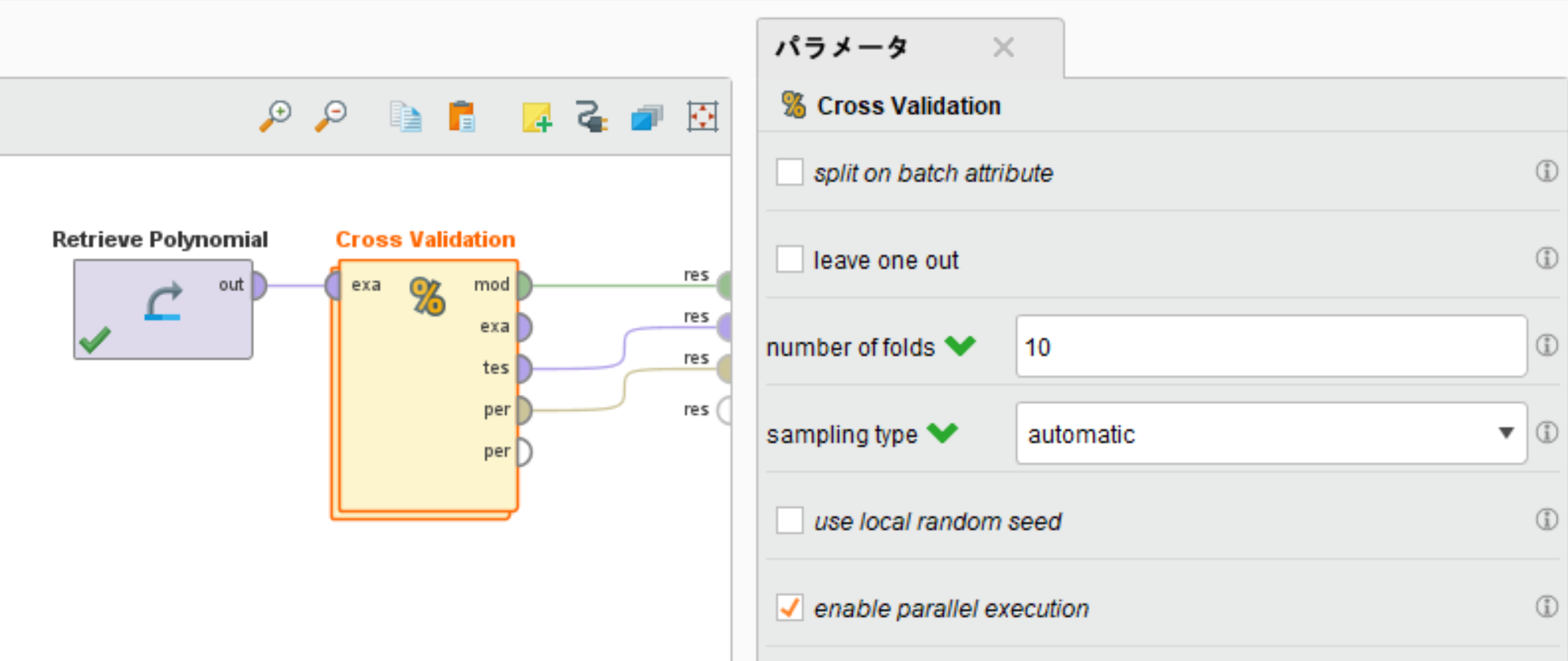
サンプリング方法 (sampling type)
投稿日: 2020年9月1日
OS: Windows 10
バージョン: RapidMiner 9.7
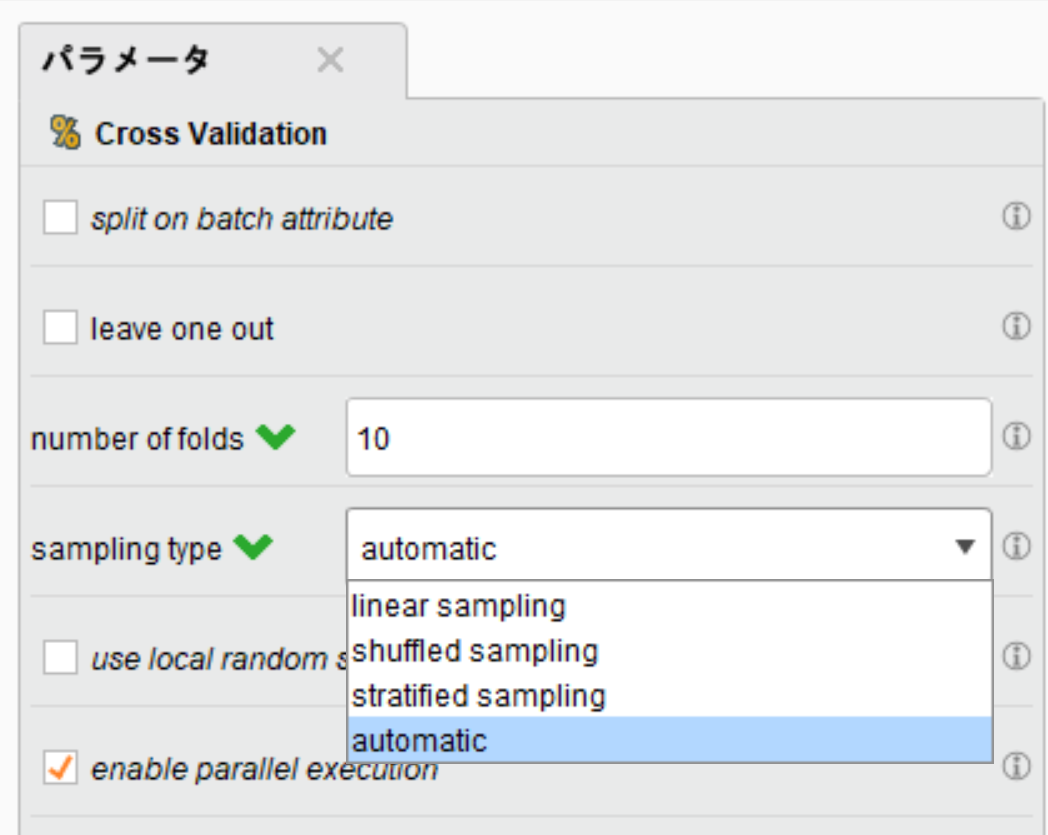
Cross Validationには、以下の4種類のサンプリング方法が用意されています。
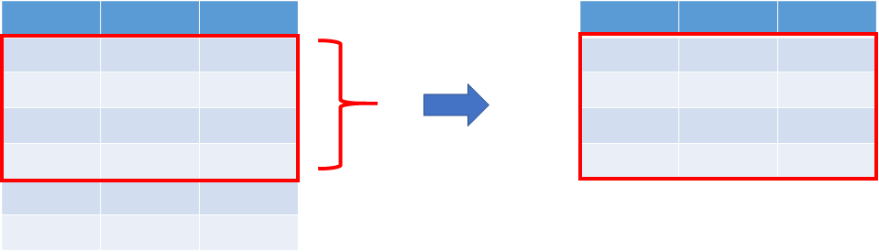
linear_sampling(線形サンプリング):
