RapidMinerでHDFS/Hiveを使用する方法
投稿日: 2022年8月3日
OS: CentOS 7
バージョン: RapidMiner 9.9
前提条件
- 以下のサービスが起動している。
- HDFS
- Hive
- Hue
- Zookeeper
- Radoopエクステンションがインストールされており、接続テストが成功し、HDFSのデータ操作が可能。
下記もご参考ください。- 【ナレッジベース】RapidMiner Radoop Installation
- 【Radoop基本操作の動画】Radoop 接続編
Hive経由でHDFSにデータを出力
まず分析に使用するデータをHDFSにアップロードします。
- Radoop Nestを以下のように配置します。
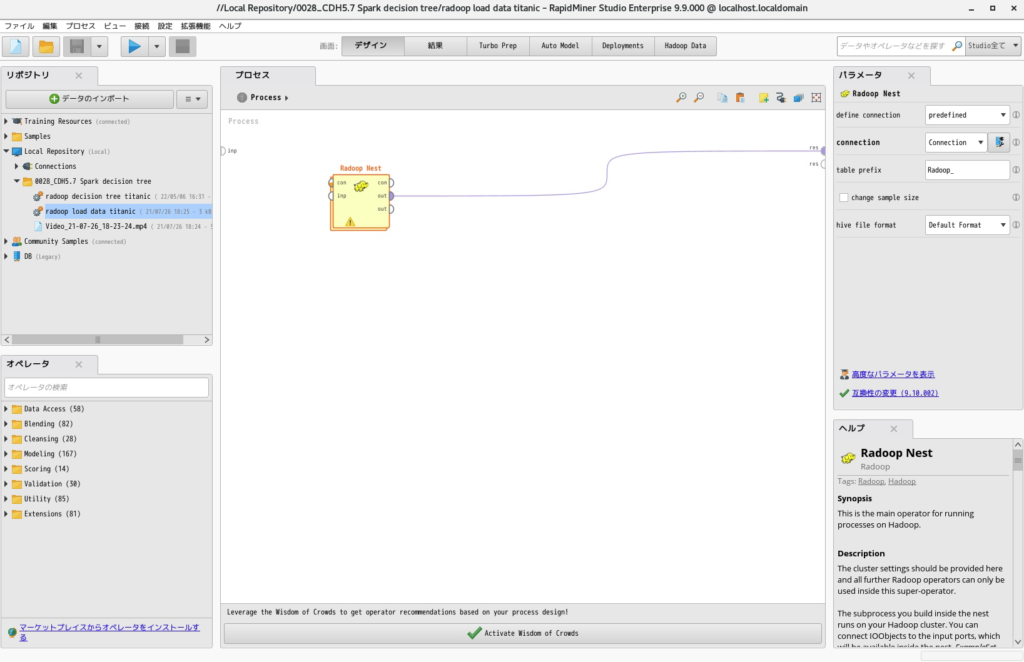
- Radoop Nestをダブルクリックで開き、タイタニックのデータとStoreオペレータを以下のように配置します。ここでは「tablename」を「titanic」としています。
