生成AI
RapidMinerのGenerative Modelsエクステンションは、誰でも生成AIモデルを使用できるだけでなく、そのようなモデルを構築することもできます。コードを1行も書く必要はないので簡単です。このエクステンションの現在のバージョンは、いわゆるLarge Languageモデル (LLM)に焦点を当てています。多くの企業にとって、これらのモデルは、画像モデル、ビデオモデル、オーディオモデルと比較して最も大きな価値を提供します。RapidMinerマーケットプレイスにはこれらのテキスト以外のユースケースを対象とする他のエクステンションもあり、このエクステンションの将来のバージョンではそれらも対象とする可能性があります。このエクステンションを使用して、Huggingface.coやOpenAIのChatGPTにある何十万ものモデルを利用したり、それらを微調整したりする場合は、楽しみながら創造力を発揮してください。生成AIは、分類や回帰のような他の機械学習の手法を超えた、多くの新規ユースケースに対するソリューションを提供します。
目次
ログインとセットアップ
以下の説明で、Generative Modelsエクステンションの要件を説明します。パッケージマネージャ、正確なPython環境を提供し、以下で説明する正しいバージョンを使用していることを確認してください。そうでない場合、このエクステンションのオペレータが機能しない可能性があります。
RapidMinerエクステンションの依存関係
このエクステンションを使用するには、RapidMiner Studioのバージョン10.3以降が必要です。また、このエクステンションは他の2つのRapidMinerエクステンションに依存しており、このエクステンションを使用する前にインストールする必要があります。
- Pythonスクリプト >= 10.0.1
- カスタムオペレータ >= 1.1.2
RapidMiner Studioの場合は、このエクステンションをインストールする前に、メニューのエクステンション > マーケットプレイスからこれら両方のエクステンションをインストールしてください。RapidMiner AI Hubの場合は、AI Hubのドキュメントの指示に従って両方のエクステンションをインストールしてください。
Pythonスクリプトエクステンションは適切に設定する必要があります。つまり、RapidMinerの設定で、少なくともPandasパッケージを含む必要があるデフォルト環境とともに、動作するPythonインストールを指定してください。RapidMiner StudioでPythonを設定する方法の詳細については、ドキュメントを参照してください。
Python環境のセットアップ
重要: このエクステンションの前のバージョンv1.0を使用していて、システム上に rm_genai 環境を既に作成している場合、以下のインストール手順を実行する前に、まずこの環境を削除(または名前変更)する必要があります。既に存在する rm_genai 環境を削除するには、以下を実行してください。
conda remove --name rm_genai --all
ステップ1: 環境設定ファイルのダウンロード
以下の表から.ymlで終わる正しい環境定義ファイルをダウンロードし、ファイルシステムのどこかに保存してください。正しい環境のインストールは、お使いのオペレータシステムとCUDA対応グラフィックスプロセッサユニット (GPU) へのアクセスの可否によって異なります。また、GPUがサポートするCUDAバージョンによっても異なります。サポートされているCUDAバージョンを確認するには、GPUのドキュメントを参照してください。お使いのハードウェアに基づき、正しい環境設定ファイルをダウンロードして保存します。
| オペレータシステム | CPU | GPU (CUDA 11.8) | GPU (CUDA 12.1) |
|---|---|---|---|
| Windows | rm_genai_conda_windows_cpu.yml | rm_genai_conda_windows_gpu_cuda_11_8.yml | rm_genai_conda_windows_gpu_cuda_12_1.yml |
| Mac OS | rm_genai_conda_macos.yml | n/a | n/a |
| Linux | rm_genai_conda_linux_cpu.yml | rm_genai_conda_linux_gpu_cuda_11_8.yml | rm_genai_conda_linux_gpu_cuda_12_1.yml |
注意: MacではGPUを使用できませんが、Appleの新規Mチップを搭載している場合は、ほとんどの言語モデルでいわゆるMPSデバイスを使用することができます。Macでは上記のCPUベースの環境定義を使用してください。
ステップ2: 追加パッケージ設定のダウンロード
以下の表から適切なリソース.txtファイルをダウンロードし、上記の環境設定を保存したのと同じフォルダに保存してください。上記のように、お使いのハードウェアに対応するファイルを選択する必要があります。ただし、現在のところ、CPUとGPUの定義はWindowsとMac OSの両方で同じです。
| オペレータシステム | CPU | GPU (CUDA 11.8) | GPU (CUDA 12.1) |
|---|---|---|---|
| Windows | rm_genai_requirements_windows.txt | n/a | n/a |
| Mac OS | rm_genai_requirements_macos.txt | n/a | n/a |
| Linux | rm_genai_requirements_linux_cpu.txt | rm_genai_requirements_linux_gpu.txt | rm_genai_requirements_linux_gpu.txt |
注意: MacではGPUを使用できませんが、Appleの新規Mチップを搭載している場合は、ほとんどの言語モデルでいわゆるMPSデバイスを使用することができます。Macでは上記のCPUベースの環境定義を使用してください。
ステップ3: CondaとPythonのインストール
このエクステンションは、正確に指定されたバージョンのパッケージを使用するパッケージセットを備えた特定のConda環境を必要とします。パッケージマネージャーとしてCondaを使用する必要があり、最初にインストールする必要があります。
少なくともPython 3.11.5がバンドルされたMinicondaをインストールすることをお勧めします。
3.11.5より大きいバージョンのPythonが提供され、次のステップで問題が発生する場合は、ここでダウンロードできるPython 3.11.5を正確に含むバージョンを試してください。
インストールが完了したら、Windowsのスタートメニューまたは他のオペレーティングシステムのシステムプロンプトからAnaconda Prompt (miniconda 3)を開きます。
ステップ4: Conda環境の作成
上記の2つの表から正しいファイルをダウンロードして保存し、condaを正常にインストールしたら、エクステンションで使用される環境を作成します。
プロンプトウィンドウでは、行頭に現在のconda環境が表示されているはずです(通常、この段階では「base」)。次に、2つのファイルをダウンロードしたフォルダに移動します。
cd <path/to/your/download/folder/you/used/above>
両方のファイルがこのロケーションにあることを確認してください。次に、以下のコマンドを実行します。
conda env create -f rm_genai_conda_<os>_<cpu / gpu_CUDA-version>.yml
ダウンロードしたファイルの名前には正しいオペレータシステムを指定し、cpuまたはgpuの接尾辞には希望するCUDAバージョンを指定してください。このコマンドが完了すると(数分かかります)、成功のメッセージと新規環境 rm_genai の有効化方法の説明が表示されます。
ステップ5: Pipを使用した追加パッケージのインストール
最後に、上記で使用したのと同じコマンドラインウィンドウで、conda環境を有効にします。
conda activate rm_genai
コマンドラインの先頭に新規環境名が表示されるはずです。