linear_samplingは、行の順序を変更せずにExampleSetを分割します。
行が連続したサブセットが作成されます。
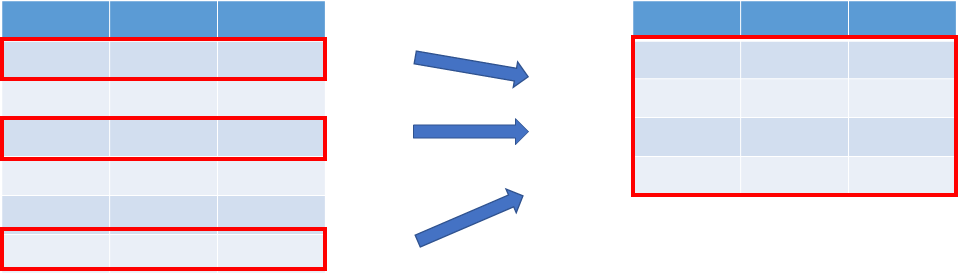
shuffled_sampling(シャッフルサンプリング):
shuffled_samplingは、ExampleSetのランダムなサブセットを構築します。
ランダムに行が選択されます。
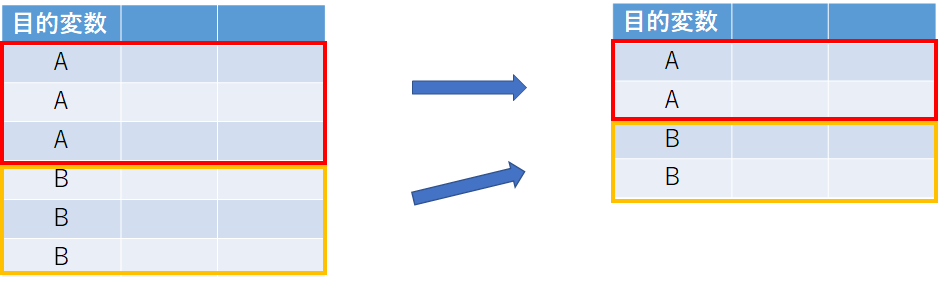
