二項分類
評価指標
評価指標を決める前に、いくつか専門用語を紹介します。その後、間違った予測との関係性を決める必要があります — すべての間違った予測が等しく作成されるわけではありません。目的変数が二値しかない場合を想定し、それらを positive と negativeと呼びます。
- positive value – 二つの値のうち、 注目すると選んだ値
- negative value – 二つの値のうち、注目しないと選んだ値
二項分類モデルをテストデータに適用すると、各予測はpositiveかnegativeかになり、既知の値と比較して正しいのか間違っているのかになります。結果をいわゆる confusion matrix(混同行列)で要約します。
| 実際は negative | 実際は positive | |
|---|---|---|
| 予測は negative | TN = true negatives | FN = false negatives |
| 予測は positive | FP = false positives | TP = true positives |
間違った予測には、false positives (FP) と false negatives (FN)の二種類あることに注意してください。どちらも間違っているのですが、二つのうち一つがもう一方より邪魔をすることに気付き、その影響を減らす評価指標を選択するでしょう。
二項分類のすべての評価指標はTP / TN / FP / FNの四つの値の組み合わせを基にしています。RapidMiner Goでは以下の指標を提供します。
| 評価指標 | 数式 | 概要 |
|---|---|---|
| Accuracy(正解率) | (TP + TN) ——— (TP + TN + FP + FN) |
全予測のうち、正しい予測の割合です。false positivesかfalse negatives問題がはっきりしない場合、最も正解率が高いモデルを選びましょう。 |
| Classification Error(分類エラー) | (FP + FN) ——— (TP + TN + FP + FN) |
全予測のうち、間違った予測の割合です(= 1 – Accuracy)。 |