次に、2つのファイルをダウンロードしたフォルダで、以下のコマンドを実行します。
pip install -r rm_genai_requirements_<os>_<cpu / gpu>.txt
上記と同様に、ダウンロードしたファイルの名前を使用しますが、これはオペレーティングシステムとハードウェアによって異なります。しばらくすると、すべてのパッケージが正常にインストールされ、準備が整います。GPUセットアップを選択した場合は、後でオペレータのログメッセージに「GPU used」などの記述がないか確認し、インストールが正しく行われたことを確認してください。
ヒント: ダウンロードした環境設定ファイルで指定されているとおりに rm_genai という名前を使用することをお勧めします。そうすることで、このエクステンションのすべてのオペレータで、この名前がデフォルトのパラメータ値となり、すぐに使用できるようになります。しかし、どうしても別の環境名を使用したい(または使用する必要がある)場合は、別の名前にすることができます。この場合、この別の名前をすべてのオペレータの「conda環境」パラメータ(エキスパートパラメータ)のパラメータ値として設定する必要があります。
データ転送に関する注意事項
生成AIと大規模言語モデルの核となる考え方は、膨大な量のデータでトレーニングされた、いわゆる基礎モデルを使用することですが、必ずしも特定のタスクを解決するわけではありません。これらのモデルは、特定のタスクを解決するために、特定のトレーニングデータで微調整されます。いずれにしても、またその名前が示すように、基礎モデルも微調整されたモデルも一般的に大規模になります。
RapidMinerは多くの場合、Huggingface.coから基礎モデルや以前に微調整されたモデルを取得します。どのモデルを開始点として使用するかを指定する必要があり、対応するオペレータと一緒にダウンロードされます(詳細は以下を参照)。これらのモデルはローカルに保存されます。しかし、これらのモデルの多くはサイズが数ギガバイトになる可能性があるため注意してください。大きなモデルのダウンロードには時間がかかるため、RapidMinerのログウィンドウでダウンロードプロセスを監視することができます。
当然、必要なパッケージや基礎モデルを取得するには、このエクステンションが動作している場所でインターネットに接続できる必要があります。
GPUに関する注意事項
大規模言語モデルの使用や微調整は非常に計算量が多く、計算にGPUを使用することで劇的に高速化することができます。サポートされているGPUが検出され、GPUが正しく設定されている限り、このエクステンションは自動的にGPUを利用します。GPUを使用しても、大規模なモデルの微調整や大規模な微調整データセットの使用には、数週間とまではいかなくても、数日かかることがあります。しかし、GPUがなければ、大規模なモデルの完成には、数日、数週間、場合によっては数ヶ月を要します。また、Apples社の新規Mチップアーキテクチャ(MPSと呼ばれる)もサポートされていることに注意してください。
トークンに関する注意事項
Generative Modelsエクステンションやこのドキュメントでは、トークンという言葉をよく目にします。ほとんどの言語モデルにおいて、トークンは必ずしも単語と同等ではありません。音節や単語の一部に近いものです。また、単語が複数のトークンから構成されることもあります。つまり、「max_target_tokens」パラメータがある場合、これはモデルの答えがいくつのトークンになるかを意味します。16という値は16単語を意味するのではなく、16トークンを意味します。トークンの平均的な長さも言語によって異なります。英語の場合、トークンの平均的な長さは約4文字であるため、予想される最大長は約 4 x 16 = 64 文字であることが予想されます。
エクステンションの使用
エクステンションは次の2つのオペレータグループを提供します。
- 1つはHuggingfa ce.coポータルのモデルを扱うグループです。
- もう1つはOpenAIのような商用モデルを使用するグループです。
しかし、どちらのオペレータグループも異なる動作をします。すべてのHuggingfaceモデルについては、Huggingfaceからモデルをダウンロードし、それをローカルで微調整するか、単に使用する必要があります。これはRapidMinerの典型的なワークフローに似ており、データやモデルをローカルで操作し、ローカルに保存します。
OpenAIモデルなどの商用モデルでは、多くの場合、ベンダーのクラウドインフラストラクチャ上でリモートで行われます。モデルをダウンロードする代わりに、データとモデルアプリケーションをアップロードするか、あるいは微調整をリモートで行います。また、これは非同期で行われます。例えば、OpenAIの場合、これは微調整などの長時間実行される操作のほとんどがすぐに返され、ジョブIDを取得できることを意味します。ジョブが完了すると通知が届き、そのIDで定義された新規モデルの利用を開始することができます。詳細はOpenAIのオペレータグループのセクションで後ほど説明します。
ディクショナリ接続
このエクステンションに属する一部のオペレータは、キーと値のペアを含むディクショナリ接続を作成する必要があります。以下は、これらの接続で使用可能なすべてのキーの概要です。AI Studioでは、「Connections 」メニューから「Create Connection」を選択して、新規ディクショナリ接続を作成できます。ダイアログで、タイプとして「Dictionary Connection」を選択し、任意の名前で保存します。作成後、「Add Entry」をクリックし、新規のキーと値のペアを追加してください。以下の表で説明するように、接続に必要なすべてのキーに対してこれを行います。
| 接続 | キー | 値の説明 |
|---|---|---|
| Huggingface | token | ポータルで確認できるHuggingfaceトークン。特定のモデルにアクセスするために必要な場合があります。 |
| OpenAI | api_key | OpenAI APIキー。OpenAIのユーザープロファイルで作成および確認できます。https://platform.openai.com/account/api-keysを参照してください。 |
| Milvus | uri | MilvusインスタンスのURI |
| Milvus | token | Milvusのセキュリティトークン。生成されたAPIキーか、この形式のユーザー/パスワードのペアです。 |
| Qdrant | uri | QdrantインスタンスのURI |
| Qdrant | token | Qdrantセキュリティトークン。Qdrantインスタンスがトークンを必要としない場合は、このキー/値を省略できます。 |
Huggingfaceモデルによる生成AI
まずはHuggingfaceモデルから始めましょう。上述したように、全体的な流れは通常のRapidMinerワークフローに似ています。一般的には、Huggingfaceからモデルを指定するか、そこからモデルをダウンロードし、オペレータを使用してこのモデルをデータに適用します。また、自分のデータに基づいてモデルを微調整することもできます。これがどのように機能するか見てみよう。
大規模言語モデルの使用
ここでは、誰かがHuggingfaceポータルにアップロードしたモデルを単純に使用することから始めます。
この記事を書いている時点で、450,000以上のモデルがHuggingfaceにアップロードされているため、タスクを正確に解決するモデルが見つかることが多いでしょう。そうでない場合でも、そこで見つけたモデルを、あなたのタスクに合わせて微調整するための基礎として使用することはできます。それについては後で詳しく説明します。
まず注意しなければならないのは、生成AIモデルには、従来の機械学習よりも多くのタスクがあるということです。機械学習では、分類や回帰など、タスクの種類はほんの一握りしかありません。しかし、生成AIの場合、自然言語処理だけでもすでに10種類ほどのタスクタイプがあります。さらに、画像、動画、音声など他のデータ形式用のタスクタイプもあります。
先に述べたように、このエクステンションではまず自然言語に焦点を当てます。そのために、次の種類のタスクを認識し、サポートしています。