stratified_sampling(層別サンプリング):
stratified_samplingはランダムなサブセットを構築します。
サブセット内のクラス分布(ラベル属性で定義)がExampleSet全体と同じであることを保証します。
たとえば二項分類の場合、層別サンプリングでは、各サブセットにラベル
の2つの値のほぼ同じ割合が含まれるように、ランダムなサブセットが構築されます。
automatic(自動モード):
automaticでは、デフォルトで層別サンプリングが使用されます。
ExampleSetに名義ラベルが含まれていない場合など、適用できない際は
代わりにシャッフルサンプリングが使用されます。
実際に使用したサンプリングの例もご紹介します。以下は、Irisデータセットを用いた際の実行例です。
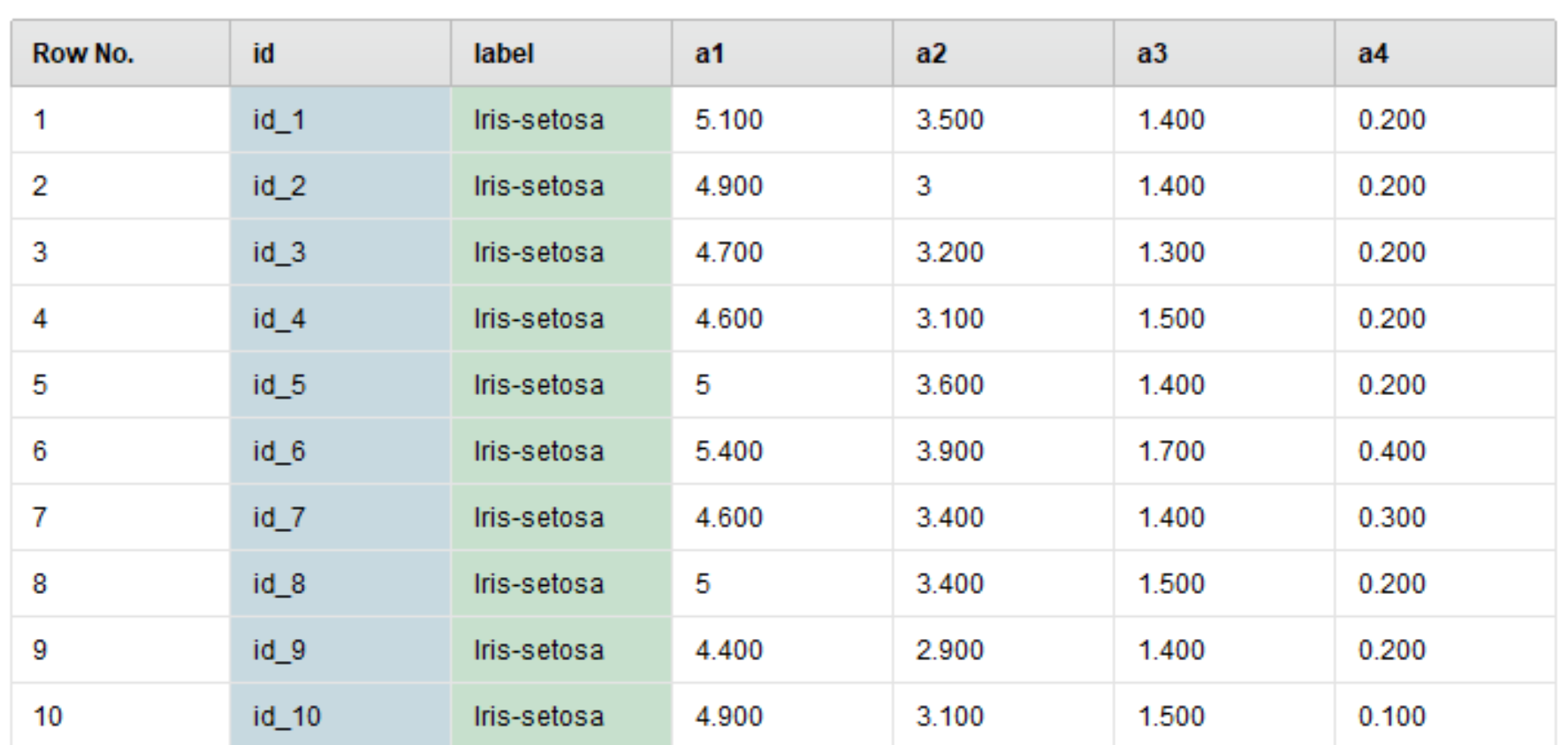
linear_sampling(線形サンプリング)
データセットは、前から順番通りに分割されます。id番号がきれいに並んでいるのが確認できます。
shuffled_sampling(シャッフルサンプリング)
データの順序やクラスの分布に関係なく、ランダムに選ばれているのが確認できます。
