RapidMiner StandPy
RapidMiner StandPyは、RapidMiner AI Hubのオプションモジュールで、レイテンシを低減するためにPythonインタプリタの常時稼働のサポートを行います。RapidMinerのプロセスにPythonコードを埋め込む際に、Python環境の代替として使用することができるモジュールです。
デフォルトでは、RapidMinerはRapidMinerプロセスに組み込まれたPythonオペレータごとに新しいPythonインタプリタを起動します。ほとんどの場合、これによりスクリプトの完全な分離を保証し、Pythonインタプリタの初期化にかかる100-1000msのオーバーヘッドは通常無視できるため、このような挙動は望ましいです。
ですが例外が一つあります。負荷が小さいプロセスをWebサービスとしてデプロイする場合、このオーバーヘッドを許容できなくなる可能性が高くなります。StandPyは、このような例外に対応できるよう設計されており、Pythonスクリプト実行における代替を提供します。
セットアップドキュメントは、以下で構成されています。
前提条件
RapidMiner StandPyを使用するには、RapidMiner AI Hub 9.9.2以降が必要です。特に、RapidMiner StandPyをRapidMiner Serverのスタンドアロン版やRapidMiner Studioと一緒に使用することはできません。
また、RapidMiner StandPyには、Python Scripting extension 9.9.2以降が必要です。この拡張機能は、RapidMiner StudioとRapidMiner AI Hubの両方にインストールする必要があります(ただし、前述の前提条件により自動的にクリアします)。
アーキテクチャの概要
以下のRapidMiner AI Hubの簡易アーキテクチャ図は、2つのRapidMiner StandPyコンテナが既存のインフラにどのように統合されるかを示しています。最低でもコンテナを1つデプロイする必要があります。追加されたコンポーネントはすべて、分離した内部ネットワークの一部であることに注意してください。
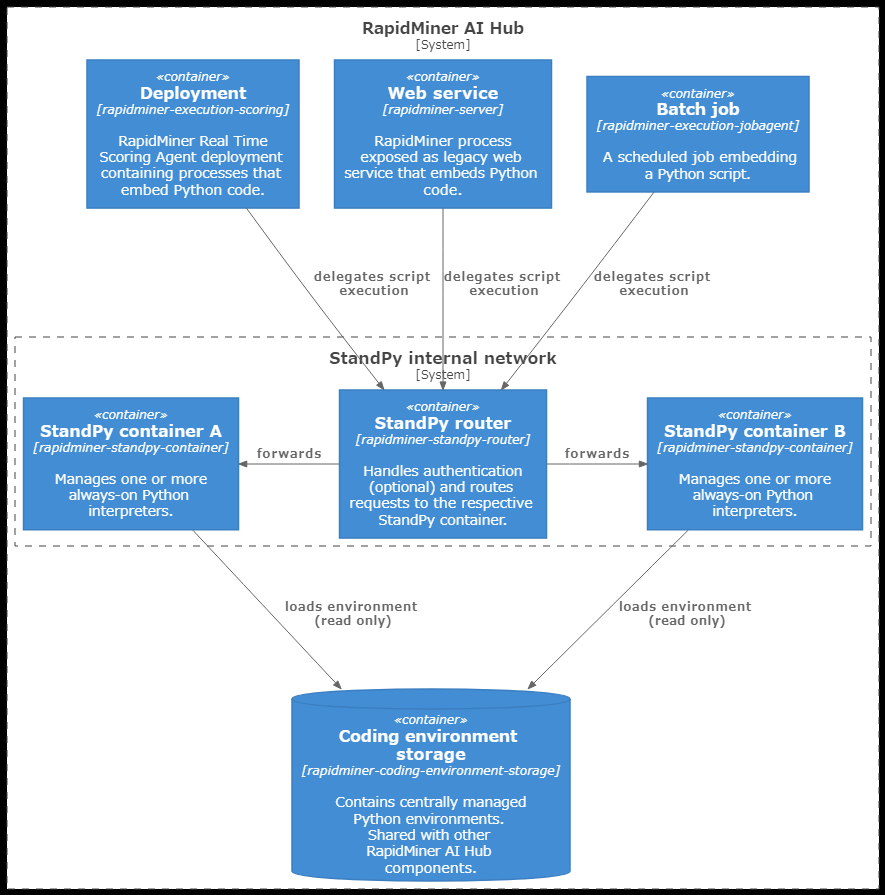
スクリプト実行のためのすべての受信リクエストは、RapidMiner StandPy routerコンポーネントを経由します。
- 一つのルーターで複数のコンテナと使用することができます。
- ルーターは他のRapidMiner AI Hubコンポーネントからアクセス可能ですが、RapidMiner AI Hubの外部からはアクセスできません。
- このコンポーネントを使用して、追加の認証を設定することができます(オプション)。
- ルーター自体がPythonコードを実行するわけではありません。
実際のスクリプトの実行は、RapidMiner StandPy containerインスタンスのうちの1つで行われます。
- 各コンテナは、コーディング環境ストレージから1つのPython環境を有効にします。
- このコンポーネントは、1つ以上の常時稼働するPythonインタプリタを管理します。
- コンテナやPythonインタプリタは、メインのRapidMiner AI Hubネットワークにはアクセスしません。
- コンテナは、Pythonインタプリタのステートを除いてステートレスであり、すなわちコンテナはサブミットされたPythonスクリプトを永続化しません。
このセットアップは、スクリプトの実行がプラットフォームの他の部分から分離するよう設計されています。特に、認証や他のコンポーネントとの通信は、Pythonスクリプトを実行するコンテナとは分かれたコンテナで実装されています。
しかし、このセットアップでは、同じコンテナ上で複数のスクリプトが実行されることによって生じる副作用からの保護は限定的なものになります。コンテナは別のネームスペースでスクリプトを実行しますが、グローバル設定の変更はその後の実行に影響します。副作用が懸念される場合は、例えば本番環境用に別のコンテナを使用するなど、複数のRapidMiner StandPyコンテナを使用することを検討してください。
RapidMiner AI Hubのセットアップ
