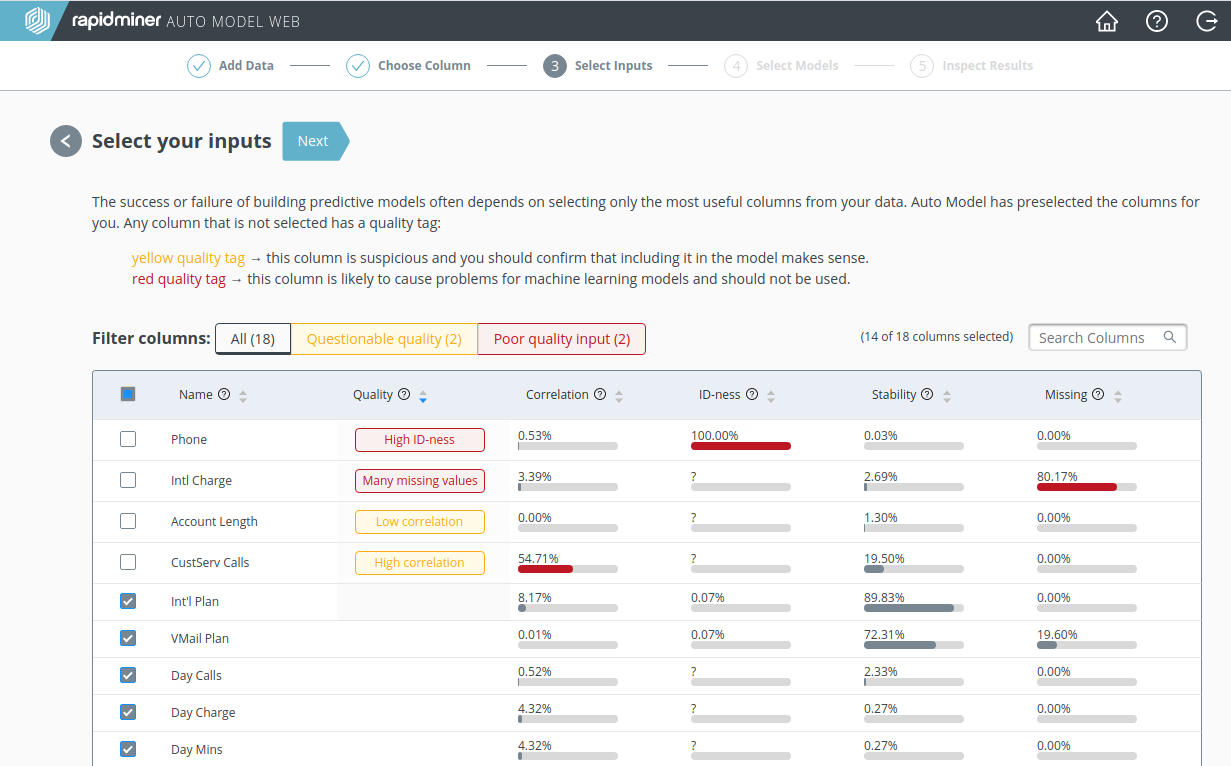
RapidMiner GoはChurn Prediction Dataについて以下のように判断します。
- ID-nessが高い: “Phone”はIDで、各顧客にたいしてユニークです。churnの予測には意味がありません。
- 欠損値が多い: 顧客のうち20%しか国際料金(“Intl Charge”)の値を持っていないため、このデータ列からわかることはあまりありません。
- correlationが低い: “Account Length”と”Churn”の間の相関は0です。顧客が電話会社と契約していた期間と離反する可能性はほとんど、もしくは全く相関がないようです。そのため、”Account Length”は役に立ちそうにありません。
デフォルトでは、これらのデータ列が全て除外されます。もう一つ除外される列がありますが、それにはさらに議論が必要になります。
- correlationが高い: “CustServ Calls”は”Churn”と57%相関があります。
明らかに、カスタマーサービスへのコール数は離反するかどうかの良い指標になります。顧客がカスタマーサービスへ繰り返し電話をかけてきたなら、電話会社はその顧客を維持できるように積極的な措置を講じることをおすすめします。しかし、モデルを作成する際に”CustServ Calls”を含めたいでしょうか? 私たちが少し前にたずねた問いに戻ってみましょう。予測を行うより先に、相関が高い列のデータにアクセスできるでしょうか? この場合は、答えは yesです。したがって、モデルの予測がその列の値に大きく重み付けされることを理解したうえで、モデルに”CustServ Calls”を含めることを選択します。