- 会話型: これらのモデルは、会話による入力に対する回答を提供することができます。例えば、あるモデルは「こんにちは、お元気ですか?」に対して 「ありがとう、私は元気です。あなたはどうですか?」と答えることができます。
- Fill Mask: これらのモデルは、テキストのギャップを埋めるように学習されています。例えば、「パリはフランスの <ギャップ> である」のギャップは「首都」で埋められる可能性が高いと予測することができます。
- 質問応答: これらのモデルは、特定の文脈に関する質問に答えることができます。例えば、文脈が「私の名前はインゴで、ヒューストンに住んでいます」で、質問が「どこに住んでいますか?」の場合、モデルは「ヒューストン」という答えを生成します。
- 要約:これらのモデルは、長いテキストを短いテキストに要約するように学習されています。例えば、ウィキペディアの完全な記事を短い段落に変換することができます。
- テキスト2テキスト生成:これらのモデルは、あるテキストを別のテキストに変換するように学習されています。例えば、モデルは「文法を修正してください。この文のの文法は正しくないです」という文を「この文の文法は正しくないです」に変換することができます。
- テキスト分類: これらのモデルは、新規文書に対して最も可能性の高いクラスを予測するように学習されています。例えば、感情分類モデルは感情が「ポジティブ」である可能性が高いか「ネガティブ」である可能性が高いかを予測することができます。
- テキスト生成: これらのモデルは、特定のテキストを次の単語、または次の単語で拡張するように学習されています。例えば、モデルは「昔、暗い森に邪悪な人が住んでいました…」の次の単語が「魔女」であると予測することができます。
- トークン分類: これらのモデルは、すべての入力トークンのタイプを予測するように学習されています。このようなモデルは、例えば、固有表現の認識や品詞のタグ付けに使用することができます。
- 翻訳: これらのモデルは、ある言語から別の言語に翻訳するように学習されています。例えば、「私は機械学習が大好きです」をドイツ語の「Ich liebe maschinelles Lernen」に翻訳することができます。
- ゼロショット分類: これらのモデルはテキスト分類モデルですが、事前に定義されたクラスで学習されています。代わりに、プロンプトがモデルに送信されたときにのみクラスが定義されます。例えば、「ラップトップが壊れています。できるだけ早く交換品が必要です」というテキストを「緊急」および「非緊急」クラスとともにモデルに送信すると、「緊急」という結果が得られます。しかし、同じテキストを「ソフトウェア」と「ハードウェア」のクラスと一緒に送信することもでき、同じ汎用モデルから「ハードウェア」という結果が得られます!ゼロショット分類は、生成AIタスクの中でも特に魅力的なタスクのひとつであることは間違いありません。
考えてみると、これらのタスクタイプの一部は、他のタスクタイプの特殊化と見ることができます。多くの場合、その境界はやや流動的です。例えば、翻訳タスクをテキストからテキストへの生成タスクとして扱うことができます。要約も同様です。あるいは、テキスト分類でさえ、テキストからテキストへの生成モデルで解決できると言えます。または、テキスト生成モデルを使用することもできます。出力テキストや予測される次の単語は、可能性のあるクラスという非常に単純なものでしかありません。
同様に、テキスト生成は、マスクとも呼ばれるギャップが文末にある塗りつぶしマスクの特殊なケースに過ぎないと言えます。あるいは、会話モデルはテキスト生成のユースケースと見なすこともでき、そこでは答えの最初が次の単語を予測するために別のテキスト生成実行に供給されます。
これはまた、基礎モデルが非常に強力である理由と、同じモデルがこれらの多少関連するタスクの1つまたはいくつかを解決するためにどのように微調整できるかを説明します。これらのタスクタイプのいくつかは非常に似ていますが、Generative Modelsエクステンションでも別々のタスクとオペレータとして保持することにしました。これにより、これらのタスクタイプを使用した新規ユースケースを考えることができます。また、同じ用語がHuggingfaceポータルで使用されているため、モデルを識別しやすくなります。
したがって、Generative Modelsエクステンションでは、タスクタイプごとに1つのオペレータがあります。それぞれのオペレータは対応するモデルタイプでのみ動作し、時には特別なプロンプトや入力形式を必要とします。詳細については、各オペレータのチュートリアルプロセスと製品ドキュメントを参照してください。
Huggingfaceポータル上でモデルのタスクタイプを確認することができます。
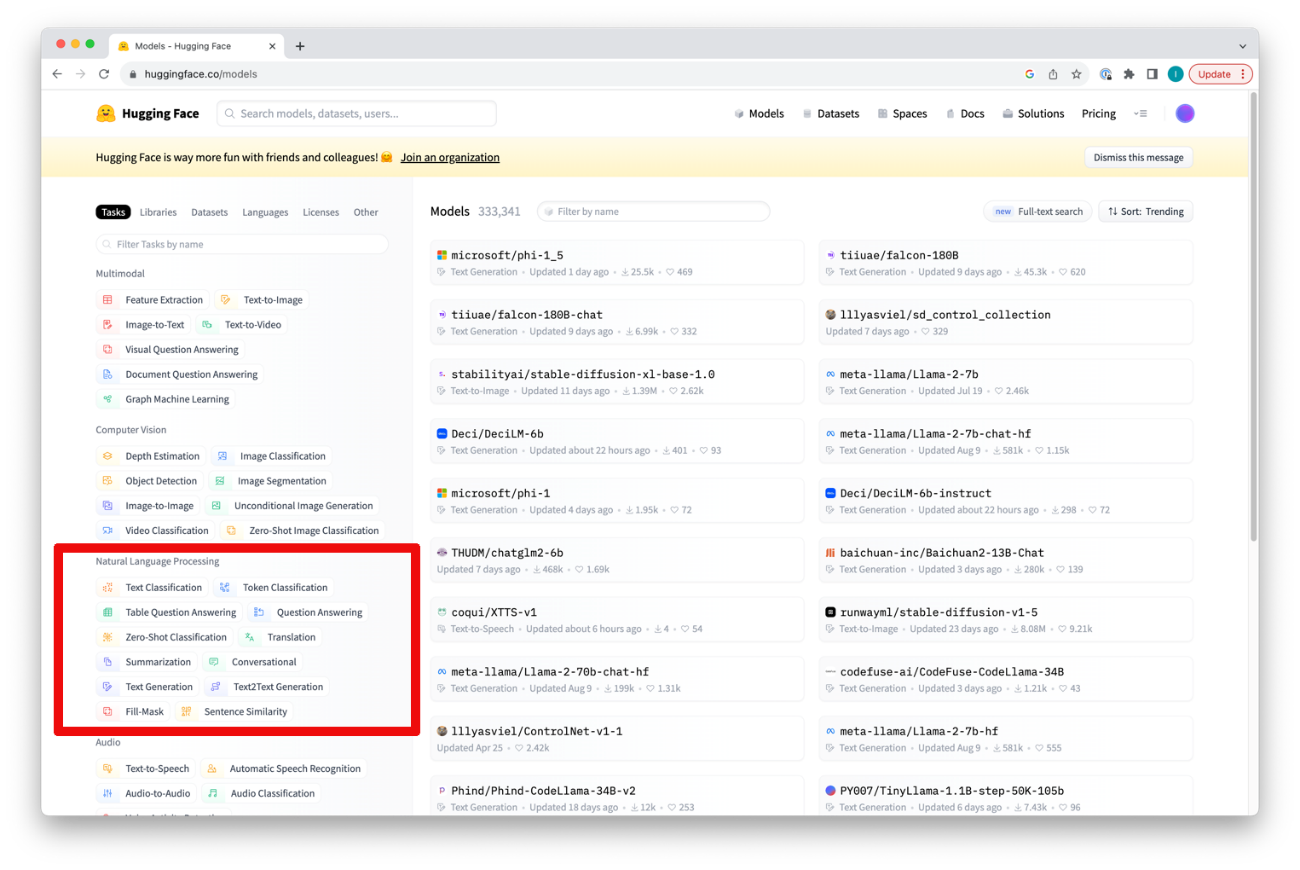
タスクをクリックすると、そのタスクタイプをサポートしているすべてのモデルが表示されます。右上のソートとフィルタリングの設定を変更することができます。現在、Generative ModelsエクステンションはSentence SimilarityとTable Question Answeringを除く、自然言語のすべてのHuggingfaceタスクタイプをサポートしていることに注意してください。
モデルをクリックした後、そのモデルカードで特定のモデルのタスクタイプを確認することもできます。
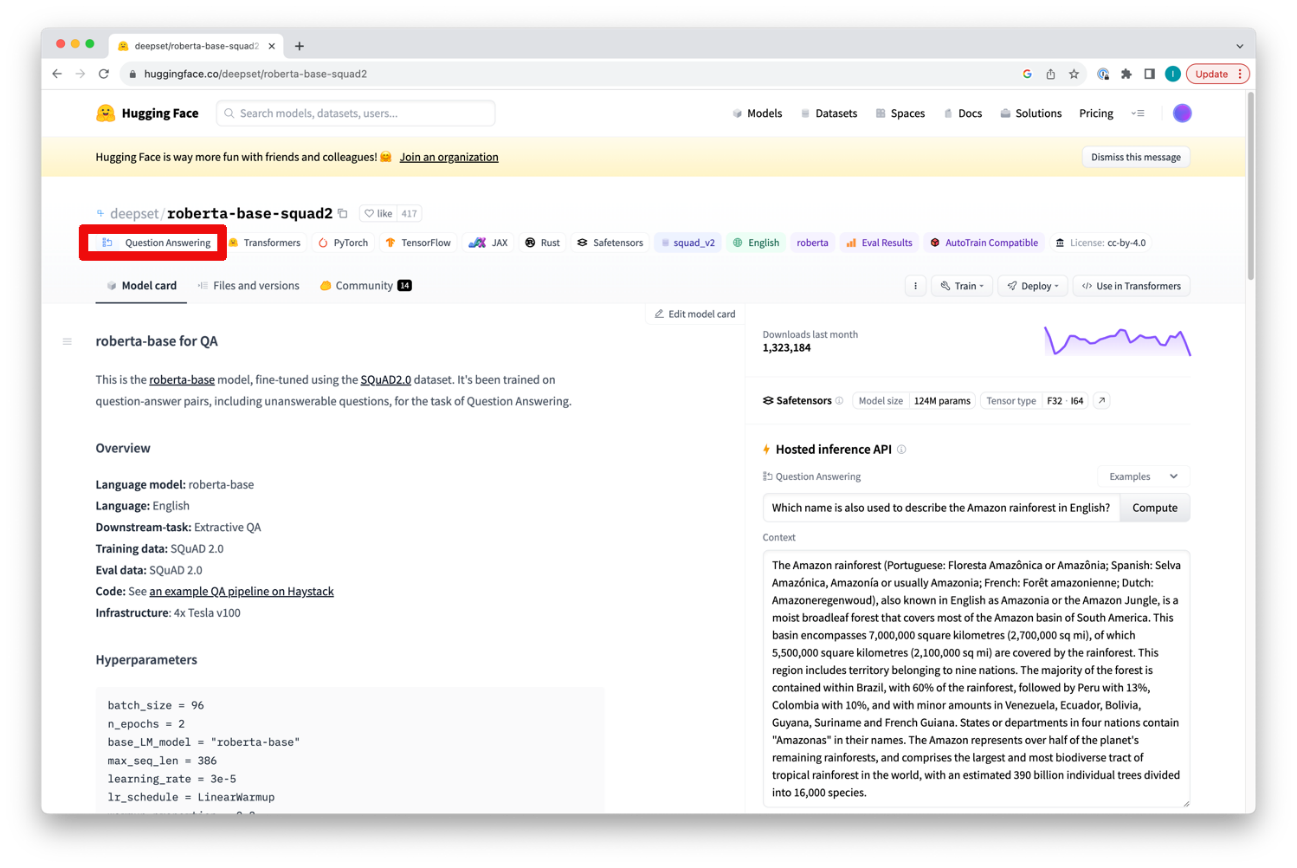
ここでは簡単な例として、英語からオランダ語に文章を翻訳する小さな翻訳モデルをダウンロードします。英語の文章を含むデータセットを提供し、モデルは結果としてオランダ語の翻訳を作成します。これらの翻訳は新規の列として追加され、以下のオペレータのパラメータとして希望する名前を指定します。
基本的なプロセス設定は次のようになります。
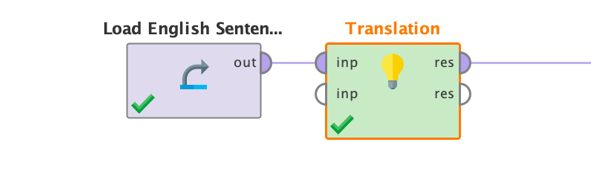
この場合、入力データは単に英語の文章を含む1列のデータセットです。
他のほとんどのRapidMinerモデルとは異なり、Apply Modelオペレータは使用できませんが、LLMを使用するための特別なタスクオペレータを使用する必要があります。その理由は、Huggingfaceからモデル名を指定してダウンロードすることや、RapidMinerの外部でモデルの学習や微調整を行うことができ、RapidMinerのプロセス内でモデルを使用するためにストレージディレクトリを指定することができるからです。
Generative Modelsエクステンションのオペレータを確認すると、「Tasks」というフォルダがあり、サポートされている各タスクのすべてのアプリケーションオペレータが含まれています。ここでは言語翻訳の問題を解決したいので、Translationオペレータを使用しました。しかし、他にもたくさんあります。各オペレータには、簡単な例を使用してその使用方法を示すチュートリアルプロセスが付属しています。
Translationオペレータに戻ります。オペレータは単にデータセットを入力として受け取ります。タスクオペレータにも2つ目の入力ポートがあることにお気づきでしょうか。これは、パラメータで指定する代わりにローカルストレージフォルダをモデルに使用する場合に使用します(以下を参照)。オペレータは任意のデータテーブルを最初の入力として受け取ります。オペレータの結果は、元の入力データに加えて、プロンプトパラメータに基づいてクエリされたモデルの結果を含む追加列となります。この例では、この追加列には英語の入力テキストのオランダ語訳が含まれます。
各タスクオペレータはモデルディレクトリオブジェクトも2番目の結果として出力します。これは、例えば、モデル適用後にDelete Modelオペレータでモデルディレクトリを削除したい場合に便利です。この出力は、a) 2番目の入力としてモデルディレクトリを提供し、b) 「use local model」パラメータをオンにした場合のみ生成されます(詳細は下記を参照)。しかし、多くの場合、希望するモデル名をパラメータとして指定するだけで、ローカルストレージフォルダの扱いについて心配する必要はありません。このことについては、後でDownload Modelオペレータについて説明します。
Translationオペレータのパラメータを見てみましょう。
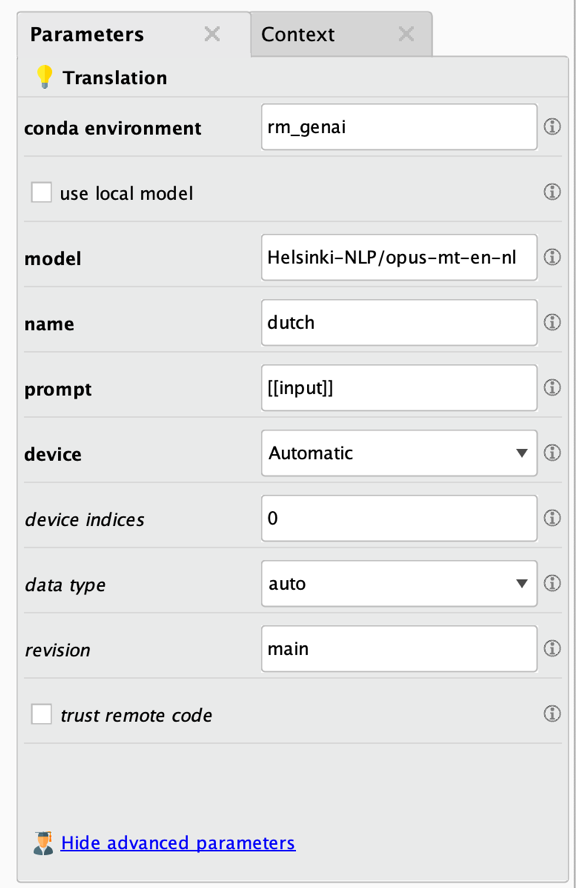
