カスタムオペレータ
このページでは、Python Learner、Python Transformer、Python Forecasterオペレータを使用してカスタムオペレータを作成することで、PythonコードをRapidMinerプロセスにさらに埋め込む方法を説明します。このカスタムオペレータは、Pythonに詳しくない人とも共有することができます。
Python Learnerオペレータ
Python Learnerでは、RapidMinerのモデルインタフェースと互換性のある、Pythonベースのモデルを作成することができます。Python Learner(およびそこから派生したカスタムオペレータ)を使って作成したモデルは、Apply Modelオペレータを使用してモデルの適用や、RapidMinerのCross-Validationオペレータを使用してモデルの学習、Optimizeオペレータを使用して調整できたりと、様々なことができます。
RapidMiner Studioのオペレータパネルから新しいPython Learnerをキャンバスにドラッグすると、(オペレータの色や入出力ポートなどの点で)他の学習モデルと似たオペレータが表示されます。また、あらかじめいくつかのパラメータが設定されており、それらを編集することができます。サポートされているパラメータタイプの一覧は以下の通りです。
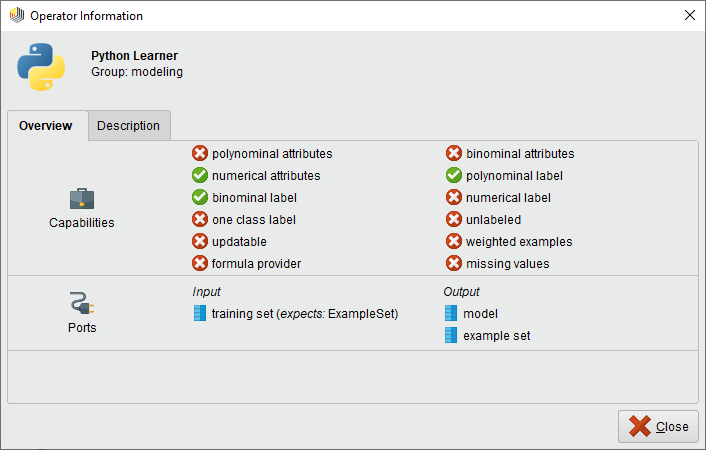
オペレータの情報パネルには、このPythonベースの学習モデルの機能も表示されています。
パラメータの定義や機能を編集するには、パラメータパネルの歯車アイコンをクリックします。JSONエディタが表示され、これらを追加・変更することができます。ここに書いたJSONは検証され、何かが間違っている場合は警告が表示されます。誤った設定を適用すると、キャンバス上のオペレータから入力ポートが消えてしまいます。
Python Learnerを実装するには、rm_trainとrm_applyの2つの関数を定義する必要があります。名前が示すように、最初のものは、Python Learnerオペレータでモデルを学習させるときに実行されます。2つ目は、Python Learnerで作成したモデルをApply Modelなどで適用する際に実行されます。これらの機能を実装するためのヒントは、提供されているチュートリアルプロセスを参照することをお勧めします。
Python Transformerオペレータ
Python Transformerは、ユーザーが定義したパラメータと入出力ポートを持つExecute Pythonオペレータと捉えることができます。
オペレータの名前やパラメータ名、タイプ、デフォルト値、入力ポートと出力ポートは、オペレータのパラメータパネルで歯車のアイコンをクリックし、ポップアップエディタでJSON定義を編集して定義します。これは、上で説明したPython Learnerオペレータのものとよく似ています(Transformerは機能のリストを持ちませんが、入力と出力を必要とします)。ここに書いたJSONは検証され、何かが間違っている場合は警告が表示されます。誤った設定を適用すると、キャンバス上のオペレータから入力ポートが消えてしまいます。サポートされているパラメータタイプの一覧は以下の通りです。
コードを期待通りに実行するためには、Execute Pythonと同じ規則に従わなければなりません。メインのエントリーポイントはrm_main関数で、関数のパラメータと戻り値の数と順序は、オペレータの入力ポートと出力ポートに対応しています。
Python Transformerベースのカスタムオペレータに複数の入力と出力が必要な場合は、JSON定義の inputs と outputs の部分を使用して明示的に定義する必要があります。Execute Pythonの動的なポートに慣れているユーザーは、直感的でないと感じるかもしれません。
新しいPython Transformerをキャンバスにドラッグしたときに表示されるパラメータ設定とコードのサンプルには、上記のヒントがすべて含まれています。
Python Forecasterオペレータ
注意: Python Forecasterオペレータはバージョン9.10.2以降で利用可能です。
Python Forecasterオペレータを使用すると、RapidMiner Studioの時系列系のオペレータのように予測モデルを作成することができます。また、このオペレータはApply Forecastオペレータにも対応しています。
RapidMiner Studioのオペレータパネルから新しいPython Forecasterをキャンバスにドラッグすると、Python Learnerオペレータと似たオペレータ(オペレータの色や入力/出力ポートなどの点で)が表示されます。また、あらかじめいくつかのパラメータが設定されています。追加のパラメータや入力、出力を追加することもできます。サポートされるパラメータの種類と設定可能な入力/出力ポートの一覧は以下をご覧ください。
Python Forecasterを実装するには、rm_trainとrm_applyの2つの関数を定義する必要があります。名前が示すように、1つ目は、Python Forecasterオペレータでモデルを学習させるときに実行されます。2つ目は、Python Forecasterで作成したモデルをApply Forecastオペレータで適用する際に実行されます。そのため、このオペレータは、RapidMinerのApply Forecastオペレータと互換性のあるPython Forecastモデルを生成します。
