RapidMinerでSparkを使用する方法
投稿日: 2022年8月3日
OS: CentOS 7
バージョン: RapidMiner 9.9
前提条件
- 以下のサービスが起動している。
- HDFS
- Hive
- Hue
- Spark
- YARN(MR2 Included)
- Zookeeper
- Radoopエクステンションがインストールされていて、titanicデータがHDFSに格納されている。
参考:RapidMinerでHDFS/Hiveを使用する方法
Sparkライブラリを使用したデータ分析
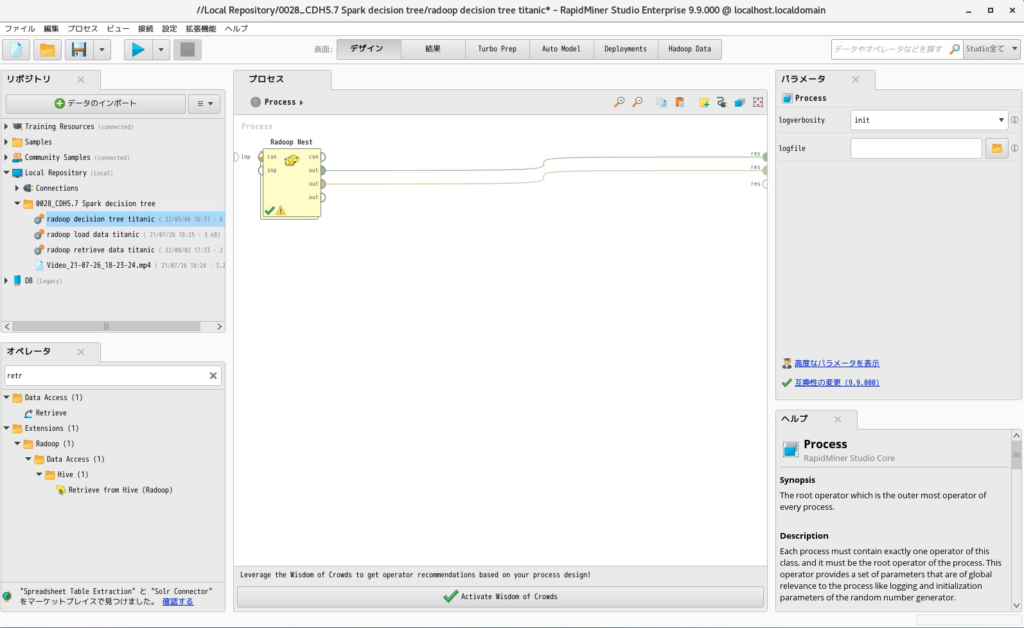
- 「Radoop Nest」を以下のように配置します。結果が2つあるのでresは2つ用意しています。
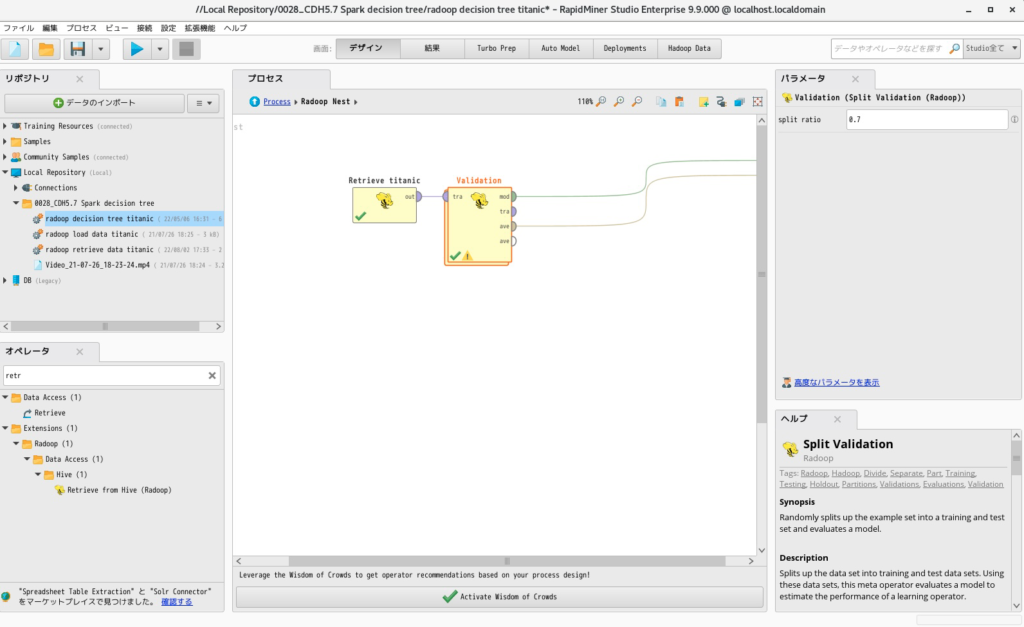
- 「Radoop Nest」をクリックして、以下のように「Retrieve from Hive」と「Split Validation」を配置します。