太字の最初のパラメータが最も重要なパラメータです。以下はパラメータの説明です。
- Conda環境: 詳細については上記を参照してください。インストール手順に従った場合、このパラメータを変更する必要はありません。必要なパッケージをすべて別の名前の環境にインストールする場合にのみ変更します。
- ローカルモデルの使用: プロジェクトやファイルシステムのディレクトリに基づいてローカルモデルを使用するか、Huggingfaceポータルからモデルを使用するかを示します。ローカルモデルを使用する場合、すべてのタスクオペレータは2番目の入力としてモデルディレクトリを参照するファイルオブジェクトを必要とします。このパラメータが選択されていない場合、以下の「model」パラメータにHuggingfaceポータルから取得した完全なモデル名を指定する必要があります。
- モデル: オペレータが使用するHuggingfaceポータルのモデルです。「use local model」パラメータが選択されていない場合のみ使用されます。モデル名はHuggingfaceポータルの各モデルカードにあるような完全なモデル名である必要があります。大きなモデルを使用すると、数ギガバイトのデータをダウンロードすることになり、モデルはローカルキャッシュに保存されますのでご注意ください。詳しくはDownload Modelオペレータのセクションをご覧ください。
- 名前: 結果として作成される新規列の名前です。
- プロンプト: モデルのクエリに使用されるプロンプトです。入力データ列の値を[[column_name]]で参照できることに注意してください。プロンプトの前に「Translate to Dutch: [[column_name]]」のようなプロンプト接頭辞を付けて、モデルに何をすべきかを指示する必要があるかもしれません。
- デバイス: モデルのアプリケーションを実行する場所です。GPU、CPU、AppleのMPSアーキテクチャのいずれかです。Automaticに設定すると、トレーニングはGPUが利用可能であればGPU(またはMチップアーキテクチャのMacOSシステムの場合はMPS)を優先し、利用できない場合はCPUにフォールバックします。
- デバイスインデックス: 複数のGPUがあり、計算がGPU上で行われるように設定されている場合、このパラメータで使用するGPUを指定できます。デバイスのカウントは 0 から始まります。デフォルトの「0」は、シス テムの最初の GPU デバイスが使用されることを意味し、「1」の値は 2 番目の GPU デバイスを意味し、以下同様となります。カンマで区切ったデバイスインデックスのリストを指定することで、複数のGPUを利用することができます。例えば、GPUが4つあるマシンで、4つすべてを使用する場合は「0,1,2,3」を使用できます。RapidMinerはデータ並列計算を行うので、モデルは各GPUに完全にロードされるのに十分小さくなければならないことに注意してください。
- データ型: モデルをロードするデータ型を指定します。精度を低くすると、メモリ使用量を減らすことができますが、場合によっては精度が若干低くなります。「auto」に設定すると、データ精度はモデル自体から得られます。モデルによっては複数のバージョンや「revision」があり、浮動小数点精度が低いモデルがすでにダウンロードされている可能性があることに注意してください。
- リビジョン: 使用するモデルのバージョンです。デフォルトは「main」です。この値には、Huggingface gitリポジトリ内のモデルのブランチ名、タグ名、またはコミットIDを指定できます。各モデルで可能なリビジョンは、Huggingfaceのモデルカードのファイルセクションで見つけることができます。
- リモートコードの信頼: モデリング、設定、トークン化、あるいはパイプラインファイルで実行されるカスタムコードを許可するかどうかを指定します。このオプションはご使用のローカルマシン上でコードを実行するため、信頼でき、コードを読んだモデルに対してのみ true に設定する必要があります。
すべてのパラメータを正しく設定した後、ワークフローを実行すると、元のデータセットに加え、指定した名前の列が追加されます。この列には、必要な翻訳が含まれています。
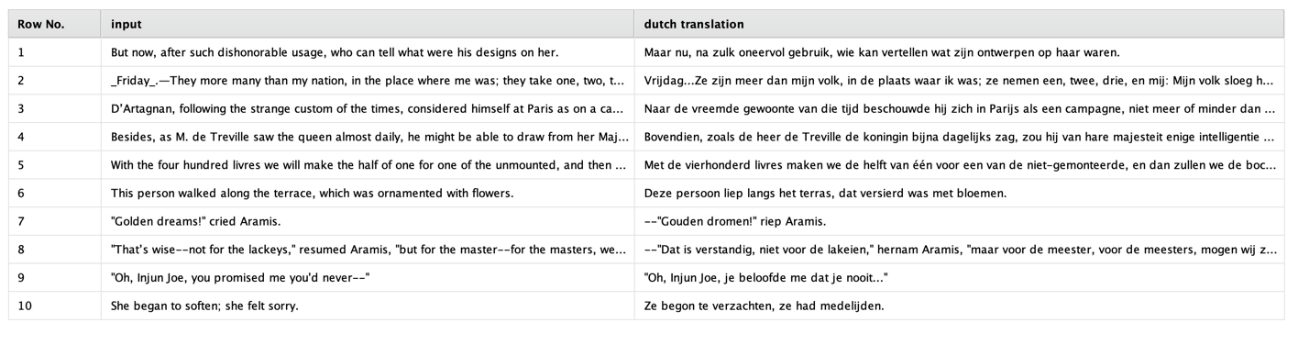
オランダ語を話せない人のために言っておくと、これらの翻訳はかなり正確です。
重要なパラメータとして、「prompt」パラメータについて説明する必要があります。プロンプトは可変であり、既存のデータ列の値を1つまたは複数含めることができます。つまり、入力データの各行に対して1つのプロンプトをモデルに送り、その結果を新規列に追加します。また、特定のプロンプトは他の列の値にも依存するため、結果は行ごとに異なる可能性があります。
例を見てみましょう。ここでは英語からオランダ語への翻訳練習にとどまります。「Helsinki-NLP/opus-mt-en-nl」という特別な翻訳モデルを使用しました。「Helsinki-NLP/」を含む完全なモデル名を使用する必要があることに注意してください。このモデルはすでに英語からオランダ語に翻訳できるように微調整されています。サイズは300Mbほどで、うまく機能します。しかし、ChatGPTのような大きなモデルとは対照的に、たった1つの仕事しかしていません。
いくつかのモデルでは、プロンプトで何をすべきかを指示する必要があります。これは、複数のタスクを解決するために微調整されたモデルを使用する場合に重要です。この場合、「Translate to Dutch: …」のようなプロンプトを記述し、その後に翻訳するテキストを続けます。英語の原文が「input」という名前の列に格納されているとします。対応するプロンプトは「Translate to Dutch: [[input]]」となります。
このように、プロンプトの一部として2つの括弧で囲むことで、データ列の値を参照することができます。このようにして、「What is the GDP of [[country]]?」や 「What is the capital of [[state]]?」のようなプロンプトを書くことができます。
この例で使用しているOpusモデルでは、プロンプトの前に何も書く必要はありません。つまり、モデルが実行できる唯一のことは、英語からオランダ語への翻訳を作成することだからです。つまり、プロンプト全体は単に「[[input]]」となります。
重要: このオペレータやタスクオペレータを、例えば「Finetune Text2Text Generation」オペレータを使用して自分で微調整したモデルに使用する場合、プロンプトは微調整中に指定したプロンプト接頭辞で始まる必要があります。RapidMinerオペレータのデフォルトは「Translate RMIn to RMOut:」です。このプロンプト接頭辞の後に処理するテキストを続ける必要があります。このテキストも[[column]] 形式を使用して他の列から取得することができます。例: 「Translate RMIn to RMOut: [[english_texts]]」
次のセクションに移る前に、ディレクトリに保存されたローカルモデルを使用するときに、タスクオペレータを使用する方法についても簡単に見てみましょう。このモデルは以前にダウンロードされたものでも、微調整の結果でもかまいません。必要であれば、ローカルにモデルをダウンロードして保存する方法を次のセクションで学習します。ローカルモデルを使用するワークフローは次のようになります。
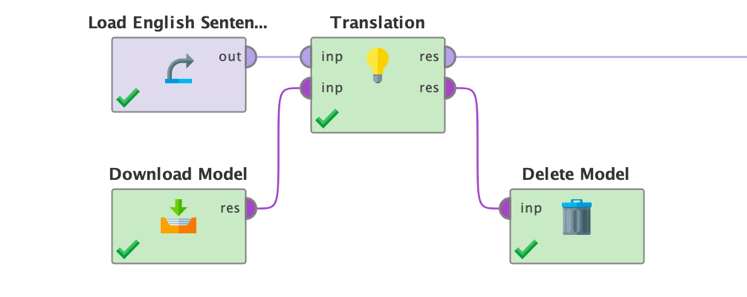
一般的に、Generative Modelsエクステンションのすべてのタスクオペレータは、この翻訳例で使用されているものとよく似た働きをします。各タスクオペレータがどのように動作するかは、製品内のオペレータドキュメントや、各タスクオペレータに付属するチュートリアルプロセスを参照してください。先に進む前に、タスクオペレータのチュートリアルプロセスで少し試してみることをお勧めします。そうすることで、大規模言語モデルがどのように動作するかをより深く理解することができます。
HuggingFaceからモデルをダウンロード