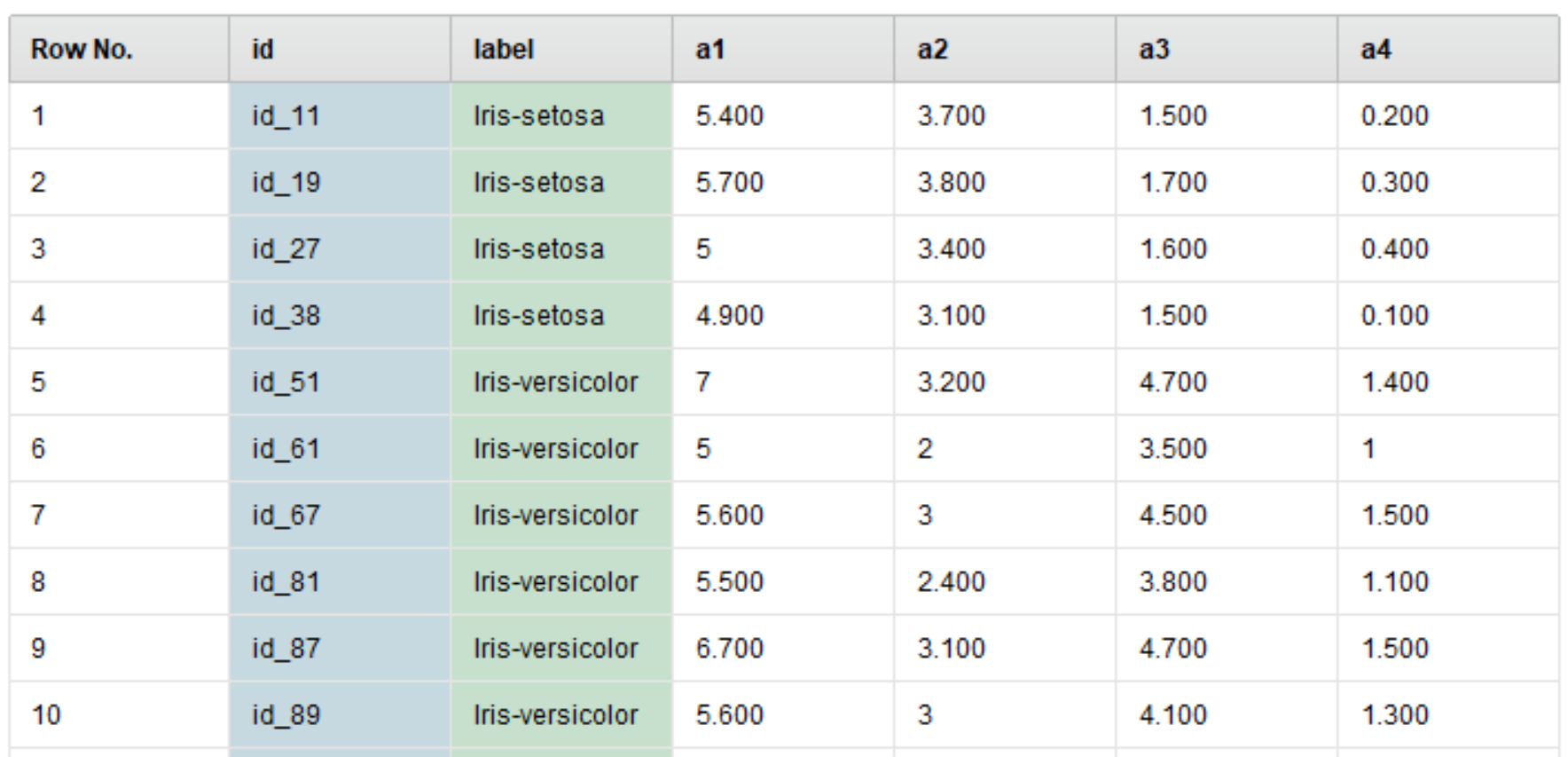
下のstratified_sampling(層別サンプリング)とは違い、クラス分布もランダムに選択されています。そのため、Iris-versicolorの割合が高く選択されています。

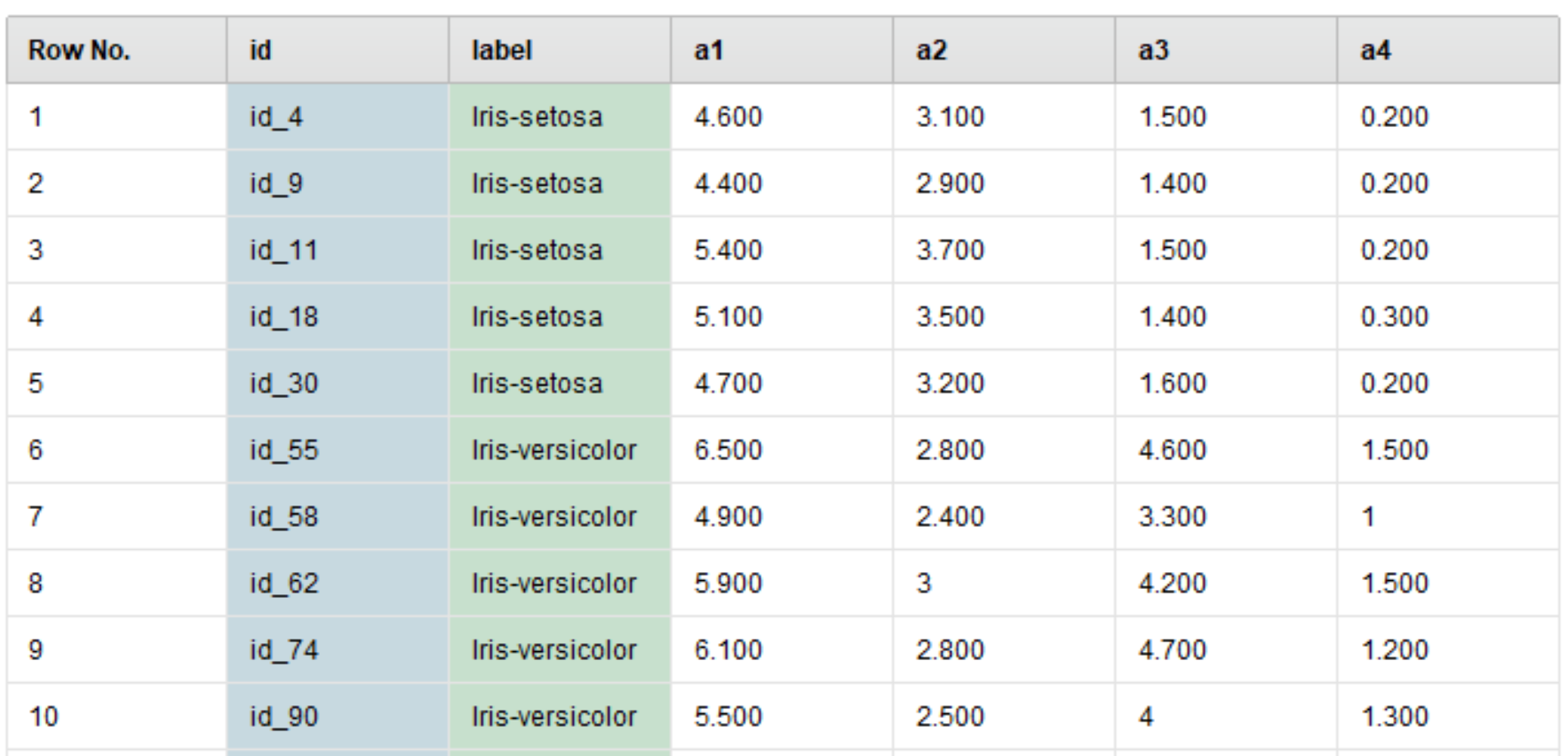
stratified_sampling(層別サンプリング)
一見するとshuffled_sampling(シャッフルサンプリング)と似ていますが、stratified_sampling(層別サンプリング)ではクラスの分布が考慮されています。