カスタマーサービスへのコールデータがある場合とない場合の結果へ飛ぶ
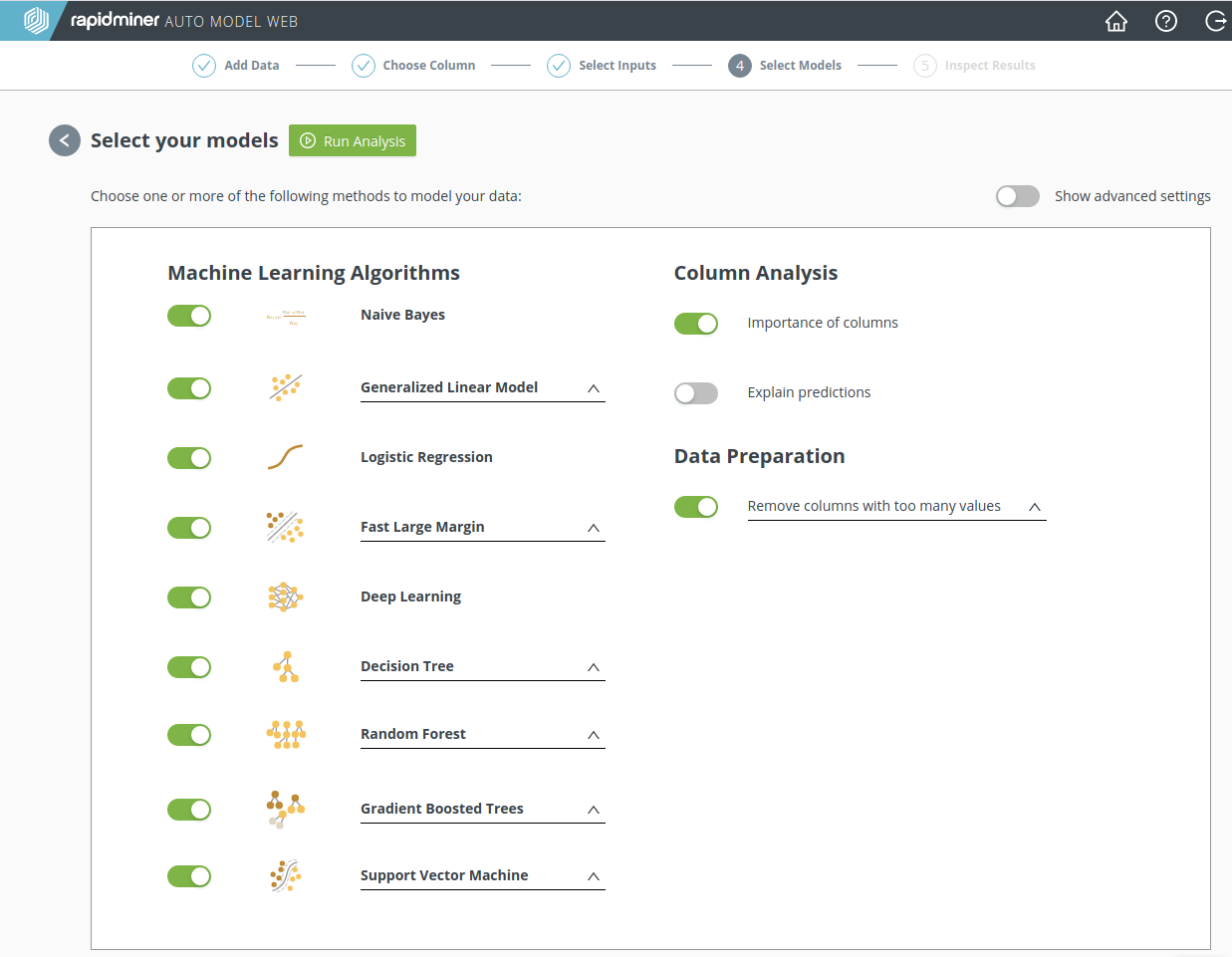
ステップ 4: モデルの選択
RapidMiner Goは人気のある機械学習アルゴリズムを提供しています。目的変数のデータタイプに応じて、これらのアルゴリズムのサブセットが利用可能です。
| 二項分類 | 多項分類 | 回帰 | |
|---|---|---|---|
| Naïve Bayes |  |
 |
 |
| Logistic Regression |  |
 |
 |
| Deep Learning |  |
 |
 |
| Decision Tree |  |
 |
 |
| Generalized Linear Model |  |
 |
 |
| Random Forest |  |
 |
 |
| Gradient Boosted Trees |  |
 |
 |
| Support Vector Machine |  |
 |
 |
| Fast Large Margin |  |
 |
 |
含めたいモデルを選択し、 Run Analysis(分析の実行)ボタンを押します。
Next: モデルの検証
参考文献
RapidMiner Goで使用される予測モデルアルゴリズムについて、詳細は以下のRapidMinerドキュメントのリンクを参考にしてください。
- Naïve Bayes
- Logistic Regression
- Deep Learning
- Decision Tree
- Generalized Linear Model (GLM)
- Random Forest
- Gradient Boosted Trees
- Support Vector Machine
- Fast Large Margin
