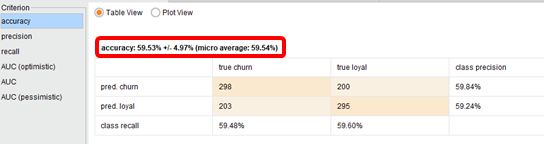
accuracyとmicro averageの違い
(回答)
cross validate(交差検証)を行い、accuracyがそれぞれ出たaccuracyの平均、micro averageが全データで行った場合のaccuracyになります。
例を使ってご説明いたします。
RapidMinerのサンプルデータの中に、Sonarというデータセットがあります。Sonarデータセットはソナー信号とそれが岩か地雷かを計測したものです。そのため、目的変数(label)がrockもしくはmineになっています。
このSonarデータセットを読み込み、k-NNで交差検証を行います。
このとき、同じ乱数を使用できるように、交差検証のuse local random seedにチェックを入れておきます。
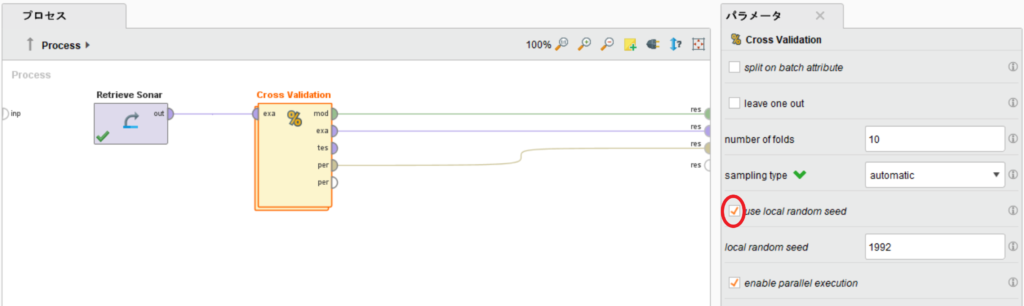
そして、交差検証の中は以下のように接続してください。モデルの作成にはk-NNを用い、パラメータをk=1にし、weighted voteのチェックを外してください。
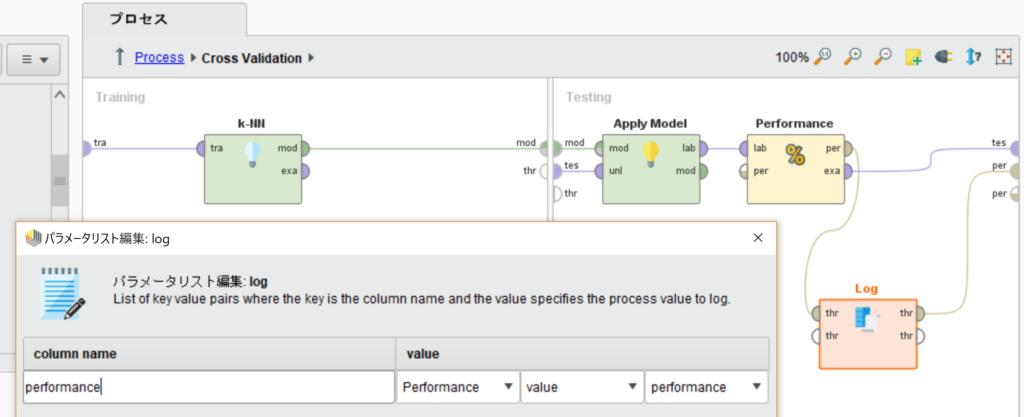
また、今回交差検証の10回のそれぞれのaccuracyを取りたいのでLogオペレータをPerformanceの後ろに繋ぎ、column nameに”performance”と入力し、valueを左から順にPerformance、value、performanceに設定してください。
こうして結果を確認すると、以下のような混同行列が得られます。

この混同行列に対して、正確度を求めます。
計算式は以下のようになります。
(74(true Rock)+98(true Mine)) / 208(データ数) = 82.69%
こうして出た数値がmicro averageの数値です。

では、accuracy 82.62%がどうやって出されたかと言うと、先ほどログを取ったので、Logの結果を見てください。
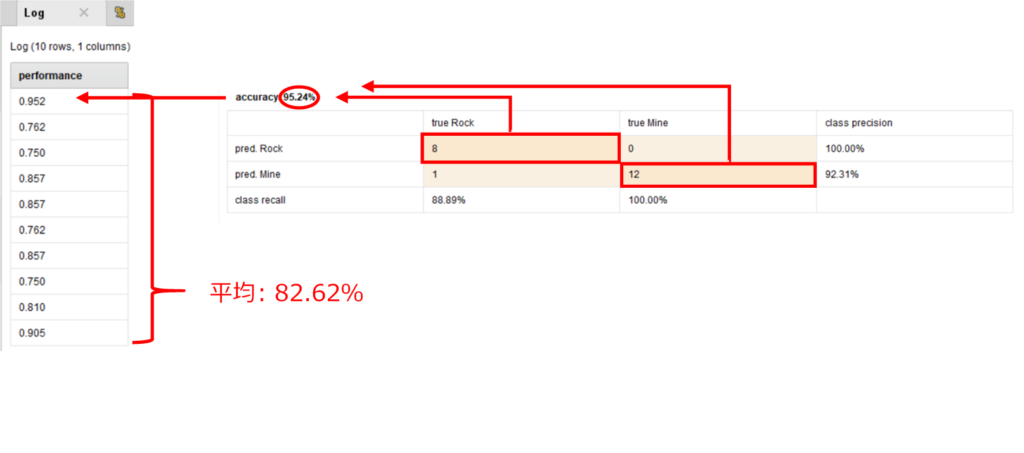
このLogの一つ一つの数値について、データ数約20の混同行列が得られます。データ数20のデータでモデルの検証をし、その正確度をとります。
それを10回繰り返し、その平均を取ったものが最初に出てきたaccuracyです。
なお、データ数が20なのは、交差検証のパラメータnumber of foldsが10なので10分割されるためです。
<結論>
つまり、交差検証で出るaccuracyは交差検証の一回ずつの正確度の平均です。
そしてmicro averageは交差検証の中で十回検証した結果を合計してできた混合行列の正確度を取ったものです。