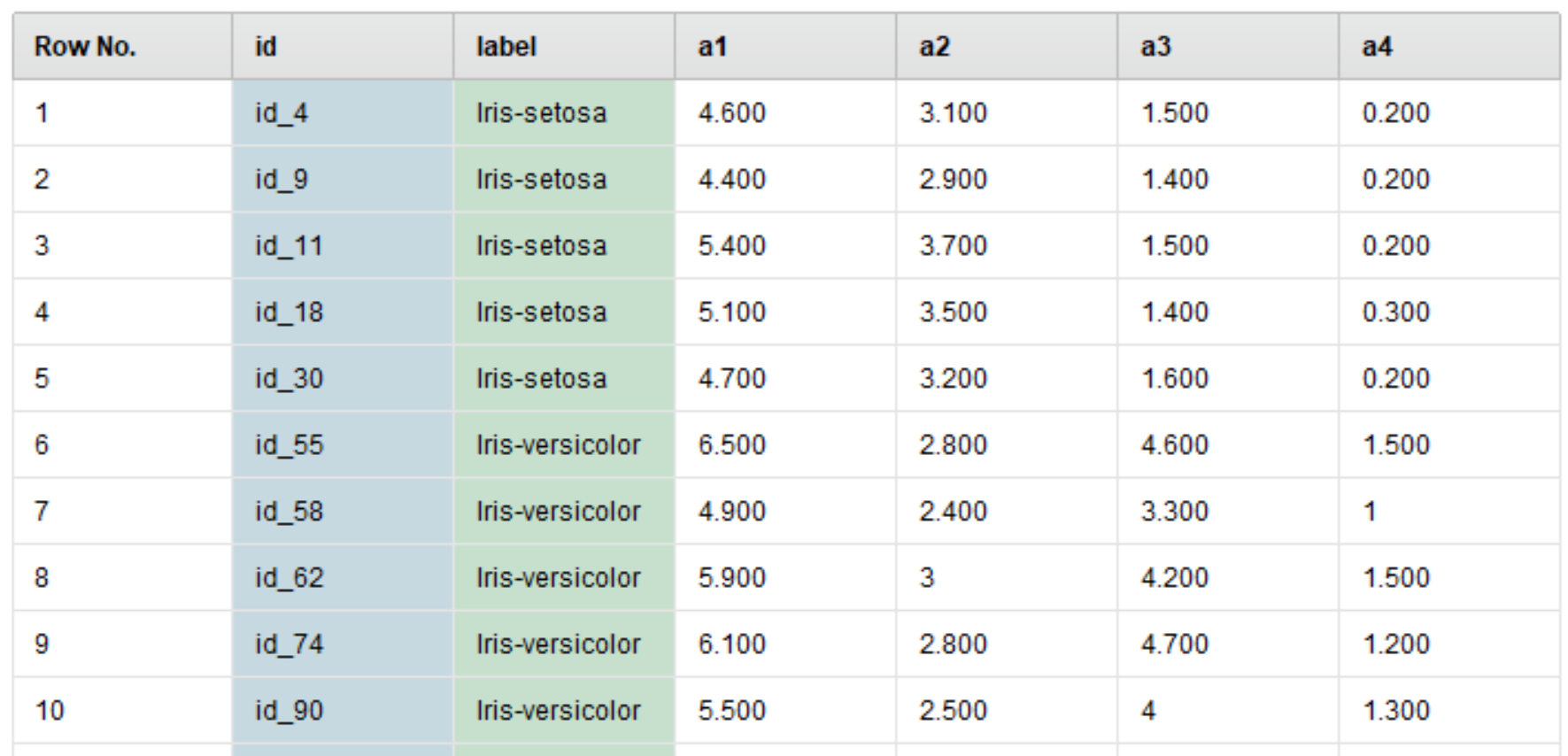
Irisデータは、labelが1:1:1の割合なので、このときの分布も1:1:1になるようにサンプリングが行われます。

automatic(自動モード)
Irisデータは目的変数がカテゴリ値なので、stratified_sampling(層別サンプリング)が適用されます。そのため、結果はstratified_sampling(層別サンプリング)のときと全く同じになります。
