欠損値の補完を機械学習で行う方法
投稿日 : 2022年10月12日
OS : MacOS 12.5 Monterey
バージョン : RapidMiner Studio 9.10.011
データの欠損値に対して、RapidMinerはReplace Missing Valueなどのオペレータを用意しております。これを使用することで欠損値の補完処理を行うことが出来ます。ですが、その方法としては平均等の値を入れる程度であり、「真値」またはそれに近い値を入れることはこのオペレータでは難しいです。
そこで、今回は欠損していないデータに対して機械学習を使用し、欠損したデータにこれを適用することでより高精度に欠損値を埋めていきたいと思います。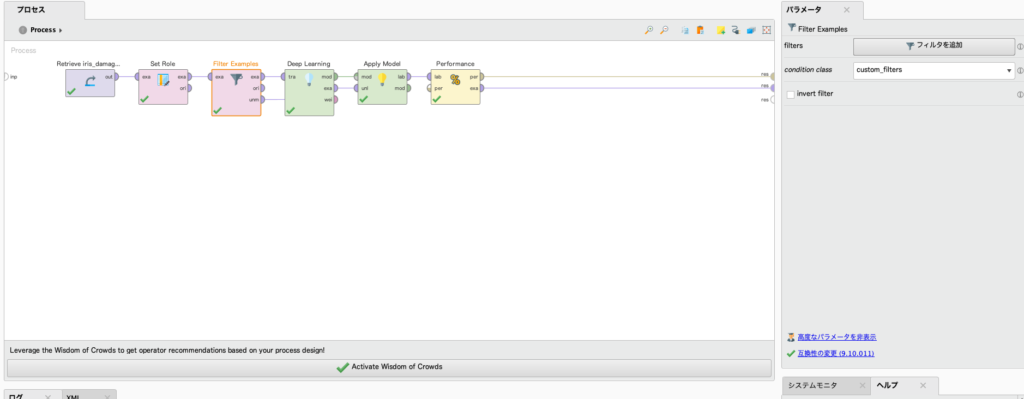
今回の解説では、入力データにIrisを使用します。解説のため、事前にa4のデータの1割を意図的に欠損させております。
まずは予測したい項目をSet Roleで指定します。今回はa4の欠損値を予測したいのでa4にlabel属性を付与します。
次に元のデータから欠損値をより分けます。
Filter Examplesを使用することで、条件を指定してデータを取り出すことができます。
今回の場合、filtersから、「a4」「is missing」を指定することでa4の欠損値の項目を取り出すことができます。
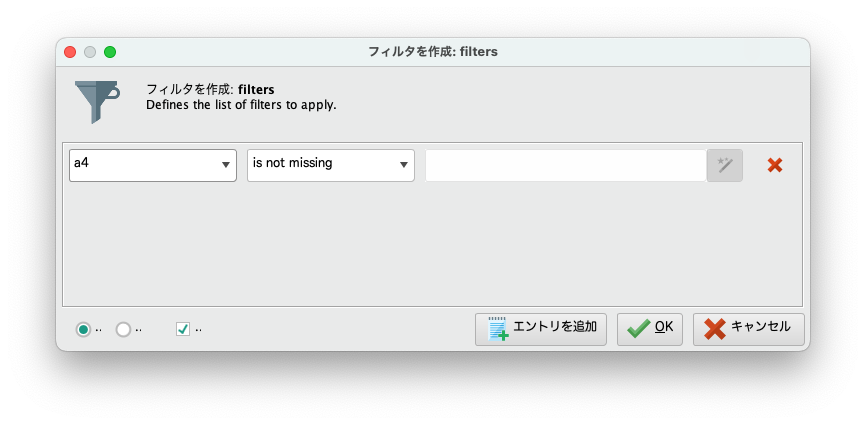
この時、オペレータの出力ポートのunmからは、先ほど指定した条件に当てはまらないデータを出力できるので、こちらから正常なデータを取り出すことができます。今回は正常なデータを機械学習の学習データに、欠損値のデータを学習モデルを使用して予測するため、exaとunmの出力を使用していきます。
では、正しいデータを使用して学習をおこなっていきます。