おそらく、すべてのタスクオペレータのモデルパラメータとしてフルネームを使用してモデルを簡単に参照できることにお気づきでしょう。しかし、バックグラウンドでは何が起こっているのでしょうか? タスクオペレータはモデルをHuggingfaceが管理するローカルキャッシュに自動的にダウンロードします。そこから使用され、同じモデルを使用して同じタスクオペレータを複数回実行しても、モデルのダウンロードは最初の1回だけです(キャッシュから削除されるたびに再度ダウンロードされます)。
これにより、タスクオペレータは非常に使いやすくなり、例えば、RapidMinerのReal-Time Scoring Agentに接続されたリモートジョブエージェントにワークロードを分散させることも簡単になります。
ダウンロードされキャッシュされたモデルは、RapidMinerのリポジトリではなくファイルシステムに保存されることに注意してください。これには複数の理由(サイズ、フォルダ構造とモデルの複雑さ、バージョン管理オプションの欠如など)がありますが、最も大きな理由は、他の場所やサードパーティから作成された(微調整された)モデルを使用できることです。タスクオペレータのパラメータとしてモデル名を使用するときはいつでも、これらすべては表示されないため、心配する必要はありません。
しかし、モデルをダウンロードして特定のロケーションに保存する必要がある場合もあります。これを行う最も重要な理由は、ダウンロードしたモデルを微調整の基礎として使用するためです。これについては後で詳しく説明します。しかし、(かなり大きくなる可能性のある)これらのモデルをローカルに保存する場所を単に制御する必要がある場合もあります。
これこそ、Download Modelオペレータが行うことです。必要なことは、Huggingfaceで使用されているモデルのフルネームを使用してモデルパラメータを設定することだけです。Huggingfaceのウェブポータルのモデルカードのトップにある完全なモデル名を入力するだけで、Huggingfaceのどのモデルでも使用することができます。
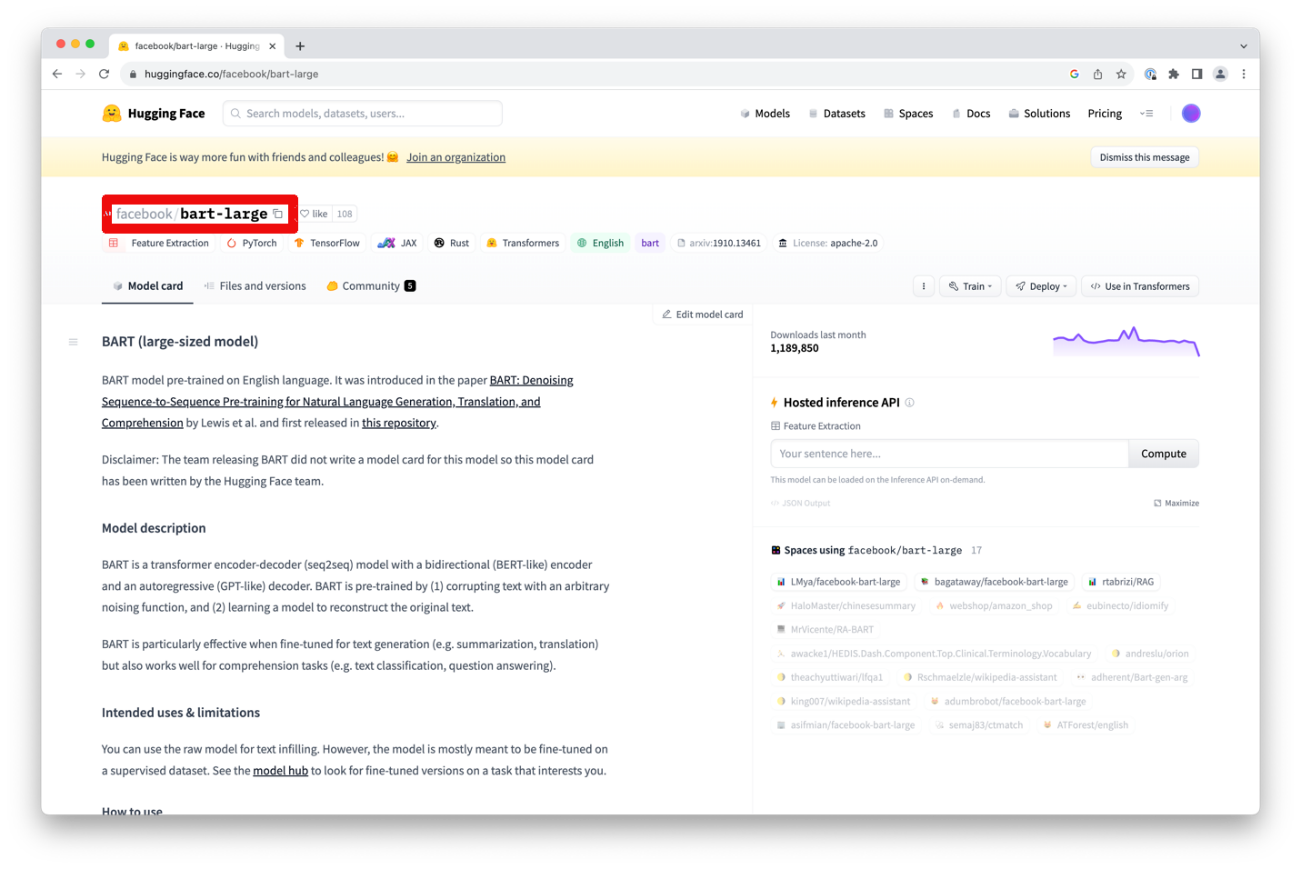
この例では「facebook/bart-large」のように、単に「bart-large」ではなく、完全な名前を指定する必要があることに注意してください。名前の横にある小さなコピーアイコンをクリックすると、完全な名前をクリップボードにコピーすることもできます。
最後に、モデルを保存するディレクトリを指定します。このディレクトリはRapidMinerプロジェクト内(推奨)またはローカルファイルシステム内のいずれかにあります。「storage type」パラメータを使用して、使用する場所のタイプを指定できます。また、オペレーティングシステムの一時ディレクトリに保存することもできます。いずれにせよ、オペレータは実行時にモデルをダウンロードし、指定されたロケーションに格納します。
一時ディレクトリを使用することは迅速かつ簡単であり、チュートリアルのワークフローにもこのメカニズムを使用していますが、可能な限りモデルの保存場所を管理し、使用しなくなったモデルをクリーンアップしたいと思うかもしれません。そうしないと、このダウンロードオペレータを適用するたびに、ファイルシステムにモデルの新規コピーが作成されることになります。前述したように、大規模言語モデルは非常に大きくなる可能性があります。このようなモデルフォルダを整理する1つの方法として、後述するDelete Modelオペレータがあります。
これに関するもう一つの注意事項: タスクオペレータやDownload Modelオペレータを複数回実行した場合、ダウンロードの重複を避けるために、ダウンロードされたモデルは自動的に~/.cache/huggingface/hubにキャッシュされます。キャッシュにモデルを保存する必要がなくなった場合、時々ファイルシステムのキャッシュを削除することをお勧めします。
Download Modelオペレータは非常に使いやすく、パラメータもわずかです。
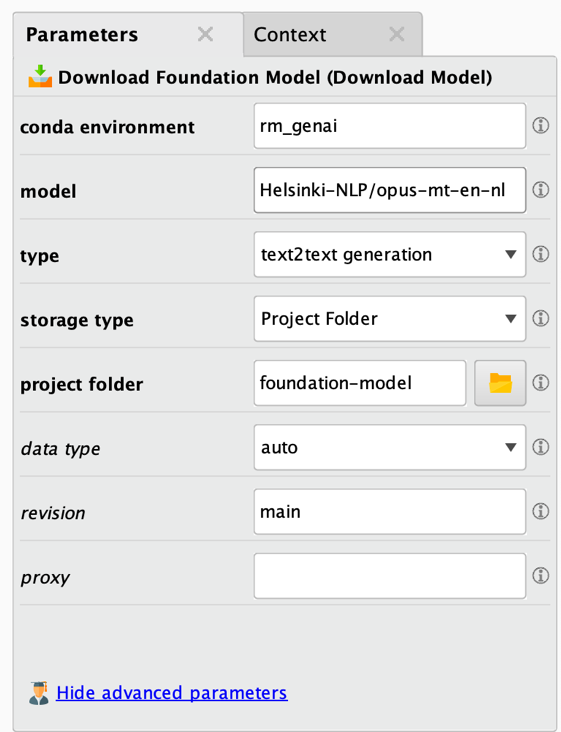
前述したように、一番上の太字のパラメータは最も重要なパラメータです。すべてのケースで変更/定義する必要があります。以下はパラメータの説明です。
- Conda環境: このダウンロードタスクに使用されるConda環境です。詳細はエクステンションのドキュメントを参照してください。
- モデル: ダウンロードされるモデルの完全な名前です。多くの場合、基本または基礎モデルですが、特定のタスクのためにすでに微調整されたモデルであることもあります。大きなモデルを使用すると、数ギガバイトのデータをダウンロードすることになりますのでご注意ください。
- タイプ: このパラメータは、モデルとそのタスクの正しいタイプを設定する必要があります。これを怠ると、予期しない結果が出たり、実行に失敗したりする可能性が高くなります。
- ストレージタイプ: 大規模言語モデルの保存場所を指定します。プロジェクト/リポジトリ内のフォルダ、ファイルシステムのフォルダ、または一時フォルダのいずれかに保存します。
- プロジェクトフォルダ: ダウンロードしたモデルが保存されるRapidMinerプロジェクトまたはリポジトリのディレクトリです。モデルが大きい場合、数ギガバイトの容量が必要になることに注意してください。このパラメータは、ストレージタイプが「プロジェクトフォルダ」に設定されている場合のみ表示されます。
- ファイルフォルダ: ダウンロードしたモデルが保存されるディレクトリです。モデルが大きい場合、数ギガバイトのディスク容量が必要になりますのでご注意ください。このパラメータは、ストレージタイプが「ファイルフォルダ」に設定されている場合のみ表示されます。
- データ型: モデルをロードするデータ型を指定します。精度を低くすると、メモリ使用量を減らすことができますが、場合によっては精度が若干低くなります。「auto」に設定すると、データ精度はモデル自体から得られます。モデルによっては複数のバージョンや「revision」があり、浮動小数点精度が低いモデルがすでにダウンロードされている可能性があることに注意してください。
- リビジョン: 使用するモデルのバージョンです。デフォルトは「main」です。この値には、Huggingface gitリポジトリ内のモデルのブランチ名、タグ名、またはコミットIDを指定できます。各モデルで可能なリビジョンは、Huggingfaceのモデルカードのファイルセクションで見つけることができます。
- プロキシ: HTTPプロキシサーバーを使用する必要がある場合に使用します。
Download Modelオペレータは、プロジェクトまたはファイルシステム上のストレージディレクトリを参照するファイルオブジェクトを提供します。このファイルオブジェクトは、タスクオペレータや微調整オペレータ(以下を参照)の入力として使用することができます。以下のスクリーンショットをご覧ください。オペレータが出力する紫色のファイルに注目してください。
特定のタスクに対して正しいタイプのモデルを選択することが重要です (サポートされているすべてのタスクの説明は上記を参照)。ダウンロード中にタスクが正しく選択されていない場合、モデルが正しく動作しないか、まったく動作しない可能性があります。しかし、間違ったタスクが選択されていても、動作するモデルもあります。例えば、会話モデルの中には、テキストからテキストへの生成モデルとして使用する必要があるものもあります。残念ながら、どのタスクタイプが動作するかどうかを見分ける方法はありません。一般的に、モデルのタスクタイプはHuggingfaceポータルに正しく記載されていますが、問題が発生した場合は、別のタスクタイプを試して、問題が解決するかどうか確認する価値があるかもしれません。タスクオペレータのパラメータとしてモデル名を直接使用する場合、通常このような問題は発生しません。そのため、可能な限りこれを行うことをお勧めします。
Huggingfaceのいくつかのモデルは、Huggingfaceにログインしてからでないとダウンロードできません。そのようなモデルをダウンロードするには、Huggingfaceポータルでいわゆるトークンを作成する必要があります。このトークンはDownload Modelオペレータにディクショナリ接続形式で提供される必要があります。RapidMiner Studioの「接続」メニューから「Create Connection」を選択します。ダイアログで、タイプとして「Dictionary Connection」を選択し、任意の名前で保存します。作成後、「Add Entry」をクリックして新規キーと値のペアを追加する必要があります。左側のキーとして「トークン」を使用し、右側の値としてポータルで作成したHuggingfaceトークンの値を使用します。接続を保存します。モデルにアクセスするためにHuggingfaceトークンを提供する必要がある場合のために、この接続オブジェクトをDownload Modelオペレータへの2番目の入力として提供することができます。