automatic(自動モード)の便利な点は、目的変数によってサンプリング方法を選択する必要がない点です。目的変数が数値のときにstratified_sampling(層別サンプリング)を使用すると、数値では割合毎に分けられないためエラーが出ます。
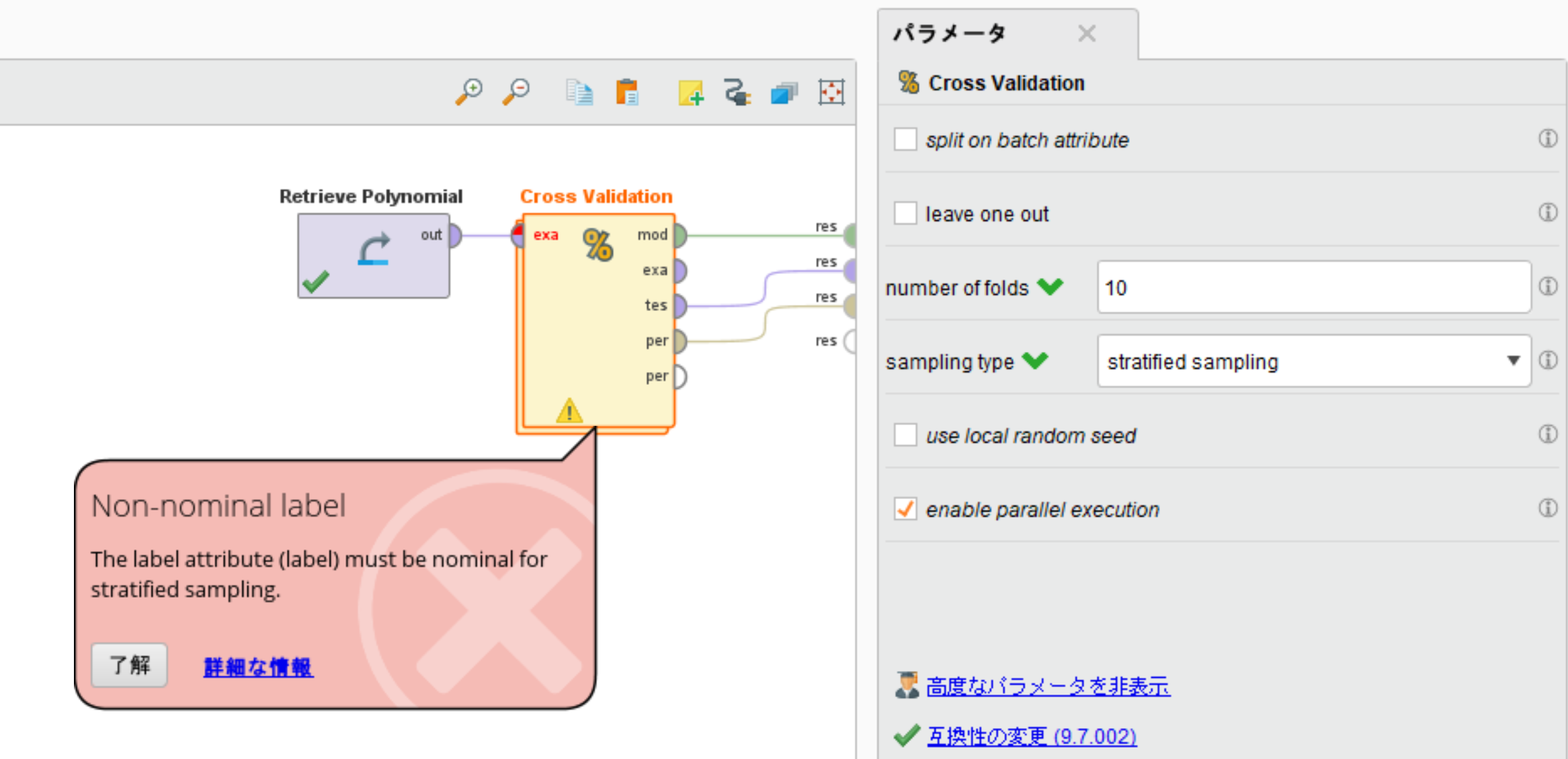
このようなエラーを避けるため、デフォルトではautomatic(自動モード)が選択されています。目的変数が数値のときは、自動でshuffled_sampling(シャッフルサンプリング)が行われます。