- 「Split Validation」をダブルクリックで開き、SparkMLの「Decision Tree」、「Apply Model」、「Performance (Classification)」を以下のように配置します。ここでのPerformanceは「accuracy」のみチェックしています。
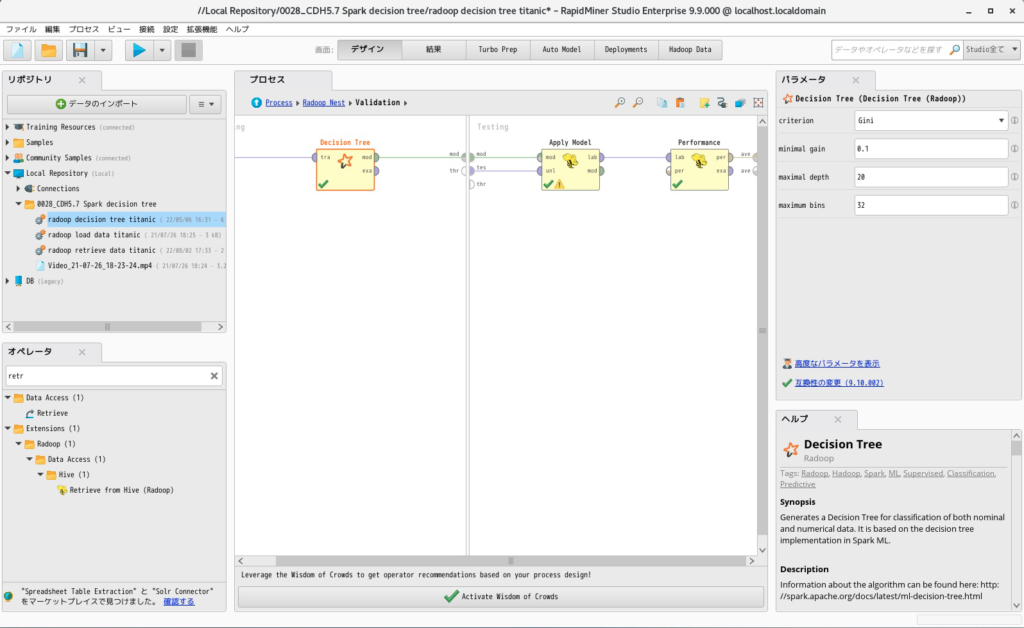
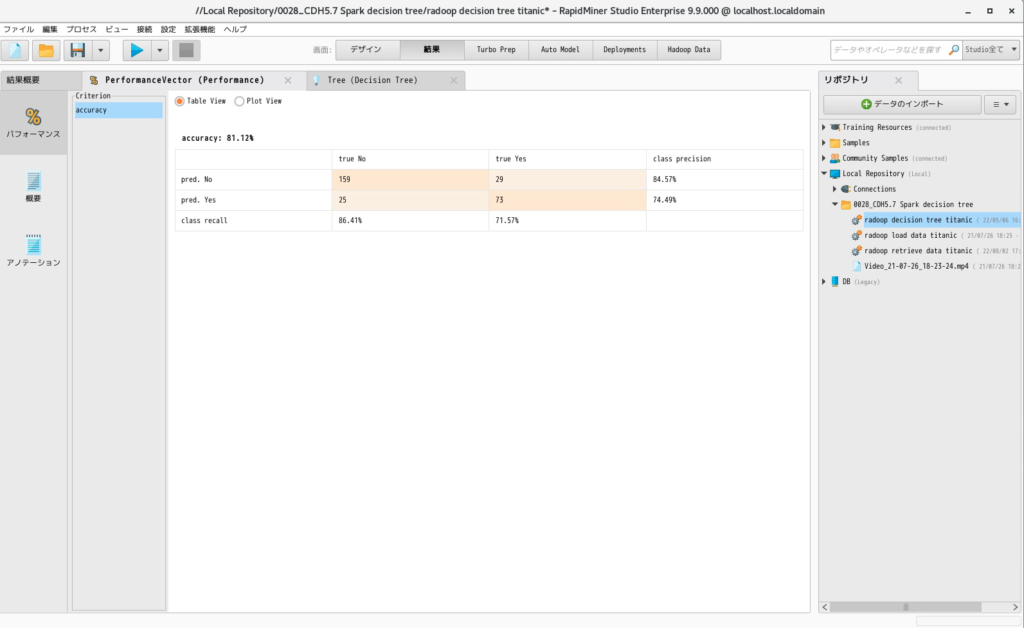
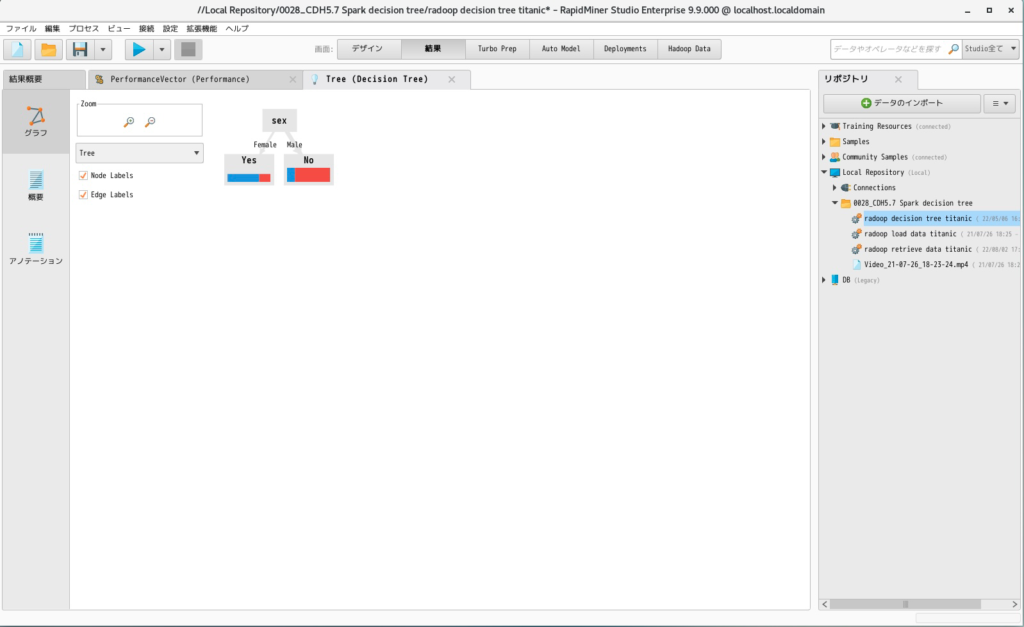
- 実行すると以下の結果が得られます。