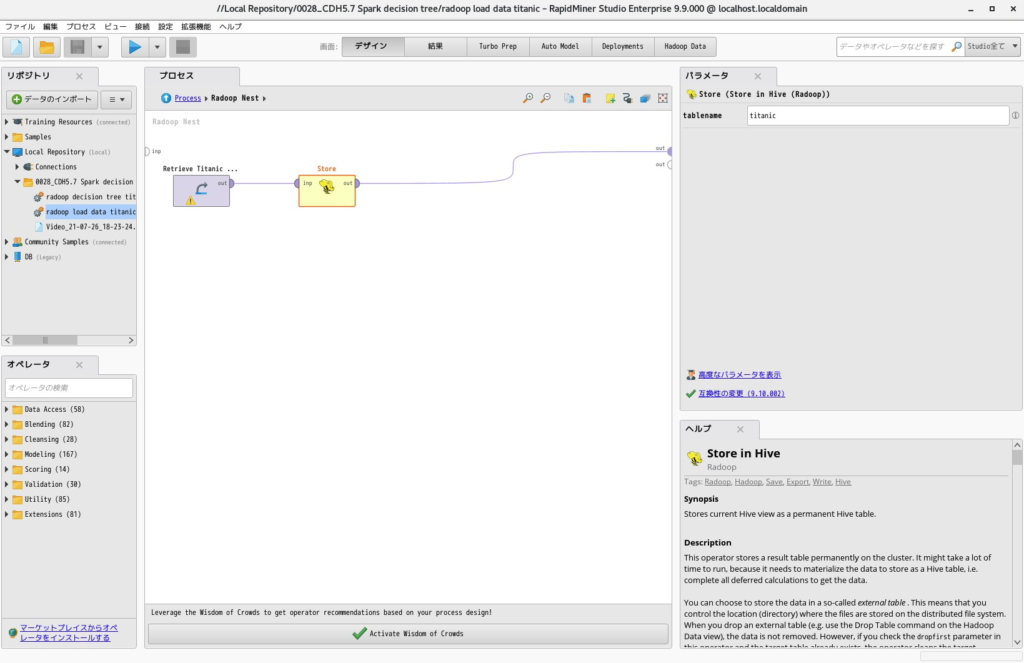
- 実行すると以下の結果が得られます。
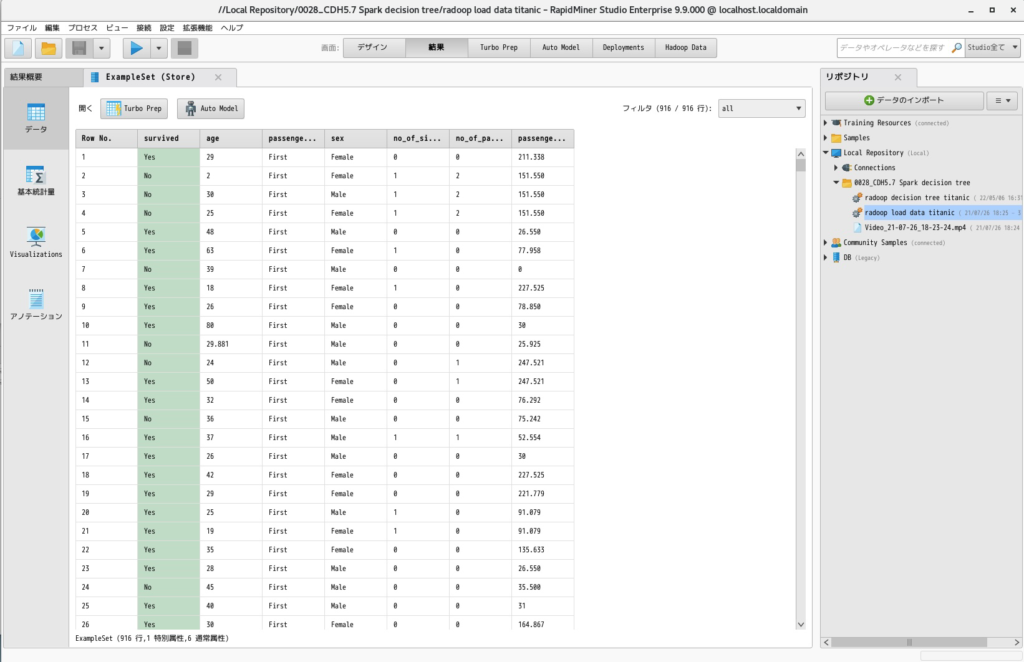
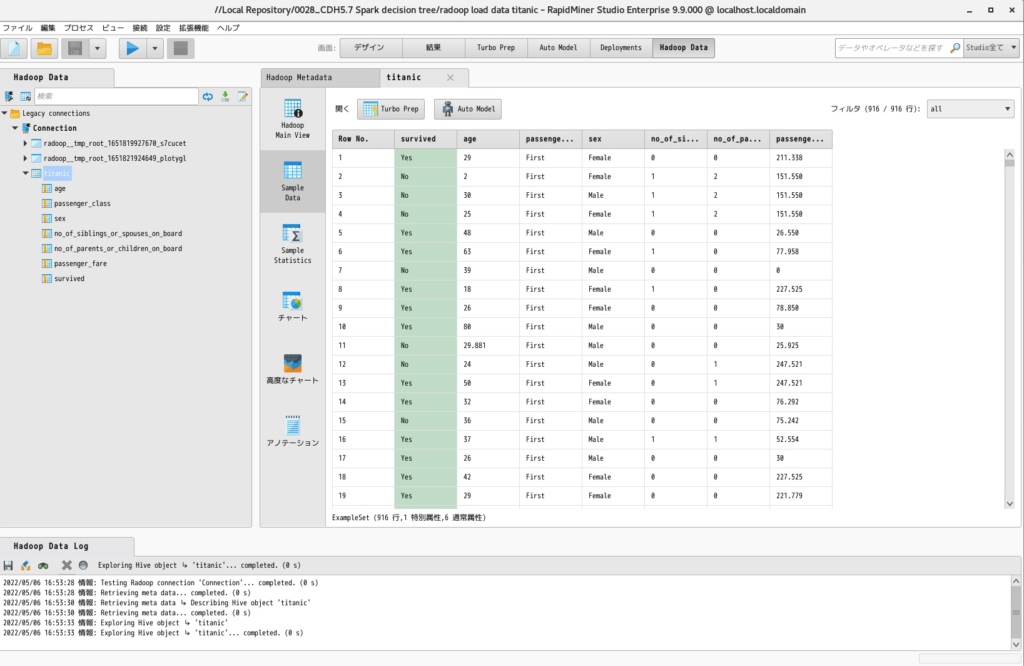
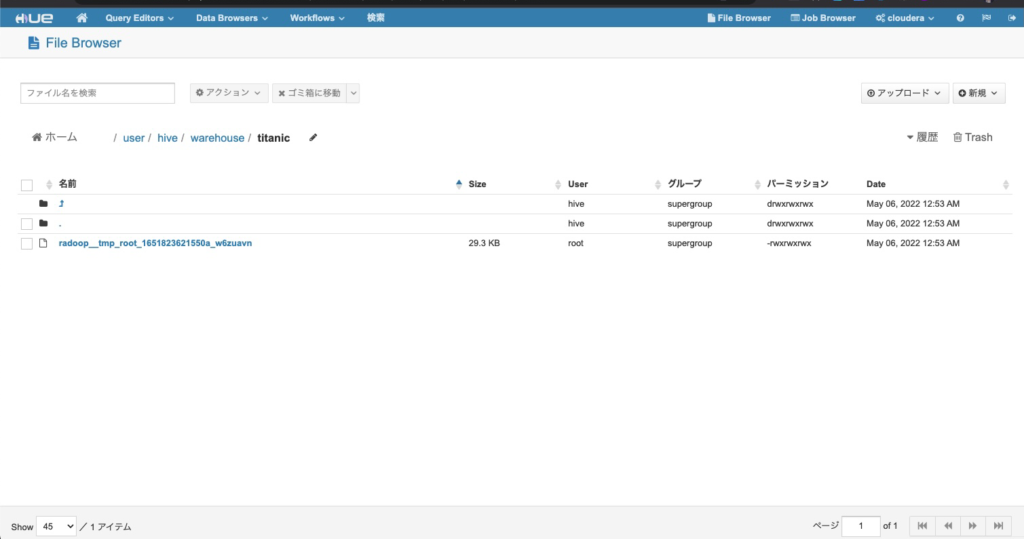
- 「Radoop Data」をクリックするとHDFSにアップロードされたデータが確認できます。
