モデルの検証
以下はWebアプリケーション RapidMiner Goについてのドキュメントです。
結果
RapidMiner Goの最初の4ステップまでは、クリックで進んできたかもしれません。ここからはペースを落とし、あなたの専門知識を発揮しなければなりません。最初は結果に圧倒されるかもしれませんが、目的を見失わないようにしてください。
- 最も役に立つモデルを決めるのに役立ちます( 評価指標 や モデルの比較を参照してください。)
- モデルとデータの理解に役立ちます( 重み や モデルシミュレータを参照してください。)
- ステップ(1)と(2)を完了した後、 予測を行います
もしユーザーフレンドリーな部分から開始したい場合は、 モデルシミュレータを見てみてください。
モデルをブラックボックスとして扱い、ただ新規データを差し込み予測を行いたいという誘惑があるかもしれません。しかし、ブラックボックスな予測の結果は誤解を生む可能性があります — 例のChurnのサマリーを参照してください。
目次
評価指標
モデルが良いか悪いか、特に他のモデルより良いか悪いかを言うためには、比較に関する基礎知識が必要になります。モデルの成果に数値指標、いわゆる評価指標を割り当てることで、他のモデルと比較し相対的成果を得ることができます。
複雑なのは、たくさんの評価指標が存在し、それらは成功の基準として絶対的なものではなく、解決したい問題に応じてそれぞれ強みと弱みを持っています。あなたの問題に合ったベストな評価指標を選ぶ必要があり、その指標を用いて最も良いモデルを選ぶことができるでしょう。
評価指標の計算には、まずデータの80%(学習データ)をランダムに選んでモデルを作成することから始めます。モデルを作成できれば、残りの20%(テストデータと呼びます)をそのモデルに適用し、既知の値と予測を比較します。理想では違いがないものが望ましいですが、予測が100%合うことはめったにないため、実際にはたいてい違いがあります。
