CI/CDのベストプラクティス
プロジェクトに関するベストプラクティスの文書も参照してください。
AIイニシアチブを効果的に拡張するには、企業の他のどの部分においても、ワークフローを中断させることなく、プロジェクトの改訂版を自動的にテストし、本番環境にリリースできるシステムを構築する必要があります。そのために、Altair RapidMinerはアジャイルプログラミング手法に基づき、データサイエンスプロジェクトに適応した一連のベストプラクティスを確立しました。
このドキュメントでは、これらのベストプラクティスを共有し、企業がAltair RapidMinerを使用して組織内で民主化されたデータサイエンス開発パイプライン(CI/CD)を設定する方法について説明します。これにより、企業はAIイニシアチブを拡張しながら、本番環境の整合性を確保するための構造と安全策を提供することができます。
Altair AI Hubの環境構造
開発環境と本番環境を分けることは、ソフトウェア開発ライフサイクルの基本的な原則です。別々の環境を構築することは、下流で予期せぬ結果を招くことなく、技術革新と試行を促進するための実証済みの方法です。
Altair RapidMinerのマルチペルソナユーザーの多くはソフトウェア開発の経験がないため、俊敏かつ安全な組織全体のアーキテクチャをサポートするために、3~4つに分離された、バージョン一貫性のあるAI Hub環境をお勧めします。
環境 1: 開発 (DEV)
この環境は、通常、新規プロセスの構築、アイデアの試行、データパイプラインの変更などを、他に影響を与えることなく安全に行うために使用されます。プロジェクトの変更が全く別の場所のワークフローに間接的に影響すると、企業にとって壊滅的な打撃になる可能性があるため、開発は、通常、不必要なリスクを避けるために別の「サンドボックス」環境で行われます。この環境のリソースは標準化される傾向があり、アクティブユーザーの数にのみ依存します。一般的な経験則では、64GBユニットあたり10~20人のアクティブユーザーとなります。この環境は稼働時間の信頼性を保証するものではなく、バックアップは行われているものの、ロールバックはほとんど行われていません。ワークフローとモデルは、変更と試行を追跡するためにバージョン管理されています。これらの制限は、サンドボックス環境では予想され、正常であることに注意してください。DEVでの権限付与は寛大で、試行を奨励しています。
環境 2: テスト (TEST)
新規プロジェクトが開発された後、リリース前に内部テストを実施する必要があります。テストはさらにアルファ版やベータ版のなどのフェーズに分けることができ、DEVやPRODを壊すことなく準安定版でテストすることがベストプラクティスです。これは一般的にTESTやQA(品質保証)と呼ばれ、ソフトウェアエンジニアリングの「統合テスト」フェーズに相当します。このTEST環境では、新規デプロイメントの潜在的な欠陥を見つけるために、実際のデータとプロセスのサンプルを使用します。TESTでの権限付与は一般にDEVと似ていますが、PRODに進むすべてのプロセスの標準化されたテストサイクルを保証するために、TEST環境は定期的に「クリーンな状態にする」ことが一般的です。
環境 3: ステージング (STAGING)
この環境はPRODの直接クローンであり、PROD Hubに影響を与えることなくエンドツーエンドのデプロイメントをテストするために使用されます。権限は一般的に制限されており、常にPRODの100%シミュレーションとなるように定期的に更新されます。AWS、Azure、GCPなどのクラウドインフラストラクチャで稼働するAI Hubの場合、必要に応じてこのインスタンスをスピンアップ/ダウンさせることで、費用対効果を高めることができます。権限は極めて制限され、スピンアップ中の稼働時間は 99.99% 以上が保証されます。
環境 4: 本番環境 (PROD)
このAI Hubは主に読み取り専用の環境で、ビジネス価値を生み出すためのプロセスを実行します。この環境で発生する問題は実際の費用がかかるため、前のどの段階にも影響を受けることはありません。そのため、権限は極めて制限され、稼働時間は99.99%以上が保証されます。デプロイメントは、安定性を確保するために専用のRAM/ストレージでコンテナ化されます。変更は頻繁に行われず、管理されています。
CI/CDライフサイクル
一般的なCI/CDライフサイクルの例を次に示します。
「B.変更」には次の2つのタイプがあることに注意してください。
- ソフトウェアの変更
- 機械学習モデルの変更
従来のソフトウェア開発とは対照的に、機械学習開発の特徴の1つは、新しいデータに直面した際の性能を向上させるためにモデルを定期的に再トレーニングする必要があることです。例えば、入力データの分布が変化した場合、ソフトウェアを変更する必要はないかもしれませんが、パフォーマンスを維持するためにモデルを更新する必要があります。
A. 初期展開
- データエンジニア/機械学習のプロフェッショナルであるエンジニア、Eddieは、デプロイしたいgitバージョンのプロジェクトをDEV上に構築します。これは、外部webサービス、ダッシュボード、メールやSMS経由のアラート、データベースやExcelシートにデータをプッシュバックするスケジュールされたETLジョブなどによって使用されるモデルのスコアリングです。これは完成した時点で「ベータ」とみなされ、eddie-deployment-0.1という名前になります。