| Precision(適合率) | TP ——— (TP + FP) |
positiveと予測したすべての値のうち、true positivesの割合です。false positivesの数を最小化したい場合、適合率が最も高いモデルを選びましょう。 |
| Recall(再現率) | TP ——— (TP + FN) |
すべてのpositiveのうち、true positivesの割合です。false negativesの数を最小化したい場合、再現率が最も高いモデルを選びましょう。 |
さぁ、これで概要についてお話したのでより具体的に見ていきましょう。
ケース 1: 高価なマーケティングキャンペーン(selective search)
あなたがマーケティングキャンペーンを行っていて、機械学習モデルは積極的に反応する顧客をターゲットにしていると仮定します。顧客との直接的なコミュニケーションを含め、キャンペーンには高い費用がかかるため、あなたは比較的確実に成功させる必要があります。興味をもちそうにない人への連絡に時間とお金を使いたくありません。要するに、false positivesは望ましくないですが、false negativesは許容できます。興味をもちそうな顧客の全員を特定することは重要ではありません。したがって、評価指標に 適合率 を選択します。なぜなら、 適合率 が高いということは、false positivesが少ない — モデルは興味があると示したが実際には興味がない人々の数が少ないということを意味しているためです。
ケース 2: あまり費用のかからないマーケティングキャンペーン(exhaustive search)
機械学習モデルが離反しそうな顧客を発見することを目的にしていると仮定します。これらの顧客が継続するよう説得するには、特別なオファーを必要とします。特別なオファーは、顧客を失うコストと比較すると相対的に安いため、離反する可能性のある顧客のすべてを発見することに重きを置きます。要するに、false negativesは望ましくなく、false positivesは許容できます。少し余分な人々へコンタクトを取ることに害はありません。したがって、評価指標に 再現率 を選択します。なぜなら、 再現率 が高いということは、false negativesが少ない — モデルは離反しないと示したが実際には離反する人々の数が少ないということを意味しているためです。