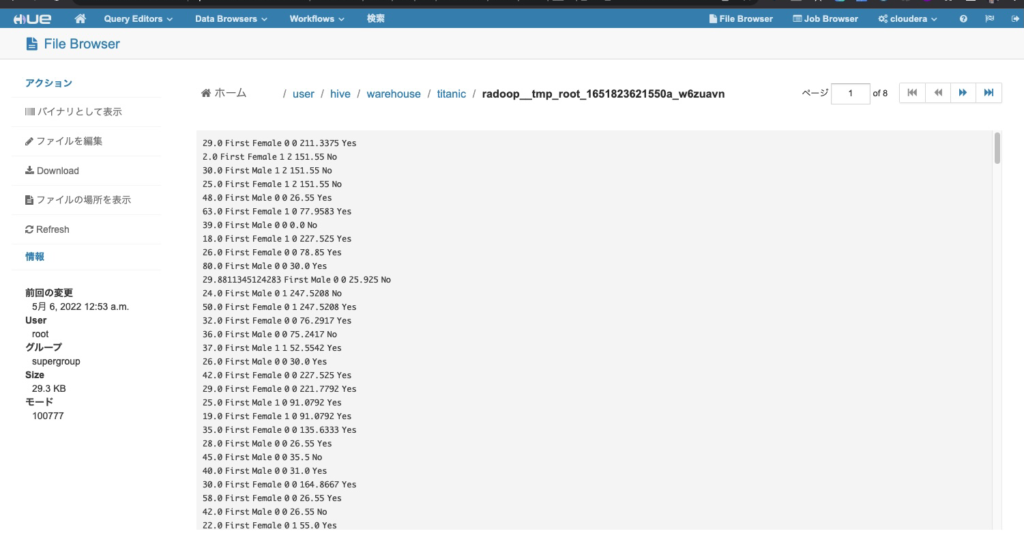
- 念の為、Hueでも確認してみると想定通りデータがアップロードされています。
Hive経由でHDFSからデータを入力
次に先ほどのHDFSの出力したデータを入力してみます。
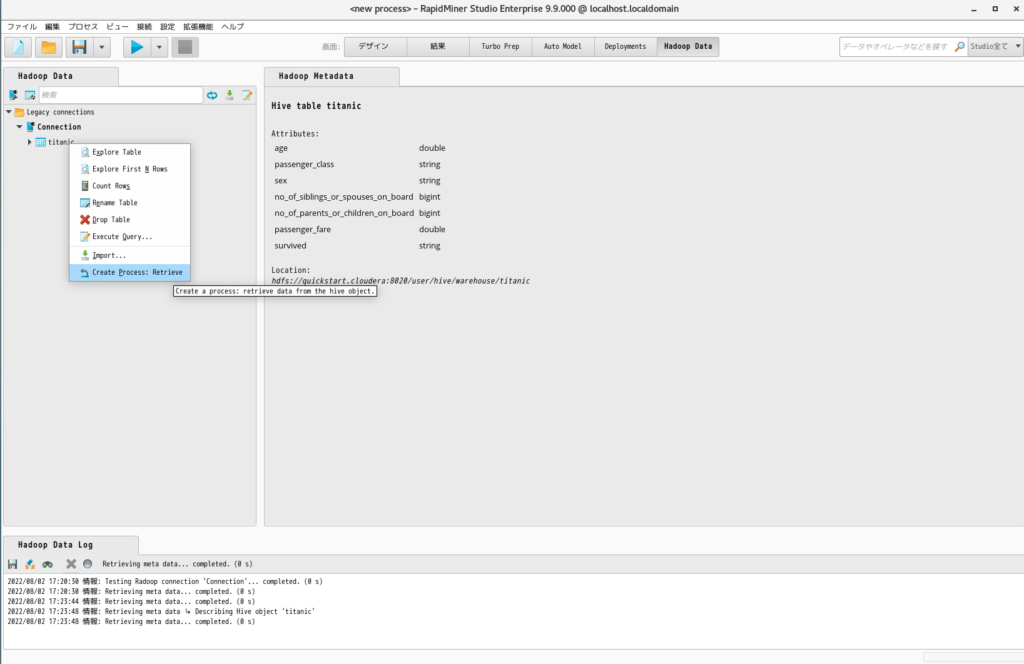
- taitanicのテーブルを右クリックし、「Create Process: Retrieve」をクリックします。