| 接続 | キー | 値の説明 |
|---|---|---|
| Huggingface | token | ポータルで確認できる自身のHuggingfaceトークン。特定のモデルにアクセスするために必要となる場合があります。 |
トークンを必要とするモデルはタスクオペレータで直接使用することができないことに注意してください。しかし、上記のようにトークンをディクショナリ接続に提供することで、最初にモデルをダウンロードする必要があります。ただし、これが必要になることはほとんどありません。実際、多くの場合、一般的にDownload Modelを使用する必要はありません。モデルを明示的にダウンロードする必要があるのは、以下3つの状況のみです。
- モデルを微調整し、微調整オペレータの入力として提供したい場合。
- トークンを使用してモデルにアクセスしたい場合。この場合、トークンパラメータを提供し、トークンでダウンロードし、タスクオペレータの「use local model」パラメータをtrueに設定して、対応するタスクオペレータにローカルモデルを投入する必要があります。
- プロキシ経由でHuggingfaceにアクセスしたい場合。先ほどの方法で、Download Modelオペレータでプロキシ設定を指定する必要があります。そうすれば、タスクオペレータにモデルを投入することができます。
ローカルモデルのロード
ローカルファイルシステムにモデルをダウンロードした後、モデルの適用や微調整のために、後のワークフローでファイルシステムからモデルを再度ロードする必要があるかもしれません。この場合、Load Modelオペレータを使用します。これは単純に最初にダウンロードすることなく、ローカルフォルダを指するだけで、Download Modelオペレータによって提供されたものと同じファイル参照を作成します。このディレクトリ参照はタスクオペレータや微調整オペレータのいずれかに入力することができます。
オペレータのパラメータは非常にシンプルです。
- ストレージタイプ: 大規模言語モデルをロードする場所を指定します。プロジェクト/リポジトリのいずれかのフォルダ(推奨)か、ファイルシステムのフォルダからロードします。
- プロジェクトフォルダ: ダウンロードしたモデルをロードするRapidMinerプロジェクトまたはリポジトリディレクトリを指定します。このパラメータはストレージタイプが「プロジェクトフォルダ」に設定されている場合のみ表示されます。
- ファイルフォルダ: ダウンロードしたモデルをロードするディレクトリを指定します。このパラメータはストレージタイプが「ファイルフォルダ」に設定されている場合のみ表示されます。
ローカルモデルの削除
最後に、ファイルシステムからモデルをクリーンアップすることができます。これは、モデルが一度しか使われない場合や、一時的なストレージディレクトリが使われている場合に特に便利です。モデルディレクトリを削除するには、Delete Modelオペレータを使用します。このオペレータにはパラメータがありませんが、ローカルモデルで動作するこのエクステンションの他のすべてのオペレータによって予期または提供されるため、ファイルオブジェクトの入力としてモデルディレクトリを必要とします。
モデルの微調整
上記のように、大規模言語モデリングタスクにはそれぞれ複数のオペレータが存在します。また、各モデルタイプに対して同じ数の微調整オペレータが存在する可能性もあります。各微調整には独自のパラメータと入力データ形式が必要です。しかし、ほとんどの企業での微調整のユースケースは、テキスト間の生成、翻訳、テキスト分類というわずかなモデルタイプで解決できることが判明しました。このエクステンションでは、これらのタスクタイプそれぞれに微調整オペレータを提供します。
上記で、他のタスクタイプの多くは、これらのタイプの特別なケースと見なすことを見てきました。
遭遇する可能性のある他の微調整タスクは、ChatGPTのような会話モデルを微調整することです。このようなモデルは一般的に非常に大きく、実際に使用するには何百ものGPUを備えた特別なインフラが必要であるため、代わりにOpenAIのような微調整サービスを使用することが多いでしょう。これについては後ほどOpenAIのモデルに関するセクションで取り上げますが、今はHuggingfaceのモデルを使用して、テキストからテキストへの生成モデルをローカルで微調整することに焦点を当てましょう。
この微調整のためのGenerative Modelsエクステンションの使用は非常に簡単です。モデルを微調整する基本的な考え方は、開始点として大規模な事前学習済みモデルを使用し、そのモデルに特定のタスクのみを教えることです。この大規模な事前学習済みモデルは、基礎モデルとも呼ばれます。例えば、英語や日本語を含む複数の言語のテキストで事前学習されたモデルから始めることができます。この事前学習は、教師なしの方法で行われることが多く、例えば、大規模な文書からランダムな単語を抜き出し、欠けている可能性の高い単語でギャップを埋めるようにモデルを訓練します。
この基礎モデルは、それだけではある言語から別の言語へ翻訳することはできませんが、教師なしでの事前学習のおかげで、学習されたすべての言語に対して優れた統計モデルを備えています。
魔法のようなのは2番目のステップです。このステップは微調整と呼ばれます。
微調整のステップは、1つ以上の自然言語の基本を理解した事前学習された基礎モデルから始めます。そして、特定のタスクを解決する方法の例をいくつか示します。例えば、テキストからテキストへの生成モデルを次のように微調整することができます。
- 翻訳のペアを提供することで、ある自然言語から別の自然言語に翻訳します。
- 全文と短い要約のペアを提供することで、既知の言語でテキストを要約します。
- 原文と最適化されたバージョンのペアを提供することで、文法やライティング全般を改善します。
- テキストを事前に定義されたクラスにマッピングします。つまり、基本的にはテキスト分類タスクです。
- センチメントクラスにテキストをマッピングすることで、テキストのセンチメントを決定します(上記の特殊なケース)。
- コメントとソースコードのペアを提供することで、人間の要求に基づいてコードを記述します。
- 説明テキストとデザインの十分なペアを提供することで、自然言語の記述に基づいて3Dデザインを作成します。
- 他にもたくさんあります。
もうお分かりのように、また前にも述べたように、翻訳や要約といった他の特殊なタスクの多くも、テキストからテキストへの生成やテキスト生成のシナリオとして扱うことができます。
上記のタスクのいくつかでは、大規模言語モデルを使用する必要はないことに注意してください。テキスト分類と感情分析は、他の、より単純な機械学習アプローチで行うことができます。翻訳モデルの概念で解決できるユースケースの範囲がいかに広いかを示すために、上記のユースケースを追加しました。
また、テキストからテキストへの生成の対象は、必ずしも自然言語である必要はないこともお分かりいただけるでしょう。プログラミングコードや3D製品のデザインは、それ自体自然言語ではありません。つまり、上記のタスクのいくつかは、より抽象的な意味での「テキスト生成」タスクにすぎません。しかし、これが大規模言語モデルの力なのです。優れた基礎モデルから始めて、同じ基礎に基づいて多くのユースケースを解決できるように微調整することができるのです。
続ける前に、基礎モデルを構築してから微調整を行うという2段階のアプローチがなぜ強力なのかを説明しましょう。その理由は、使用言語に関する統計的な理解がすでにモデルに備わっているため、微調整に必要な学習例数が大幅に少なくなり、学習時間が短縮されるからです。基礎モデルの学習には、何百もの計算ノードと何千ものGPUが必要になる場合がありますが、モデルの微調整は、多くの場合、市販のハードウェアで合理的な時間内に行うことができます。
微調整オペレータの使用