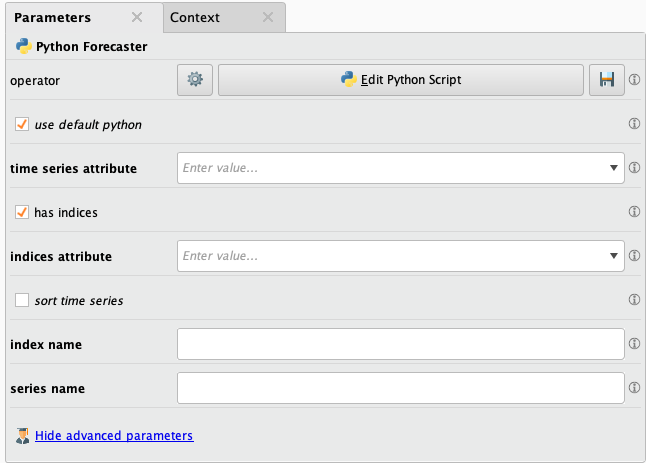
Python Forecasterオペレータは、Python Learnerオペレータと似たパラメータを持っており、以下のことが可能です。
- JSON設定の変更
- Pythonスクリプトの変更
- オペレータの保存
- 環境の使い分け
- Pythonバイナリ
- 仮想環境
- conda環境
しかし、Python Learnerでは定義されていない追加のパラメータがいくつかあります。それは以下です。
- timeseries attribute: 何を予測するかを選択できます。
- has indices: データがインデックスを持つか選択できます。
- indices attribute: インデックス列を選択できます。
- sort time series : データがソートされていない場合、これでソートできます。
デフォルトでは、Pythonスクリプト内でtimeseries属性とインデックス属性を使用するのに用いる、隠しパラメータが2つ存在します。2つの追加パラメータは以下です。
- series_name
- index_name
Pythonスクリプトからは、以下の方法でアクセスすることができます。
index_name = parameters['index_name']
series_name = parameters['series_name']
その他の例については、チュートリアルプロセスをご覧ください。
サポートされているパラメータタイプ
ここでは、Python Learner、Python Transformer、Python Forecasterでサポートされているパラメータタイプのリストを紹介しています。これらは、オペレータのパラメータ設定を行うJSONのparametersリストで使用できます。
| JSONのタイプ | パラメータの表示 |
|---|---|
| string | テキストボックスに文字列 |
| category | 単一選択のドロップダウン |
| boolean | チェックボックス |
| integer | テキストボックスに整数 |
| real | テキストボックスに浮動小数点数 |
各パラメータ定義には以下の属性があり、パラメータを記述するタプルの中ではキーと値のペアで表現されます。
| 属性 | 必須項目 | 説明 |
|---|---|---|
| name | 必須 | オペレータのパラメータパネルに表示されるパラメータ名 |
| type | 必須 | パラメータのタイプ(サポートされているタイプは上の表を参照してください) |
| categories | タイプが categoryの場合のみ必須 | パラメータのドロップダウンに表示される選択肢を、ユーザーが指定した順序で表示します。値はリスト形式である必要があります。 |
| optional | 必須ではない | trueに設定すると、パラメータの値が空の場合でもオペレータが実行されます。 |
| value | optionalが false または提供されていない場合のみ | パラメータの初期値 |
ここでは、上記のパラメータの定義に対するいくつかの例を紹介します。
"parameters": [
{
"name": "1st_parameter",
"type": "string",
"optional": true
},
{
"name": "2nd_parameter",
"type": "integer",
"value": 100
},
{
"name": "3rd_parameter",
"type": "category",
"categories": [
"Category A",
"Category B",
"Category C",
"Default Category"
],
"value": "Default Category"
},
{
"name": "4th_parameter",
"type": "boolean"
},
{
"name": "5th_parameter",
"type": "real",
"value": 3.1415
},
{
"name": "6th_parameter",
"type": "string",
"optional": true
}
]
ユーザーが設定可能な入力/出力ポート
注意: 設定可能な入力/出力ポート機能は、バージョン9.10.2以降で利用可能です。
ユーザーは、Python Learner、Python Transformer、Python Forecasterの入力/出力ポートを追加で定義することができます。これを行うには、編集可能なJSON設定のinputsまたはoutputsの配列に、JSONオブジェクトの要素を追加する必要があります。
以下は追加した入力ポートの例です。
"inputs": [
{
"name": "additional input 1",
"type": "table"
},
{
"name": "additional input 2",
"type": "table"
}
]
以下は追加した出力ポートの例です。
"outputs": [
{
"name": "additional output 1",
"type": "table"
},
{
"name": "additional output 2",
"type": "table"
}
]