ケース 3: 不正利用の検知
評価指標と出会った頃は、 適合率 や 再現率よりもなじみやすいため、評価指標に 正解率 を選択したくなるかもしれません。一般的に、 正解率 はデータサイエンスで最も一般的な評価指標ですが、特にpositiveかnegativeかの予測で大きく異なる場合など、常にベストな指標というわけではありません。
不正利用を探していると仮定しましょう。多くの取引は不正利用ではなく、詐欺が起きることは稀です。この例の目的では、10,000の取引のうち1つのみが詐欺である — 0.01%の確率と想定します。ここで、不正取引を予測するとても単純なモデルがあるとします。このモデルは常に「不正ではない!」と予測します。全ての取引のうち99.99%が詐欺ではないため、この単純なモデルは 正解率 が99.99%もあることに注意してください。それにもかかわらず、あなたにとって詐欺を摘発することが重要である場合、モデルは見るべきヒントを何も与えないため、高い 正解率を持っているにもかかわらずこのモデルをすぐに却下するでしょう。
false negativesが欲しくないことは明らかで — 可能なら全ての詐欺を摘発したいです。しかし、無実の顧客を誤って非難したくないため、false positivesについて気を付ける必要があります。ベストなアプローチはおそらく、false negativesを避けるために、モデルに 再現率 を用いることです。しかし、不当な非難をしないために、さらにステップを踏む必要があります。例えば、顧客に連絡をとり、取引は普段にないものなので詳細を聞きたいと伝えることです。正直な顧客なら、あなたが彼を守ろうとしていることに感謝するでしょう。
例: Churn Prediction Data
モデルの比較
RapidMiner Goのステップ5では、 Model Comparison(モデルの比較)を行います。 モデルの比較 は評価テーブルのサマリーを含んでおり、各行はモデルを、各列は評価指標を表示します。ここでは、どのモデルがあなたの要求を最も満たしているかをすばやく確認できます。