ここでは、RapidMinerが提供するテンプレートを使用して、Docker ComposeベースのRapidMiner AI Hubのデプロイメントを使用していると想定します。他のコンテナランタイムを使用している場合は、弊社サポートまでご連絡ください。
上図のように、2つのRapidMiner StandPyコンテナ(1つはテスト用、もう1つは本番環境用)の構成を作成していきます。どちらのコンテナもexample-project-environmentという同じPython環境を使用します。このセクションでは、以下の手順を説明します。
- Pythonの環境依存のチェック
- 内部ネットワークの設定
- ルーターの設定
- 2つのコンテナの設定
RapidMiner StandPyには環境依存があり、以下のモジュールの最新版を含む必要があります。定義済みの環境を拡張する場合は、モジュールはすでにインストールされている可能性が高いです。
dependencies:
- numpy
- pandas
- fs
- flask
- libiconv
- uwsgi
これで、RapidMiner AI Hub用のdocker-compose.ymlファイルを編集できるようになります。RapidMiner StandPyの内部ネットワークを作成するために、networksブロックの最後に1行追加する必要があります。追加されると、次のようになります。
networks:
rm-platform-int-net:
rm-idp-db-net:
rm-server-db-net:
rm-coding-environment-storage-net:
jupyterhub-user-net:
name: jupyterhub-user-net-${JUPYTER_STACK_NAME}
rm-go-int-net:
rm-go-proxy-net:
# Separate network for RapidMiner StandPy
rm-standpy-int-net:
これで、ルーターをサービスブロックに追加することができます。
rm-standpy-router-svc:
image: ${REGISTRY}rapidminer-standpy-router:1.0
hostname: rm-standpy-router-svc
restart: always
environment:
# List engines in format ENGINE__HOST:
- ENGINE_EXAMPLE_TESTING_HOST=standpy-container-testing
- ENGINE_EXAMPLE_PRODUCTION_HOST=standpy-container-production
# Optional security tokens in format ENGINE__TOKEN:
- ENGINE_EXAMPLE_PRODUCTION_TOKEN=secrettoken
# Limit the request size (no limit by default):
# REQUEST_SIZE_LIMIT=1m
networks:
rm-platform-int-net:
aliases:
- standpy-router
rm-standpy-int-net:
aliases:
- standpy-router
上記の設定では、example_testingとexample_productionという2つのコンテナに対してルーティングを設定し、後者をセキュリティトークンで保護しています。プラットフォームのネットワークrm-platform-int-netと、前のステップで作成したRapidMiner StandPy用の独立したネットワークrm-standpy-int-netの両方にサービスを追加していることに注意してください。これは、ルーターが2つのネットワーク間のゲートウェイとして機能するためです。
次に、上記で参照した2つのコンテナを追加します。
rm-standpy-container-testing-svc:
image: ${REGISTRY}rapidminer-standpy-container:1.0
read_only: true
tmpfs:
- /tmp
hostname: rm-standpy-container-testing-svc
restart: always
environment:
- CONDA_ENV=example-project-environment
# Optional number of worker processes (default 1):
- WORKERS=1
# Optional request timeout in seconds (default 30):
- TIMEOUT=45
# Restarts workers after the given number of requests. If not set,
# automatic restarts are disabled.
- MAX_REQUESTS=100
volumes:
- rm-coding-shared-vol:/opt/coding-shared:ro
networks:
rm-standpy-int-net:
aliases:
- standpy-container-testing
rm-standpy-container-production-svc:
image: ${REGISTRY}rapidminer-standpy-container:${RM_VERSION}
read_only: true
tmpfs:
- /tmp
hostname: rm-standpy-container-production-svc
restart: always
environment:
- CONDA_ENV=example-project-environment
# Optional number of worker processes (default 1):
- WORKERS=4
# Optional request timeout in seconds (default 30):
- TIMEOUT=5
# Restarts workers after the given number of requests. If not set,
# automatic restarts are disabled.
# - MAX_REQUESTS=100
volumes:
- rm-coding-shared-vol:/opt/coding-shared:ro
networks:
rm-standpy-int-net:
aliases:
- standpy-container-production
2つのサービス構成は、その名前と環境変数以外は同じです。
テスト用コンテナでは、スループットをほとんど考慮する必要がないため、1つのワーカーだけ使用しています。タイムアウトは、時間がかかるスクリプトをテストできるように、比較的余裕を持って設定されています。そして最後に、もはや使用されていないモジュールのインポートのような、使われていないリソースを解放するために、100リクエスト毎にシングルワーカーを強制的に再起動させます。
本番環境のコンテナでは、スループットを高めるために4つのワーカーを使用しています。スクリプトのテスト結果から、すべてのスクリプトが1秒以内に完了し、メモリが高まることはないと分かっているものと仮定します。このため、積極的なタイムアウトを設定して誤りのあるリクエストを早期に中止し、ワーカーの定期的な再起動を無効にしてレイテンシの急増を防ぐことができます。
RapidMinerプロセスとの接続
Python Scripting Extensionは、リモートPythonエンジン(RapidMiner StandPyコンテナ)を管理する用の接続フレームワークを使用します。前節の本番環境のコンテナへの接続を設定するために、Remote Python Engineタイプの接続を新規に作成する必要があります。通常通り、接続自体に任意の名前をつけることができます。
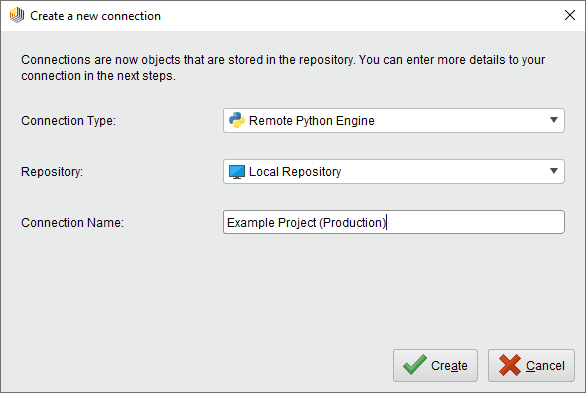
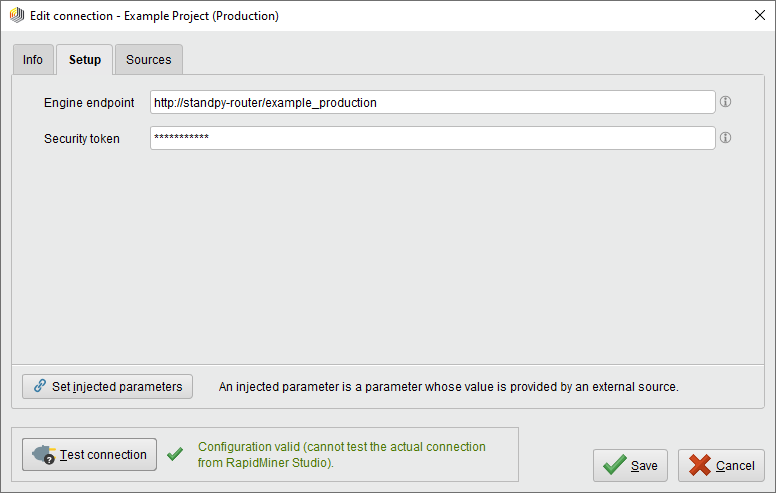
設定は、エンジンのエンドポイントとオプションのセキュリティトークンの、2つのパラメータのみで構成されています。
エンドポイントは常にRapidMiner StandPy routerを指すURLで、パスを使用して使用するコンテナを指定します。前節でルーターサービスを定義した際、ネットワークセクションでエイリアスをstandpy-routerとしました。さらに、2つのコンテナにexample_testingとexample_productionという名前を付けました。したがって、テスト用と本番用のコンテナは、それぞれ http://standpy-router/example_testingとhttp://standpy-router/example_productionというエンドポイントになります。