上記の使用例で見たように、ほとんどの微調整タスクは、新規タスクのための追加学習例を含む入力データセットを必要とします。テキストからテキストへの生成タスクの例では、この入力データには少なくとも2つの列が必要です。1つは入力テキストとして使用される値を含む列、もう1つはその時点で生成タスクのターゲットテキストを含む列です。
利用可能な優れた翻訳モデルがあることはわかっていますが、ここでは先ほどの英語からオランダ語へのユースケースを続けます。ここでは、英語とオランダ語のテキストのペアを、他の多くの言語の中でこれらの言語について事前学習されているが、この特定の翻訳タスクについては事前学習されていないモデルに提供する例を使用します。このデータセットには2つの列しかありません。1つは英語の原文(入力)、もう1つはオランダ語の翻訳(ターゲット)です。
また、上述のように、Download Modelオペレータを使用て、Huggingfaceから「T5-base」のような基礎モデルをすでにダウンロードしたと仮定します。
そして、ダウンロードした基礎モデルの場所と同様にデータをFinetune LLM (Translate)オペレータに接続します。
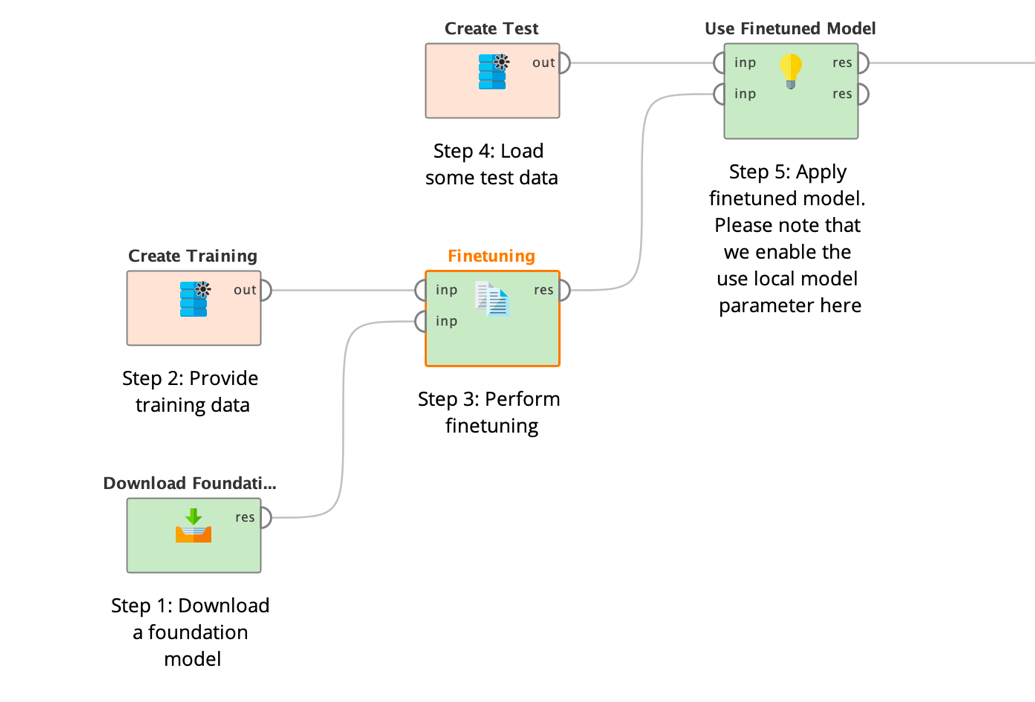
ご覧の通り、FinetuningオペレータはRapidMinerの他の多くの機械学習オペレータのようにモデルオブジェクトを生成するのではなく、大規模なモデルの内容を含むファイルディレクトリを生成します。モデルの保存に関する詳細は、Download Modelオペレータのセクションを参照してください。
ファイルオブジェクトは、その後アプリケーションオペレータ(上記のステップ 5)への入力として渡されます。以下のFinetuningオペレータの全パラメータを参照してください。
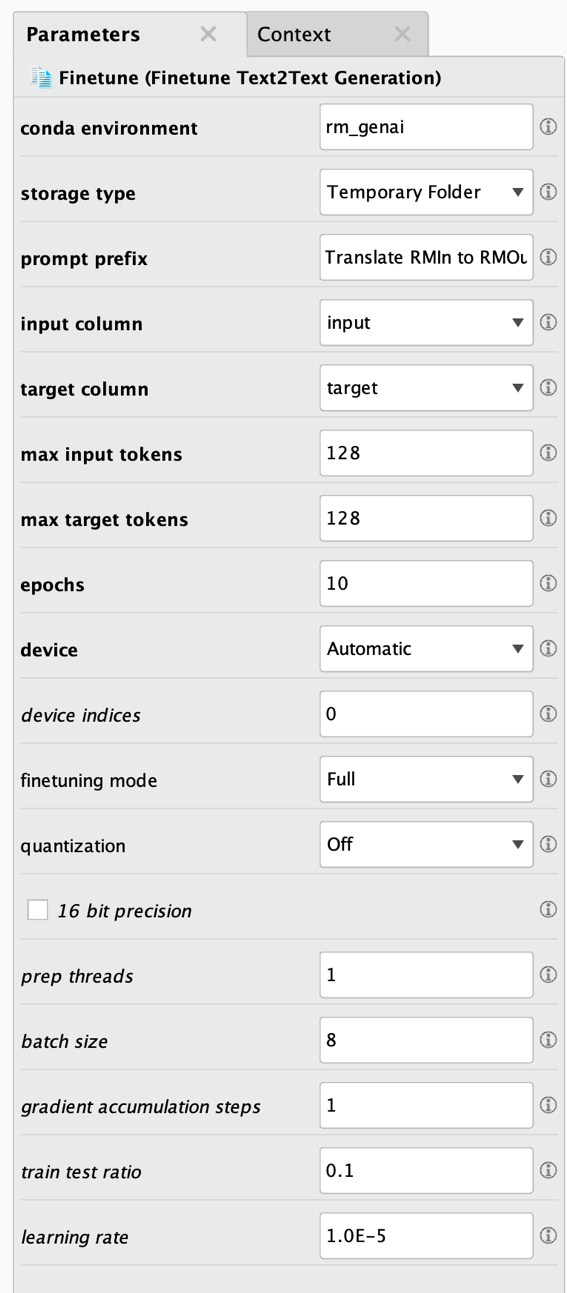
いつものように、一番上の太字のパラメータは最も重要なパラメータであり、すべてのケースで変更/定義する必要があります。以下はパラメータの説明です。
- Conda環境: このモデルタスクに使用されるConda環境です。詳細はエクステンションのドキュメントを参照してください。この環境には追加のパッケージがインストールされる場合があります。この詳細や、Pythonやこの環境に存在するパッケージのバージョン要件については、エクステンションのドキュメントを参照してください。通常、エクステンションをインストールしたときに作成した環境を使用します。Python、Numpy、Pandasがすべてインストールされていること、それ以外はインストールされていないこと、この3つのバージョンが正しいことを確認してください。
- ストレージタイプ: 微調整された大規模言語モデルが保存される場所を決めます。プロジェクト/リポジトリ内のフォルダ(推奨)、ファイルシステムのフォルダ、または一時フォルダのいずれかに保存します。
- プロジェクトフォルダ: RapidMinerのプロジェクトまたはリポジトリのディレクトリで、微調整されたモデルが保存されます。モデルが大きい場合、数ギガバイトの容量が必要になることに注意してください。このパラメータはストレージタイプが「プロジェクトフォルダ」に設定されている場合のみ表示されます。
- ファイルフォルダ: 微調整されたモデルが保存されるディレクトリです。大きなモデルの場合、数ギガバイトの容量が必要になることに注意してください。このパラメータは、保存タイプが「ファイルフォルダ」に設定されている場合のみ表示されます。
- プロンプト接頭辞: この接頭辞は微調整されたモデルに微調整のタスクを伝えるために、各入力の前に使用されます。こうすることで、「ドイツ語に翻訳:」や「これを要約:」、「文法を修正:」などの異なる接頭辞を使用して複数のタスクを解決できます。
- 入力列: 微調整の入力として使用する列の名前です。
- ターゲット列: この微調整のターゲットとして使用する列の名前です。これは翻訳タスクなので、モデルは入力列の値をターゲット列の値に翻訳する方法を学習しようとします。
- 最大入力トークン: 入力に許可される最大トークン数です。長いシーケンスは無視されます。数値を大きくすると実行時間が長くなるので、できるだけ小さい数値を使用するようにしてください。また、特定の最大トークン数でしか動作しないモデルもあることに注意してください。そのような制限の詳細については、Huggingfaceのモデルのドキュメントページを参照してください。
- 最大ターゲットトークン: 微調整されたモデルのターゲットまたは出力に許容される最大トークン数です。長いシーケンスは無視されます。数値を大きくすると実行時間が長くなるので、できるだけ小さい数値を使用するようにしてください。また、特定の最大トークン数でしか動作しないモデルもあることに注意してください。そのような制限についての詳細は、Huggingfaceのモデルのドキュメントページを参照してください。
- エポック: この微調整のためのエポック数です。通常、4~15の値が最良の結果をもたらします。
- デバイス: 微調整を行う場所です。GPU、CPU、またはAppleのMPSアーキテクチャのいずれかとなります。Automaticに設定すると、学習では、GPUが利用可能であればGPUを優先し、そうでなければCPUにフォールバックします。
- デバイスインデックス: 複数のGPUがあり、計算がGPU上で行われるように設定されている場合、このパラメータで使用するGPUを指定することができます。デバイスのカウントは 0 から始まります。デフォルトの「0」は、システムの最初のGPUデバイスが使用されることを意味し、「1」は 2 番目のGPUデバイスを意味し、以下同様となります。カンマで区切ったデバイスインデックスのリストを指定することで、複数のGPUを利用することができます。例えば、GPUが4つあるマシンで、4つすべてを使用する場合は「0,1,2,3」を使用できます。RapidMinerはデータ並列計算を行うため、モデルは各GPUに完全にロードできるほど小さくする必要があることに注意してください。
- 微調整モード: 完全な微調整を実行するか、微調整タスクを劇的に加速できるPEFT/LoRAを実行するかを示します。LoRAと対応モデルの詳細については、https://github.com/huggingface/peft を参照してください。
- Lora r: LoRAが使用する低ランク行列の次元です。ランクが低いほど更新行列が小さくなり、学習可能なパラメータが少なくなります。
- Lora alpha: LoRAが使用する重み行列のスケーリング係数です。
- Lora dropout: LoRA層のドロップアウト確率です。
- ターゲットモジュールモード: Noneに設定すると、PEFT/LoRAで微調整するモジュール(またはレイヤー)についての特定の定義は行われません。これは、PEFTがネイティブにサポートしているすべてのモデルに最適な設定です。Automaticに設定すると、すべての線形レイヤーの名前を自動的に抽出します。Manualに設定すると、ターゲットモジュール名をカンマ区切りで指定することができます。ログでモジュール名を含むモデルの構造を確認することができます。
- ターゲットモジュール: ターゲットモジュールモードがManualに設定されている場合のみ表示されます。ここにターゲットモジュール名をカンマ区切りで指定することができます。これらのモジュールはPEFT/LoRAで微調整されます。モジュール名を含むモデルの構造はログで確認することができます。
- 量子化: 量子化技術は、重みと活性度を8ビットや4ビットの整数のような精度の低いデータ型で表現することで、メモリと計算コストを削減します。これは、CUDA対応GPUを搭載したLinuxシステムでのみサポートされています。
- 16ビット精度: 32ビット学習の代わりに16ビット(混合)精度学習(fp16)を使用するかどうかを指定します。これはCUDA対応GPUを搭載したシステムでのみサポートされます。
- 前処理スレッド: データの前処理に使用する並列スレッド数です。
- バッチサイズ: この微調整のバッチサイズです。GPU数とバッチサイズと勾配累積ステップ数の積は、8の倍数である必要があります。
- 勾配累積ステップ: この微調整に使用する勾配累積ステップです。GPU数とバッチサイズと勾配累積ステップ数の積は、8の倍数である必要があります。
- トレインテスト比率: 微調整されたモデルのテストに使用される行の比率です。
- 学習率: この微調整の学習率です。