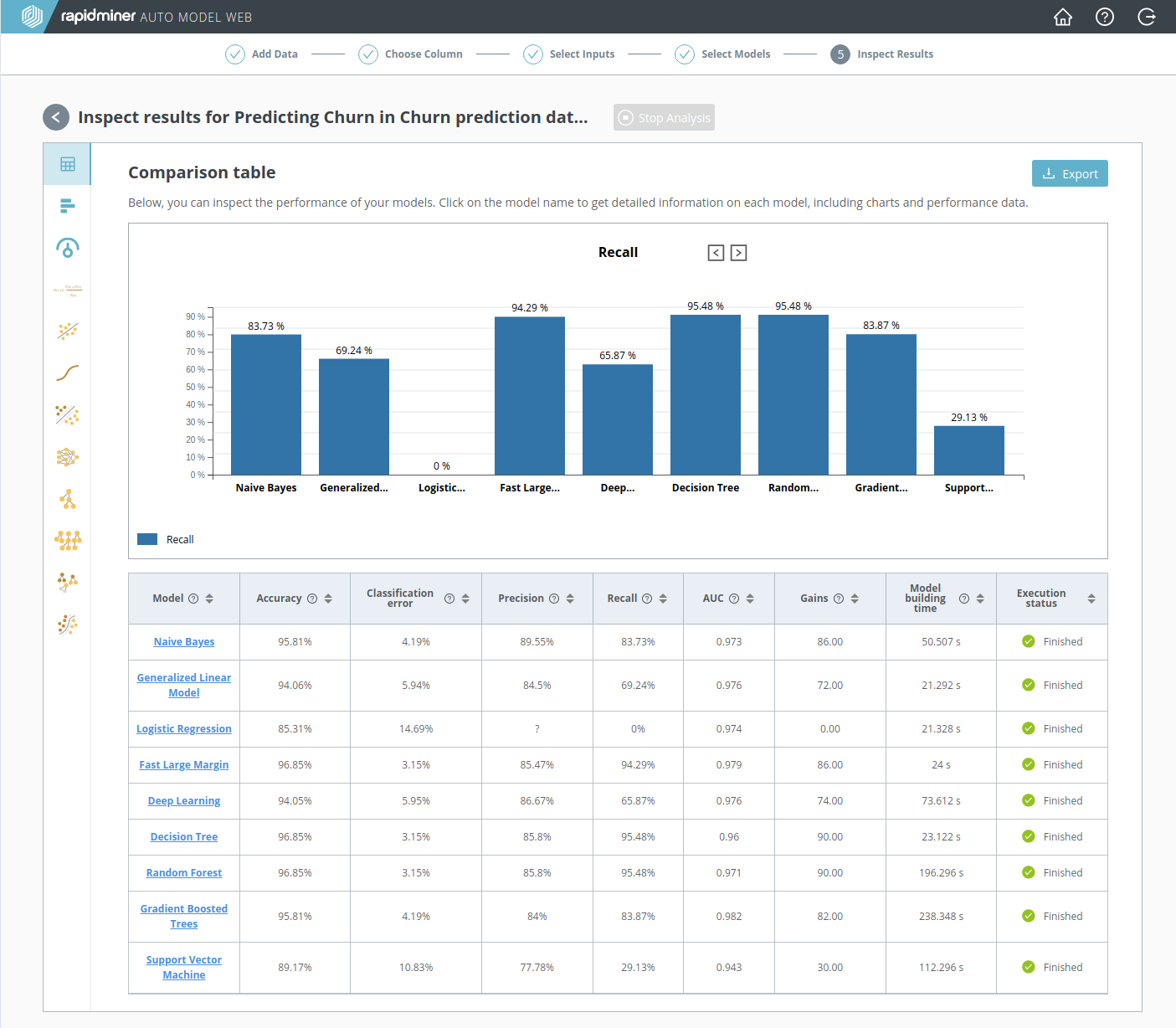
上記の あまり費用のかからないマーケティングキャンペーンで述べられたいくつかの理由で、今回の離反問題には 再現率 が最も良い評価指標です。 再現率 が最も高いモデルは、 Decision Tree (95.48%)と Random Forest (95.48%)の二つでした。
Fast Large Margin の 正解率 と Decision Treeの 正解率 が同じくらいですが、気にしません。今回の目標は離反する可能性があるすべての顧客を見つけることです。それを行う最も良い方法は、たとえ必要以上に多くの人にコンタクトを取ることになったとしても、 再現率が最も高いモデルを選択することです。
Decision Tree(決定木)
Decision Treeをクリックすると、パフォーマンスの統計でみたものより詳細な情報を確認できます。
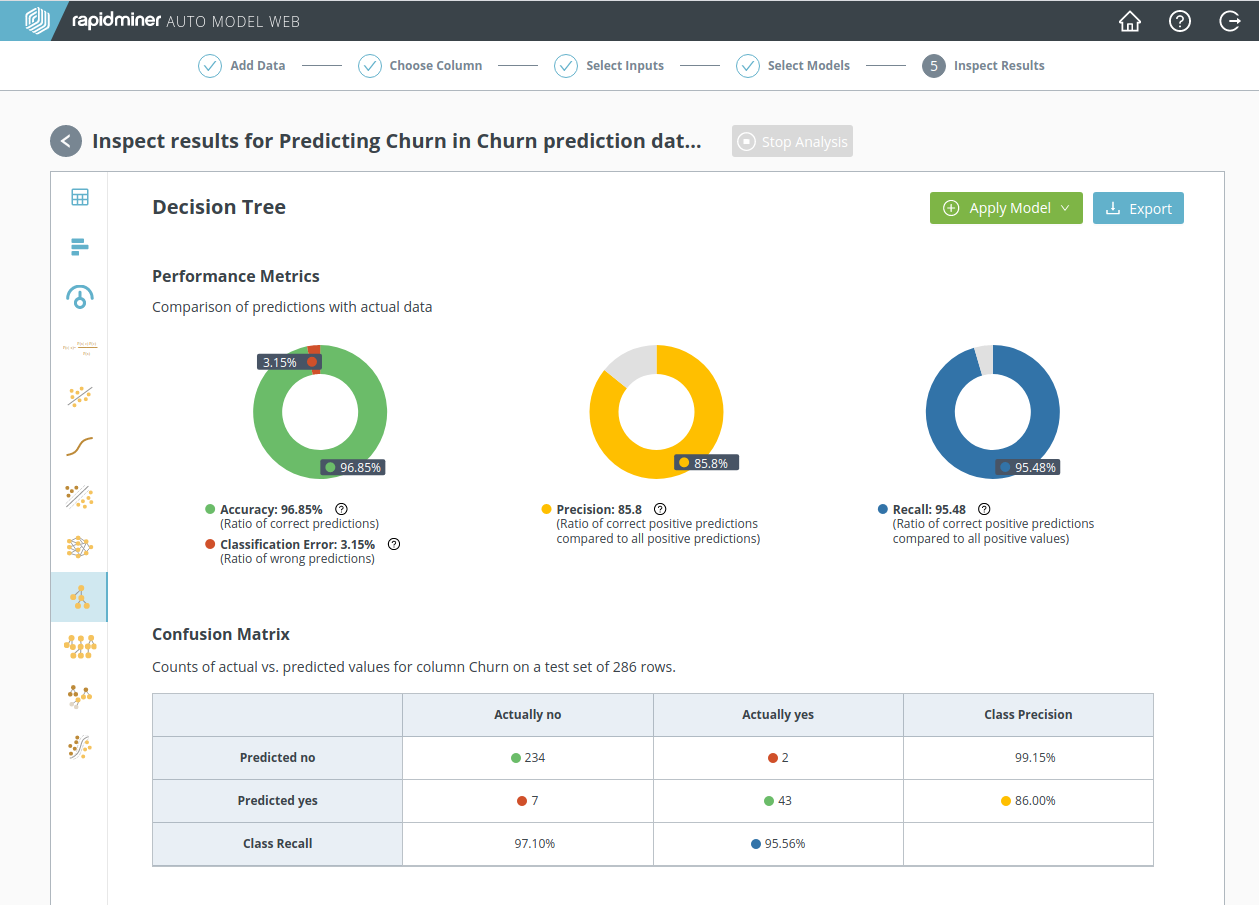
また、ページの下部にとてもシンプルなわかりやすい図があります。

木の枝はそれぞれ、上のデータの条件を示しています。ここでは、顧客のカスタマーサービスへの電話回数が1)6.5以上、2)6.5以下という二つの条件です。つまり、結論は以下のようになります。
- カスタマーサービスへの電話が6.5回より少ない顧客は離反しない(“no”)です。
- カスタマーサービスへの電話が6.5回より多い顧客は離反する可能性が高い(“yes”)です。
すべてのモデルがこのようなシンプルなわけではありません!しかし、 ステップ 3: 入力の選択の終わりでの議論を思い返すと驚きはしないでしょう。今モデルが示したように、離反とカスタマーサービスへの電話回数の間には、強い相関があると言っていました。
再計算: カスタマーサービスへの電話データがない場合
悪いアイデアのように思うかもしれませんが、データから”CustServ Calls”列が除外されていたと少しの間仮定してみましょう。モデルのパフォーマンスに影響はあるでしょうか? このデータがない場合を計算した以下のスクリーンショットを見ると、モデルのパフォーマンスに壊滅的な影響が出ています。 再現率 が50%を超えているモデルがありません。カスタマーサービスへの電話データがなければ、離反する人々を見つけられません。