2. 列の選択で目的変数の値に応じて解く問題のタイプが異なったことを思い出してください。目的変数はカテゴリデータでしょうか?それとも数値データでしょうか? 予測したい値に応じて、評価指標は異なります。詳細な議論や例は以下のリンクを参照してください。
モデルの比較
評価指標を選択できれば、その指標による最も良いモデルを見つけるのに役立つ、model comparison(モデルの比較)を利用できます。
モデルの比較では、各モデルのパフォーマンスを以下のように表示します。
- 棒グラフ。ある特定の評価指標に対し、モデルを直接比較します。
- テーブル。行にモデルを、列に評価指標を表示します。
評価指標をクリックすると、その指標の棒グラフが表示されます。モデルをクリックすると、 モデルの詳細が表示されます。 5A. 二項分類で述べられているように、 Recall(再現率) はChurn Prediction Dataにとって最も有効な指標です。また再現率によると、最も良いモデルは Decision Tree と Random Forestです。
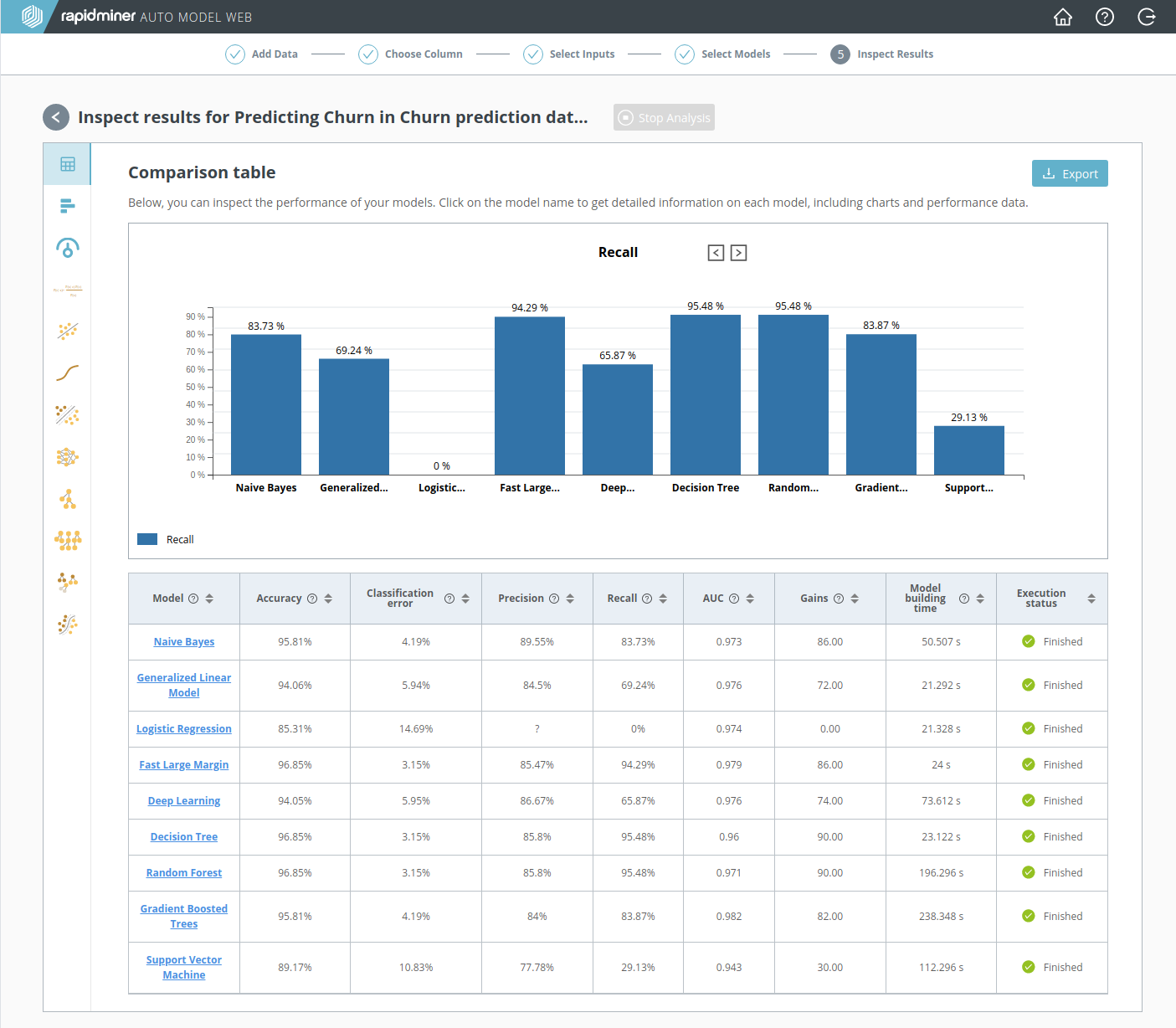
重み
Weights(重み) アイコンをクリックすると、モデルに関係なく、データについて確認できます。 重み は、どの入力データが最も予測に影響を与えたかを示します。 3. 入力の選択より、Churn Prediction Dataのうち”CustServ Calls”が最も重要な列であることは知っていました。それよりは少ないですが、次に重要なのは”Intl Plan”、”Day Mins”、”Day Charge”であると 重み は示しています。
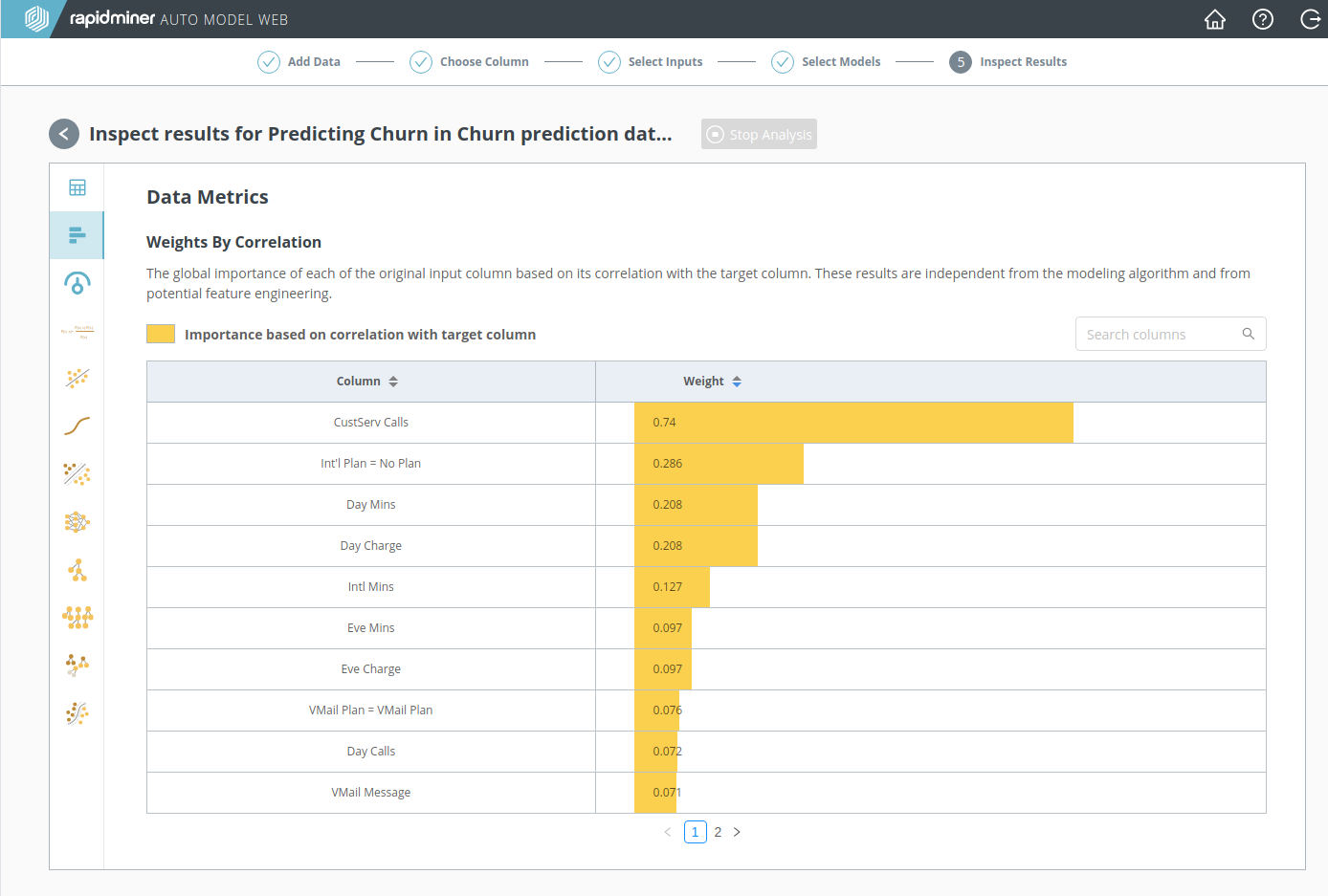