(ある場合は、)セキュリティトークンは、単純にルーターサービス内で指定されたトークンです。
RapidMiner StandPyはRapidMiner AI Hub内からしか利用できないため、検証はできますが、RapidMiner Studio内から接続のテストにはなっていません。
この設定は、Remote Python Contextオペレータで使用することができます。このオペレータはシンプルなネスト構造を取るオペレータで、RapidMiner StandPyコンテナへの接続を入力とし、組み込まれたすべてのPythonオペレータの環境設定を上書きします。
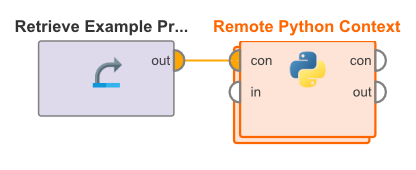
オペレータにはenableというパラメータがあり、環境のオーバーライドを有効または無効にします。こうすることで、プロセス構造を変更することなく、Studioでプロセスをテストすることができます。
3つのオペレータを用いた最小限のプロセスをスケジューリングすることで、StandPyの接続が期待通りに動作しているかをテストすることができます。単純に、上記のRemote Python Context内にExecute Pythonオペレータを追加するだけです。例えば、次のスクリプトは、Python環境のプレフィックスを表示します。
import sys
def rm_main():
print('StandPy testing:')
print(sys.prefix)
プレフィックスには、StandPyに指定されたPython環境名が付いているはずです。この例では、/opt/coding-shared/envs/example-project-environmentと表示され、example-project-environmentの部分は前のセクションで選択した名前です。接続に失敗した場合は、print文やエラーメッセージがプロセスログに表示されます。
制限事項
RapidMiner StandPyは他のPython環境とほとんど代替可能ですが、そのWebサービス指向のアーキテクチャにはいくつかの制限があります。長時間実行するスクリプトには適さず、またファイルを扱うときはスクリプトが異なる挙動を取る場合があります。
StandPyコンテナで起動したスクリプトを手動で中断する方法がないため、長時間実行するスクリプトは適していません。コンテナは、スクリプトが完了するか、指定されたタイムアウトに達するまで待機します。後者の場合、コンテナはPythonインタプリタ全体を強制的に再起動します。
理論的には、タイムアウトを非常に大きな値に設定することができます。しかし、その場合、誤りのあるジョブが長時間StandPyコンテナをブロックしてしまうリスクがあります。ですが、実際のところはStandPyを使って長時間実行するスクリプトを実行する必要はありません。もしその場合は、デフォルトのスクリプト実行のオーバーヘッドは無視できるほどだからです。
RapidMiner StandPyはファイル入力をサポートしていますが、ローカルファイルシステムへのアクセスはできません。ファイル入力は、TextIO型のファイルライクなオブジェクトとして渡されます。したがって、ほとんどのスクリプトは、ローカルで実行した場合と同じように動作するはずです。
しかし、入力ファイルをBinaryIOとして開き直す必要がある場合もあります。このようなユースケースをサポートするために、入力は一時的にインメモリファイルシステムに保存され、入力を閉じたり再度開いたりすることができます。さらに、StandPyはスクリプトの名前空間にある組み込みのopen関数を、インメモリファイルシステム上で動作する、互換性のある関数に置き換えています。例えば、以下のスクリプトは、StandPy上で期待通りに実行されます。
import joblib
def rm_main(input):
# StandPy uses random strings for input file names:
file_name = input.name
# The open() function is replaced with a function aware of StandPy's
# in-memory file system, thus opening the file as binary will work:
with open(file_name, 'rb') as fp:
model = joblib.load(fp)