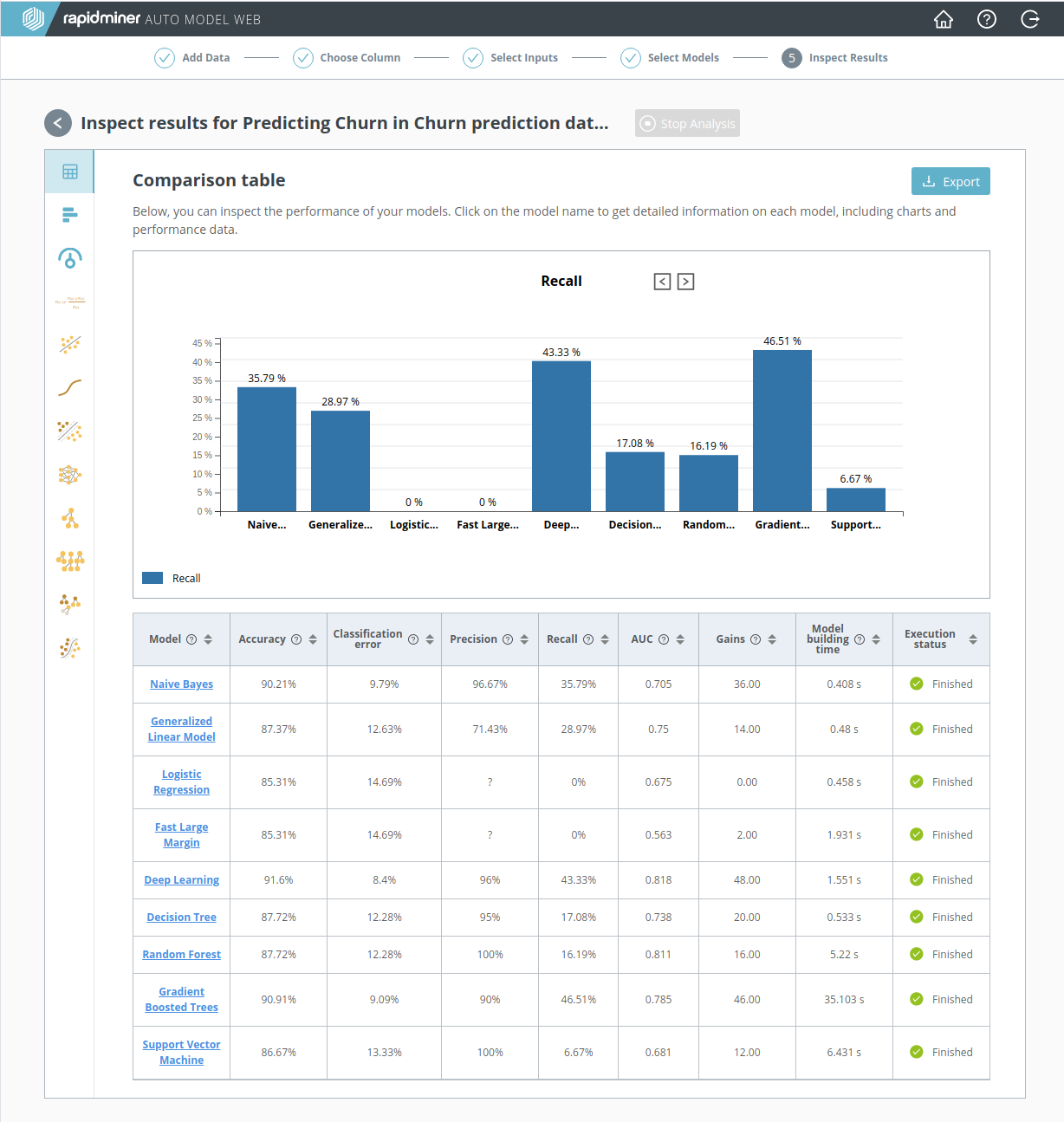
この再計算は失敗ですが、データサイエンス全般に適用される有用なポイントです。関連するデータはアルファとオメガです。かしこいモデルや思いつきの評価指標で、質の低いデータを補うことはできません。良いデータがそろっているか確認しましょう。
まとめ: 成功したのですか?
“CustServ Calls”データを含め、評価指標に 再現率 を用いると優秀なモデルを得ることができました。しかし、このモデルで ブラックボックス予測 を行おうとすると、がっかりする可能性があります。
どうして? モデルが彼を離反者と示すほど顧客がカスタマーサービスへの電話をかけたときでは、遅すぎるためです! 最初の質問をふりかえってみましょう。予測を行うより先に、高い相関のある列のデータへアクセス可能でしょうか? 最初は yesと言いましたが、答えは noに近いように思えます。
ステップを振り返り、ソフトウェアだけでは私たちのすべての問題を解決できないことを認めるときがきました。少しの間データサイエンスについて忘れ、ビジネス的なことに集中しましょう。ここに、必要不可欠な問いがあります。
- どうして顧客はこの電話会社を離れるのか?
- 顧客がとどまるよう説得するのに電話会社は何ができるか?
私たちが知っていることは何でしょうか? モデルのおかげで、カスタマーサービスへ何回も電話をかける顧客は離反する可能性が高いと知ることができました。しかし、電話回数は単なる症状にすぎず、「なぜ顧客が離れるのか?」という問いには答えてくれません。重要な情報はまだ欠損しているのです。
カスタマーサービスへの電話の内容は、今のデータセットには含まれていないことに留意しましょう。苦情のカテゴリ化をするために、カスタマーサービスへ電話のログを取ることを要請する必要があります。新しく改善されたデータセットなら、おそらく「なぜ」への問いに答えられるでしょう。成功か失敗を決めるには早く、しかし、少なくとも私たちの分析は始められます!