- HDFSからデータ取得に必要なオペレーターが自動的にプロセスに配置されます。
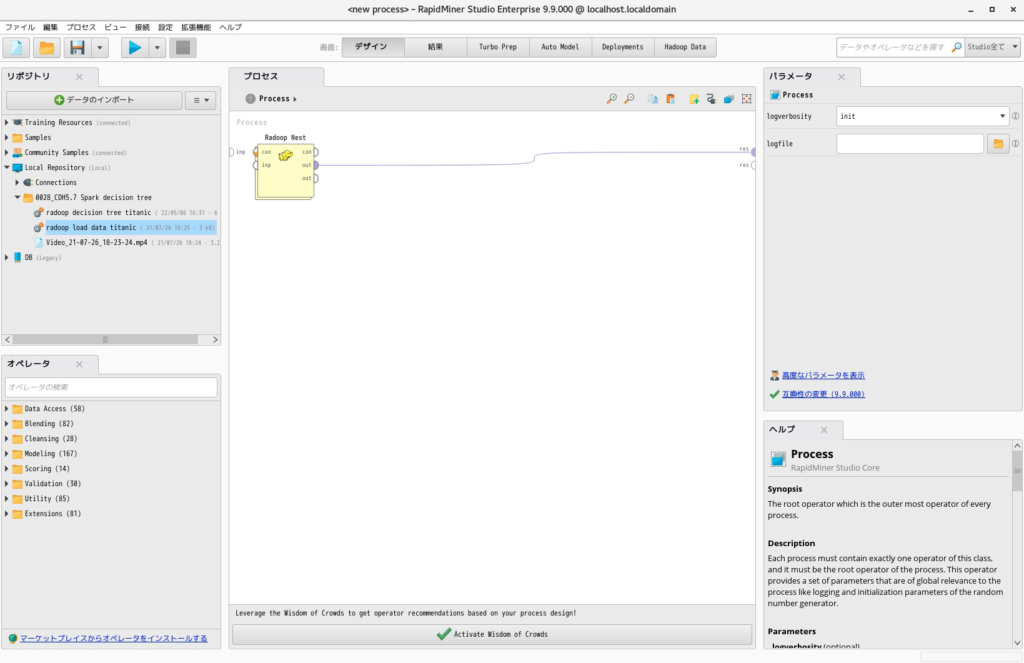
- Radoop Nestの中にはRetrieve from Hiveオペレータが配置されています。
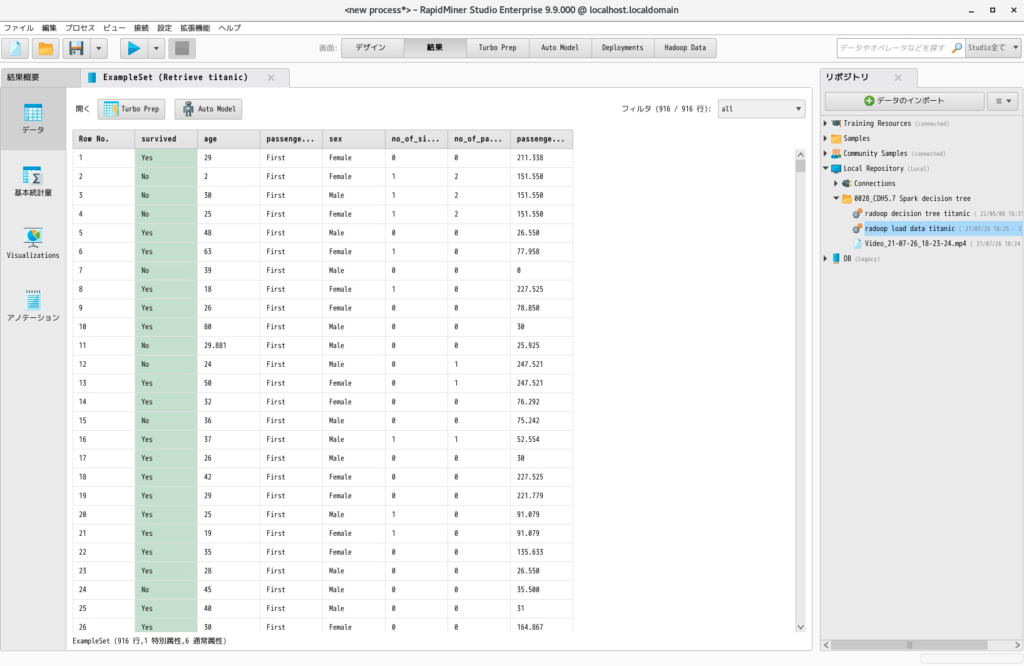
- 実行すると以下のような結果が出力されます。
参考動画:Radoop データ操作編(Hive)