モデルシミュレータで、最も大きな重みをもつ入力データの値を変更すると、そのデータの重要性をすぐに理解できるでしょう。重みの低い入力データは影響力を持ちにくいです。
モデルシミュレータ
RapidMiner Goは結果を得るのに役立つだけでなく、結果を理解するのにも役立ちます。より良い知見を得るためには、 Model Simulator(モデルシミュレータ) のアイコンをクリックし、モデルを選択します。 モデルの比較 で決定木モデルが良いと示され、相対的に 解釈しやすいため、 Decision Treeを選択します。
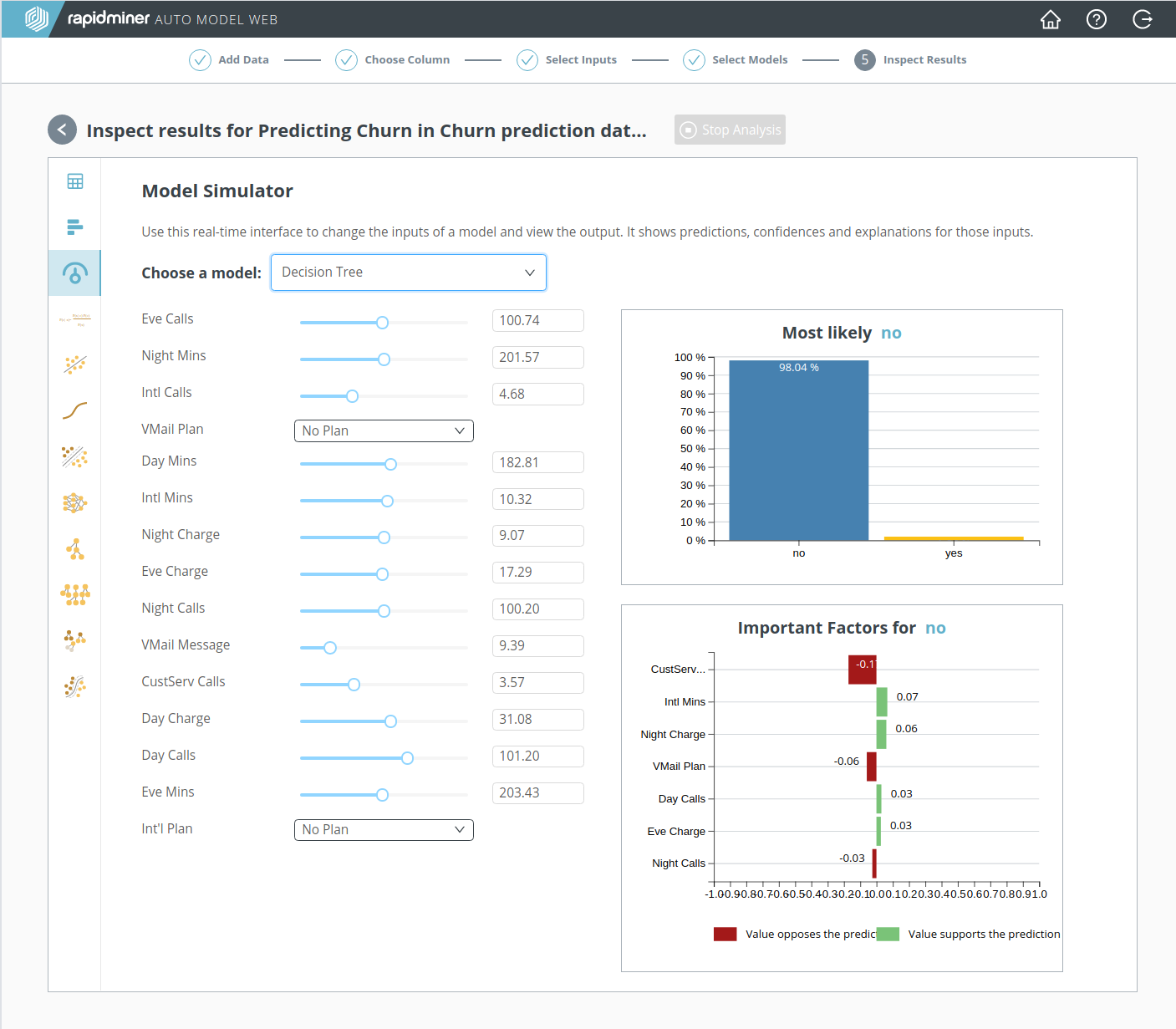
モデルシミュレータ の美しいところは、インタラクティブであるということです。そのため、思いのままに全ての値を変更でき、すぐに予測への効果を確認できます。すべてのスライダーやドロップダウンリストを操作することで、たとえDeep Learningのような解釈が難しいモデルへも、直感を働かせることができます。
初期状態では、 モデルシミュレータ は左に表示されているデータの平均値を取ります。右側には、important factors(重要な要因)とともに予測が表示されます(“no”、つまり平均的な顧客は離反しないだろう)。重要な要因の一番上には、”CustServ Calls”があり、最も大きな 重みをもつデータ列です。モデルを作成する前の 3. 入力の選択でも、目的変数と高い相関をもつと示されていました。
“CustServ Calls”のスライダーを 3.57の初期値から前後に移動させると、学びを期待できます。特に”CustServ Calls”の値を 7.00まで増やすと、予測が”no”から”yes”へ切り替わることに気づくでしょう。結論? カスタマーサービスへの電話が多すぎると、その顧客は離反するでしょう!他のスライダーで同じような影響を与えるものはありません。