# ...
しかしながら、ファイル名を別のモジュールで定義された関数に渡すことは失敗しがちです。
import joblib
def rm_main(input):
# StandPy uses random strings for input file names:
file_name = input.name
# This call will most likely fail, since the joblib module will try to open
# the file using the builtin open() function:
model = joblib.load(file_name)
# ...
したがって、常にトップレベルでファイルを開き、スクリプトの外で定義された関数には、ファイル名ではなくファイルハンドルを渡すことを強くお勧めします。
トラブルシューティング
トラブルシューティングの良い出発点は、Pythonコードを埋め込んでいるRapidMinerプロセスのプロセスログです。Python Scriptingエクステンションは、以下の情報をログに記録します。
- リモートエンジンに到達できない場合は、接続エラーになります。
- スクリプトの実行に失敗した場合は、Pythonのトレースバックになります。例えば、インポートの欠落は以下のように表示されます。
INFO: Started operator : Execute Python May 17, 2021 7:33:25 AM com.rapidminer.extension.pythonscripting.operator.scripting.python.RemoteScriptRunner handleErrors SEVERE: Failed to parse the Python script Traceback (most recent call last): Script, line 3, in ModuleNotFoundError: No module named 'missing' - ユーザースクリプトからのprint文は、以下のように表示されます。
INFO: Started operator : Execute Python May 17, 2021 7:40:02 AM com.rapidminer.extension.pythonscripting.operator.scripting.python.RemoteScriptRunner run INFO: A print statement from the Python script.print文は、スクリプトの実行でエラーが発生しなかった場合にのみログに記録されることに注意してください。
詳細な調査には、RapidMiner AI Hubへの管理者権限が必要です。以下のリソースは、問題を特定するのに役立つかもしれません。
- すべてのStandPyコンテナは、/infoエンドポイントを実装しています。上記の例では、AI Hubのネットワーク内からhttp://standpy-router/example_prodcution/infoを問い合わせると、次のように応答します。
{ "environment": "example-project-environment", "max_requests": null, "timeout": 5, "version": "1.0.0", "worker_uptime": 762, "workers": 4 } - rm-standpy-router-svcサービスのログには、このサービスを経由したすべてのリクエストがリストアップされます。特に、コンテナに到達できない場合やエラーコードによるレスポンスなど、失敗したリクエストを記録します。
- RapidMiner AI Hubは、外部リクエストをStandPyに転送するように構成できます。ただし、そのような構成は、保護されていないPythonコンテナが公開される恐れがあるため、本番環境では許可しないでください。転送を有効にするには、.envファイル内で以下のブロックを検索します。
# To enable standpy external access use this value as STANDPY_BACKEND # STANDPY_BACKEND=http://rm-standpy-router-svc/ STANDPY_BACKEND=http://standpy-is-not-enabled-by-default STANDPY_URL_SUFFIX=/standpyコメント内が表示されるように変更します。
# To enable standpy external access use this value as STANDPY_BACKEND STANDPY_BACKEND=http://rm-standpy-router-svc/ # STANDPY_BACKEND=http://standpy-is-not-enabled-by-default STANDPY_URL_SUFFIX=/standpy変更を適用するには、rm-proxy-svcサービスを再起動する必要があります。その後、RapidMiner Studioをhttp://<aihub-host>/standpy/<standpy-container-name>に接続すると、ローカルブラウザからhttp://<aihub-host>/standpy/<standpy-container-name>/infoへクエリができます。