今回は機械学習のDeep Learningオペレータを使用して予測を行っていきます。この時にDeep Learningのtraに接続するのは、Filter Examplesのexaになります。
Deep Learningオペレータの各種パラメータを調整することでおそらくより高精度な値を予測できますが、今回はデフォルトの値で進めていきます。
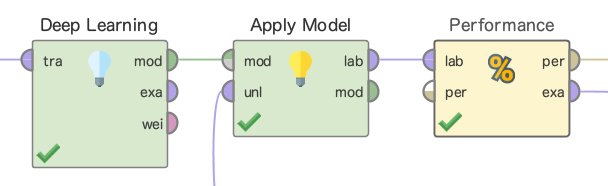
この後はApply Modelと、Performance(Regression)を画像のように接続していきます。またApply Modelで欠損値の予測を行うため、Filter Examplesのunmから対象のデータをApply Modelのunlに接続しましょう。
以上の操作で、a4の欠損値を予測することができます。比較のため、欠損前のデータと平均で補完したデータ、機械学習で補完した結果は以下のようになります。
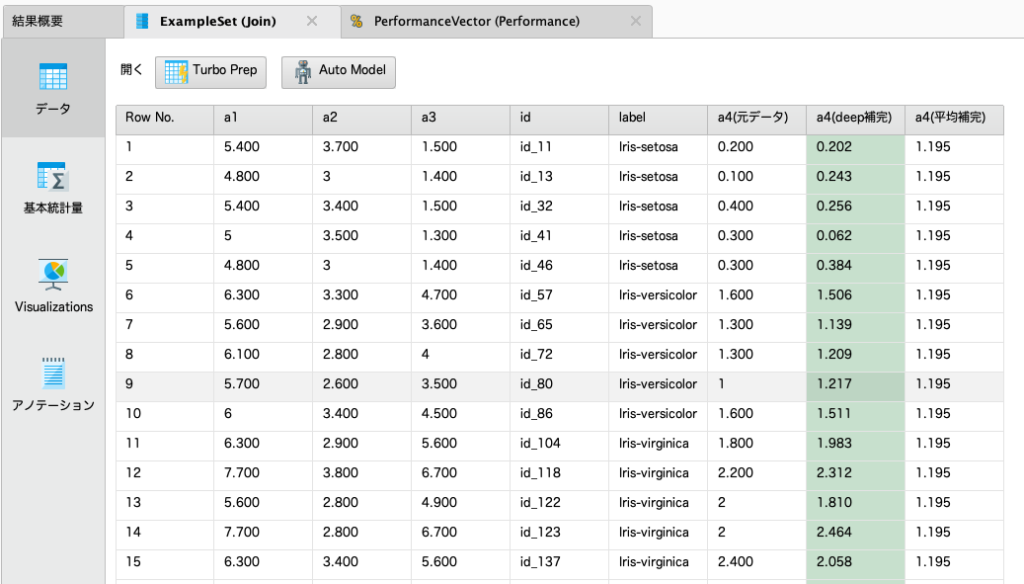
この画像のそれぞれのa4の予測を見る限り、元データに近い値を与えられているのは機械学習を使用した方のように見えます。
欠損値を平均で補完したデータと機械学習で補完したデータを比較するため、a1~a3と、a4のそれぞれ補完したデータを使用して、Irisの花の推定を行い、精度を確認しましたところ、平均値で補完したデータより機械学習で補完したデータの方が精度が良いことが確認できました。
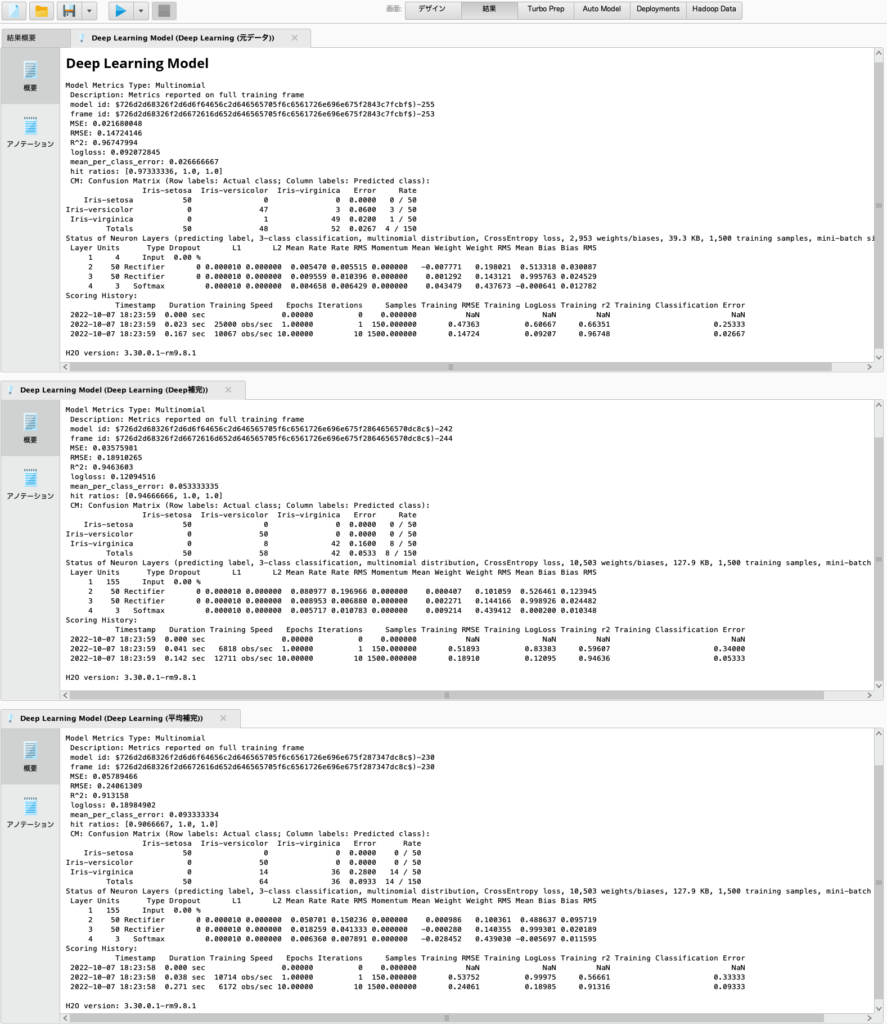
データによってはこの通りにならない場合も十分に考えられ、既存のオペレータを使用するよりは少々手間がかかりますが、より良い精度で補完を行うことができる可能性を有していると言えるでしょう。欠損値の補完を行う際には一度ご検討いただければと思います。