“CustServ Calls”の値が6と7の間にあるとき、”no”から”yes”への移り変わりが不意に起こります。しかし、 重要な要因で述べられたように、その前から問題の兆候があります。抗議票として考えてみましょう。”CustServ Calls”が 7.00まで増えるにつれ、”no”の予測にますます強く反対し、ついに 重要な要因の値が -0.87 に達すると、予測が”yes”に変わります。その後は抗議は終わり、”CustServ Calls”が予測に同意します。
| CustServ Calls | 予測 | 重要な要因 (CustServ Calls) |
|---|---|---|
| 2.00 | no (98.04%) | 0.0 |
| 3.00 | no (98.04%) | 0.0 |
| 4.00 | no (98.04%) | -0.28 |
| 5.00 | no (98.04%) | -0.55 |
| 6.00 | no (98.04%) | -0.79 |
| 6.50 | no (83.55%) | -0.86 |
| 6.90 | no (54.56%) | -0.87 |
| 7.00 | yes (59.93%) | +0.87 |
| 7.20 | yes (74.42%) | +0.86 |
| 8.00 | yes (74.42%) | +0.75 |
例: Churn Prediction Dataへ続きます。
エクスポート
RapidMiner Goはブラックボックスではありません。各モデルの詳細ビューより、モデルを作成した RapidMiner プロセス のコピーが エクスポート 可能です。また、詳細を調べるためにプロセスをRapidMiner Studioへ インポート することも可能です。そこではプロセスの実行やプロセスの編集など、好きなように変更することが可能です。