- Eddieは、プラットフォーム管理者である同僚のエンジニア、Elizabethに自分のデプロイメントのレビューとテストを依頼します。ElizabethはEddieにフィードバックを提供し、彼のデプロイメントが安全かつセキュアで、十分に文書化されており、リソースを過度に消費せず、組織全体の他のデプロイメントと一貫した設計になっていることを確認します。新規変更が適用され、ElizabethとEddieは、これをeddie-deployment-0.2とすることに合意します。
- Eddieは、CI/CDパイプライン全体を監督し、STAGINGとPRODの両方に完全な管理者アクセス権を持つシステム管理者のSandraにeddie-deployment-0.2を提出します。Sandra、またはSandraのチームの適切な権限を持つ誰かが、EddieのプロジェクトをSTAGINGにロードします。彼女はこのプロジェクトをデプロイする最終決定を下し、割り当てるリソースを決定します。
- Sandraは、EddieのプロジェクトをSTAGINGからPRODに移行させ、彼のデプロイメントがeddie-deployment-1.0として本番稼動したことをEddieに通知します。彼女は関連するURLをすべて共有し、Eddieに権限を割り当てて、彼が設計どおりにデプロイメントを使用できるようにします。Sandraは、このデプロイメントをPRODで監視する他のデプロイメントのリストに追加し、必要に応じてアラートを設定します。また、Sandraは、Eddieのデプロイメントを評価するために3 か月後の監査を彼と予定しています。
B. 変更
- デプロイメント後のある時点で、Eddieはプロセスの1つに何らかの改善を加えたいと考えます。彼はDEVで作業し、eddie-deployment-1.1を自分のプロジェクトリポジトリに置きます。
- Eddieは、最初にデプロイメントを公開したときとまったく同じ段階を経ます。しかし、プロジェクトの大部分は変更されていないため、このプロセスはより速くなります。成功すれば、Sandraはeddie-deployment-1.0のすべてのユーザーに、生み出されるビジネス価値への全体的な影響を最小限にするために、特定の日時にアップグレードすることを通知します。本番時、これはeddie-deployment-2.0になります。
C. 四半期レビュー
最新リビジョンのeddie-deployment-2.0の本番稼動から3ヶ月後、Sandraと彼女のチームはEddieやこデプロイメントの他のユーザーと会い、パフォーマンスとリソースの割り当てをレビューします。コードの変更が推奨される場合、EddieはBに示す手順に従います。レビューで非推奨が推奨される場合、彼はセクションDに概説されている手順に従います。
D. 非推奨
- 最初のデプロイメントから18カ月後に行われた四半期レビューで、SandraとEddieは、彼のデプロイメントがもはやビジネス価値を生み出さなくなったため廃止すべきであることに同意しました。アナリストのAlyssaは、このビジネスの問題に対する新しいソリューションに取り組んでおり、彼女のデプロイメントであるaryssa-deployment-0.1をDEVからTESTに移行するプロセスを開始する準備ができています。Sandraはeddie-deployment-2.0の既存ユーザー全員に、特定の日時に廃止されることを通知します。これは、時間を重要視するアプリケーションに合わせて調整できるように、十分な余裕を持って行います。
- 指定された日時に、Sandraはeddie-deployment-2.0をPRODから削除し、監査目的のためにプロセスとすべてのログをアーカイブします。彼女はリソースを別のデプロイメントで使用するために一般プールに移します。
プロジェクトデプロイメントのための管理ツール
最終的にデプロイされるすべてのプロセス、ExampleSets、関連オブジェクトは、常にプロジェクト内に存在する必要があります。技術的には、これらのプロジェクトはgitでバックアップされているため、異なる環境へのデプロイメントはgitの「clone / copy / push」操作と同じです。
AI Hubへのリモートアクセスと制御により、プロジェクトへのアクセスを含むタスクの自動化が可能です。これはREST-APIによって実現されます。
Admin Extension
このような高度なトピックであってもコード不要の手法を全面的に採用するために、Admin Extensionが作成されました。ユーザーは、オペレーターを1つ使用するだけで、Altair RapidMinerのエコシステム内で、完全にAI Hubから別のAI Hubへプロジェクトをデプロイすることができます。
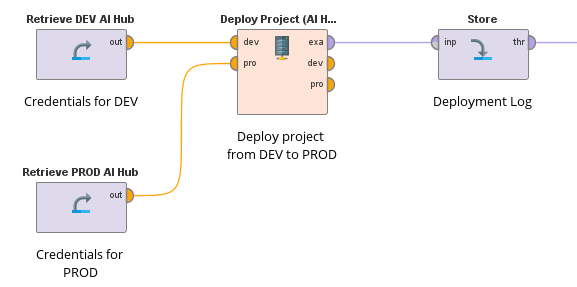
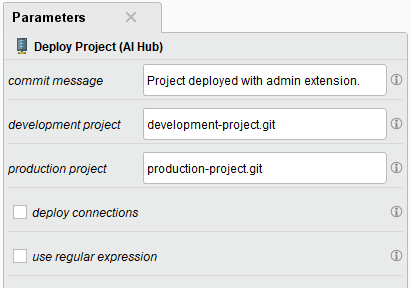
ユーザーは、専用のAI Hub接続オブジェクトを作成するために、両方のAI Hub(例えば、DEVからTESTへ)の適切な権限を持つ接続認証情報が必要になります。これらはオペレータの入力であり、ソースとターゲットプロジェクトはパラメータパネルで定義されます。
通常、環境によってデータソース(データベースなど)が異なるため、管理者は接続をデプロイするのではなく、新しい環境に適したデータソースを指す同じ名前の接続を作成することを検討する必要があります。