すでに以前追加したポートを使用するには、以下の章を確認してください。また、Python Forecasterオペレータのチュートリアルプロセスにある例もご参考ください。
ユーザーが設定可能な入力ポートの使用方法
inputs配列を拡張した後は、定義した入力ポートにはrm_trainメソッドからアクセスすることができます。rm_trainでは、追加した入力ポートを含んだ*inputs引数で呼び出されます。そのため、rm_train()メソッド定義にパラメータを追加した場合、入力に到達することができます。
以下はPython Learnerの例です。
# The original definition:
rm_train(X, y, parameters)
# The new definition with two additional inputs:
rm_train(X, y, additional_input_1, additional_input_2, parameters)
以下はPython Forecasterの例です。
# The original definition:
rm_train(index, series, parameters)
# The new definition with two additional inputs:
rm_train(index, series, additional_input_1, additional_input_2, parameters)
ユーザーが設定可能な出力ポートの使用方法
outputs配列を拡張した後は、rm_trainメソッドはユーザー定義の出力ポートへデータを転送することができます。rm_trainメソッドは、rm_applyメソッドに渡したいモデルやオブジェクトを返します。return文では、常に最初のオブジェクトがrm_applyメソッドに渡され、追加したオブジェクトは追加した出力ポートに転送されます。これらのデータはpandas DataFramesでなければなりません。
以下はモデルを返す例です。
# The original return statement:
return model
# The new definition with two additional outputs:
return model, additional_output_1, additional_output_2
さらに、以下はオブジェクトを返す例です。
# The original return statement:
return {
'model': model
}
# The new definition with two additional outputs:
return {
'model': model
}, additional_output_1, additional_output_2
カスタムPythonオペレータでの環境の扱い
Execute Pythonオペレータと同様に、use default Pythonパラメータのチェックを外して、使用する環境を指定することができます。Python Learnerの場合、モデルが適用される際も学習に使用したものと同じ環境で行われます。
モデルの適用が別のマシン(RapidMiner AI Hubなど)で行われる場合は、同じ名前のPython環境が利用可能か確認してください。利用できない場合は、実行が失敗するか、望ましくない結果になります。
カスタムオペレータの共有と配布
作成したPython Learner、Python Transformer、Python Forecasterの動作が十分であれば、次のステップとして、オペレータをプロジェクトに携わる他の人と共有することができます。これらのすべてのオペレータは、パラメータパネルに保存ボタンを持ちます。
保存をクリックして、プロジェクトやリポジトリの場所を指定すると、 .pyop 記述子のファイルが作成されます。
ユーザーがこの .pyop ファイルをRapidMiner Studioのキャンバスにドラッグすると、コードとパラメータの定義をすべて含むLearnerまたはTransformerが、カスタムオペレータに指定した名前で作成されます。このオペレータは編集できないため、以前書いたコードが意図した通りに実行されることが保証されます(使用するPython環境がRapidMinerプロセスを実行するマシンに存在する場合)。
この共有方法の欠点は、 .pyop 記述子がキャンバスにドラッグされ、新しいオペレータが作成された後に、オペレータを更新することができない点です。これらのオペレータの更新を確実に行う必要がある場合は、カスタムオペレータをエクステンションとして配布する必要があります。そのためには、 .pyop ファイルのあるフォルダを右クリックし、Create Extension…をクリックし、表示されたダイアログに詳細を入力します。また、新しいエクステンションにコンパイルされるカスタムオペレータのリストも表示されます。Create Extensionをクリックします。
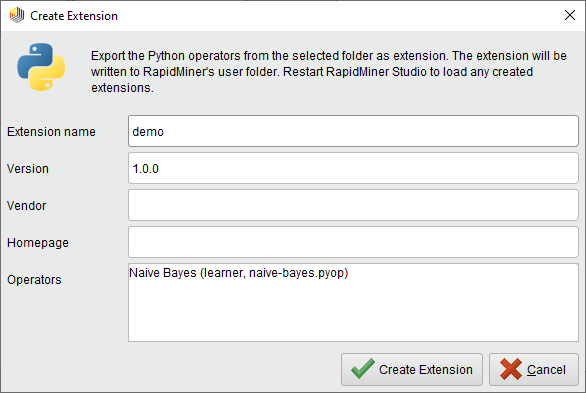
エクステンションが作成されると、他のエクステンションと同様に配布することができます。オペレータを更新したいときは、新しいバージョンのエクステンションを作成して、すべてのユーザに再配布します。
注意:作成されたエクステンションはPython Scriptingエクステンションのバージョン9.9以降に依存しているため、各ユーザーもエクステンションをインストールしておく必要があります。