必須パラメータを設定した後、通常、不要な実行時間を減らすために、データとユースケースに基づいて、入力トークンとターゲットトークンの数を最小限に抑えます。その後、他のパラメータを最適化したり、様々なモデルタイプを試したりして、ユースケースに最適な結果を得ることができます。
このようなプロセスを実行した場合、トレーニングオペレータはまず追加パッケージが必要かどうかを確認し、必要な場合はダウンロードしてインストールします。微調整を開始するまでに時間がかかることがありますが、RapidMinerのログウィンドウで進行状況を確認することができます。今後の実行では、このダウンロードとインストールのプロセスは繰り返されません。
すべての準備が整った後、微調整が始まります。ここでもログウィンドウで進行状況を確認することができます。オペレータが完了すると、最終モデルが指定されたモデルディレクトリに保存されます。
他のすべての微調整オペレータも同じように動作することに注意してください。それらは、異なるパラメータやわずかに異なる入力データ形式が必要になる場合があります。その使用方法とどのようなデータを必要とするかについては、チュートリアルのプロセスを参照してください。
OpenAIを使用した生成AI
上記のように特化した、あるいは微調整されたローカルモデルを使用する代わりに、OpenAIによるChatGPTのような幅広い汎用モデルを使用することもできます。Generative ModelsエクステンションにはSend Promptというオペレータがあり、前述したタスクオペレータと全く同じように動作しますが、指定されたプロンプトに対する回答を得るためにChatGPTを使用します。
さらにすごいのは、ChatGPTなどのOpenAIのモデルを自分で微調整することもできるということです!これについてはこのセクションの後半で詳しく説明します。
OpenAIのアカウントが必要になることに注意してください。まだアカウントをお持ちでない場合は、ウェブサイトにアクセスして新規アカウントを作成してください。
APIキーも必要です。こちらで作成してください。
OpenAIでは無料で利用できるクエリの数が限られているため、すぐに制限に遭遇する可能性が高いです。OpenAIの課金ページで、さらに多くのリクエストを購入することができます。
OpenAIへの接続
前述のように、OpenAIポータルでAPIキーを作成する必要があります。このキーは、このエクステンションのすべてのOpenAIオペレータにディクショナリ接続の形式で配信する必要があります。
RapidMiner Studioの「Connections」メニューから「Create Connection」を選択します。ダイアログで、タイプとして「Dictionary Connection」を選択し、任意の名前で保存します。作成後、「Add Entry」をクリックし、新規キーと値のペアを追加する必要があります。左側のキーには「api_key」を、右側の値にはポータルで作成したOpenAI APIキーの値を使用します。接続を保存します。これで、この接続オブジェクトをすべてのOpenAIオペレータの入力として提供できるようになります。
| 接続 | キー | 値の説明 |
|---|---|---|
| OpenAI | api_key | OpenAI API キーは、OpenAIのユーザープロフィールで作成および確認できます。https://platform.openai.com/account/api-keysを参照してください。 |
OpenAIへのプロンプトの送信
アカウントを設定し、APIキーを取得し、対応する接続を設定した後、Send Promptオペレータの使用方法は非常に簡単で、上記のタスクオペレータのいずれかを使用する場合と非常によく似ています。主な違いは、Huggingfaceモデル名またはローカルモデルのディレクトリをOpenAIオペレーターへの入力として提供しないことです。ただし、OpenAIのどのモデルを使用するかを選択することはできます。独自の微調整モデルを使用したい場合は、ここでこれを指定することもできます。次に、OpenAIに送信できる入力データとプロンプトを指定するだけです。
パラメータもHuggingfaceタスクオペレーターに似ています。
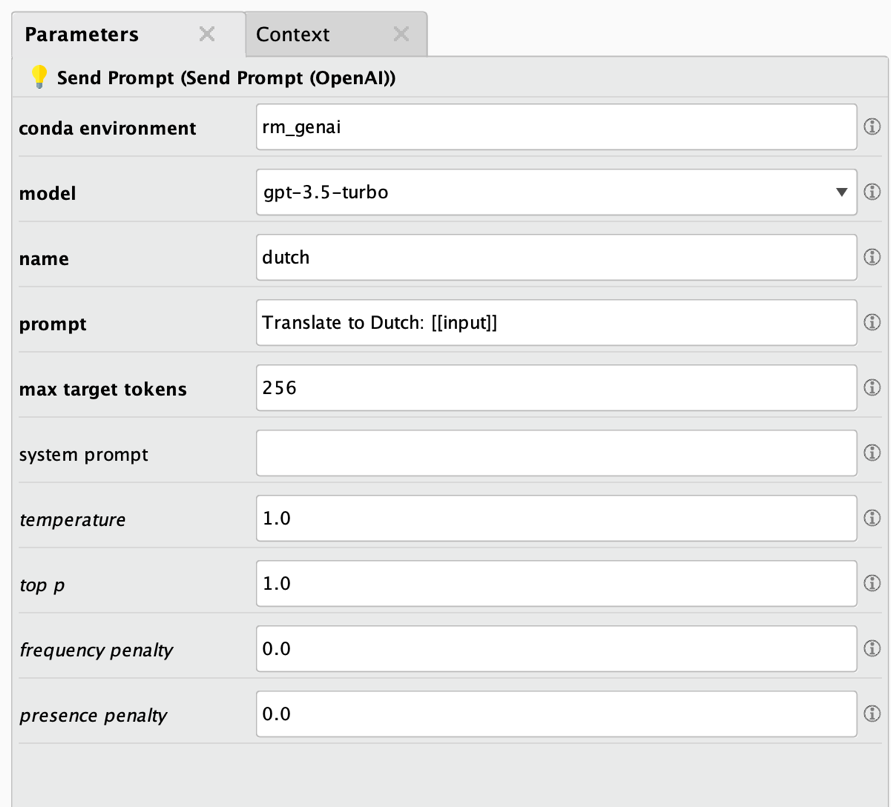
以下はその説明です。
- Conda環境: 詳細は上記を参照してください。通常、このエクステンションのオペレータで解決する微調整やダウンロード、その他のタスクに使用したものと同じ環境が使用されます。
- モデル: 使用するOpenAIのモデル名です。自身の微調整したモデルを使用したい場合は、ここにモデルIDを指定する必要があります。
- 名前: 結果として作成される新規列の名前です。
- プロンプト: モデルのクエリに使用されるプロンプトです。入力データ列の値を[[column_name]]で参照できることに注意してください。
- 最大ターゲットトークン: モデルが回答として生成するトークンの最大数です。
- システムプロンプト: 会話を開始するためにOpenAIに送信できる初期化プロンプトです。ChatGPTに「あなたは短い回答を好む事実に基づいたチャットボットです」など、特定のペルソナやスタイルを使用して回答させるためによく使用されます。
- 温度: 回答に使用されるランダム性を制御します。値を小さくすると、ランダムな回答が少なくなります。温度0は完全に決定論的なモデルの動作を表します。
- Top P: 核サンプリングによる多様性を制御します。0.5の値は、すべての可能性で重み付きオプションの半分が考慮されることを意味します。
- 頻度ペナルティ: これまでの回答における頻度に基づいて、新規トークンにどの程度のペナルティを課すかを指定します。
- 存在ペナルティ: これまでの回答における存在度に基づいて、新規トークンにどの程度のペナルティを課すかを指定します。モデルが新規トピックについて答える可能性を高めます。
そして、念のため、以前見たのと同じ翻訳タスクの結果を示します。
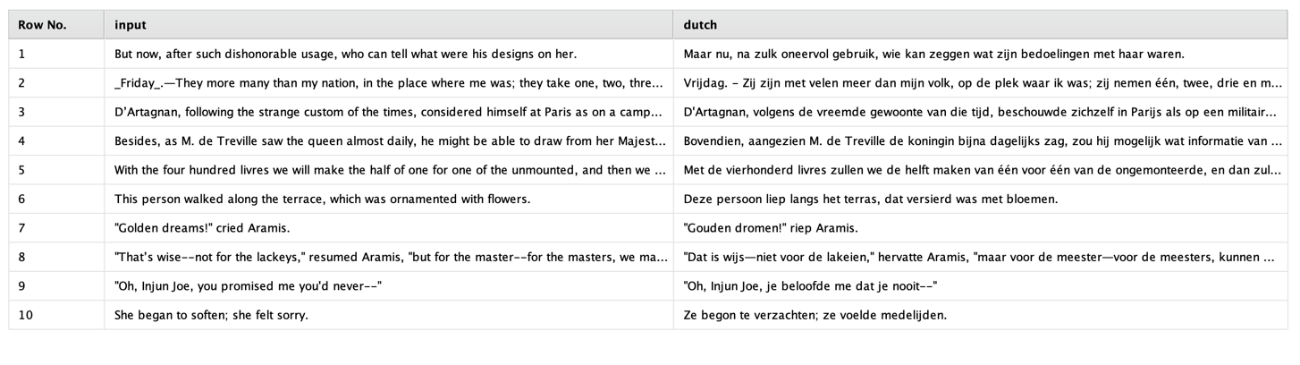
あなたはオランダ語は話せないかもしれませんが、結果は事前学習されダウンロードされたOpusモデルからの結果と同様の品質であることをお伝えしておきます。GPT-3.5やGPT-4のような強力な汎用モデルは確かに素晴らしいです。しかし、サイズが大きく、リソースを大量に消費します。そのため、Opusモデルのような、サイズがより小さく、リソースを節約できるモデルを常に代替案として検討することをお勧めします。
OpenAIでのモデルの微調整
OpenAIのGPTモデルは非常に強力で、すぐにさまざまなタスクを解決できますが、GPTモデルを微調整する必要が出てくるかもしれません。最初のステップはプロンプトエンジニアリングと呼ばれるもの、つまり望ましい結果を得るためにプロンプトを最適化することであることを覚えておいてください。
しかし、プロンプトエンジニアリングが失敗した場合、必要な出力がモデルにとって未知のものである場合、特別な回答構造が必要な場合、またはプロンプトが長すぎて扱いにくい場合などは、モデルを微調整することが最善の方法です。朗報は、RapidMinerのGenerative Modelsエクステンションのおかげで、ChatGPTのような1750億のパラメータモデルの微調整さえも数回クリックするだけで済むことです。
ここで少し単純なユースケースを使ってみましょう。GPTの回答の口調が気に入らないので、もう少し皮肉な口調を希望するとします。必要なのは、いくつかのクエリの例と希望する出力だけです。
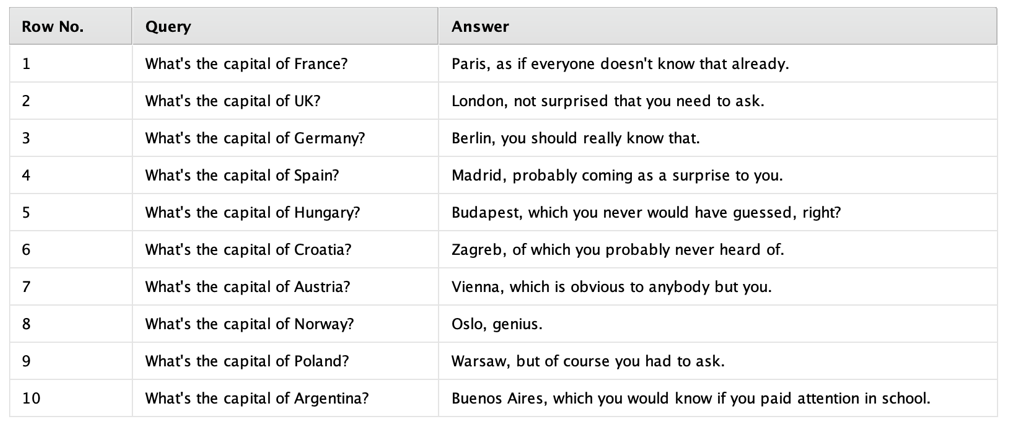
完璧です。こんな口調はよくありませんが、とりあえずはこれでいきましょう。このようなデータセットは、Finetune OpenAIオペレータに以下のように入力できます。
とても簡単です。あとは、このオペレータのパラメータをいくつか設定するだけです。
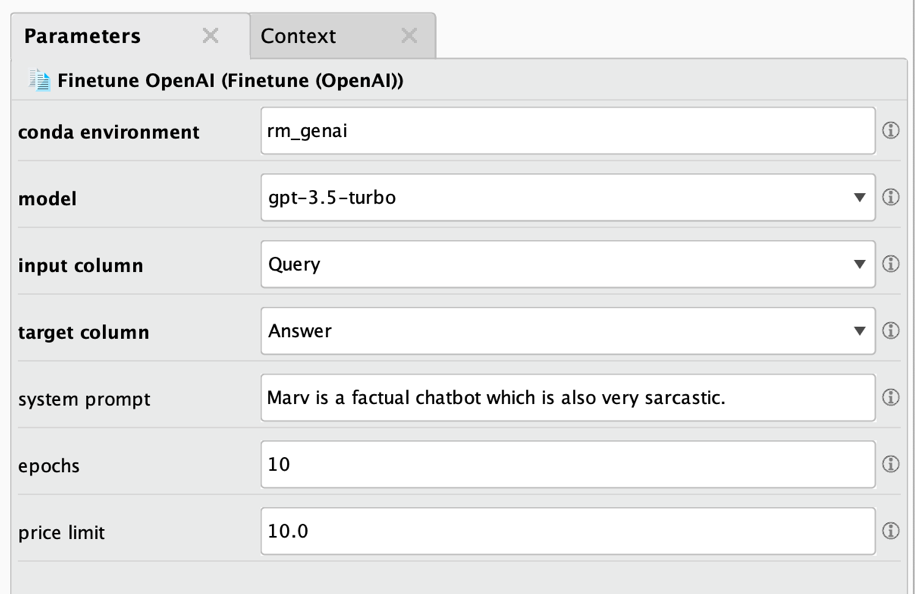
いつものように、以下で説明します。
- Conda環境: 詳細は上記を参照してください。通常、このエクステンションのオペレータで解決する微調整やダウンロード、その他のタスクに使用したものと同じ環境が使用されます。
- モデル: 使用するOpenAIのモデル名を指定します。このドキュメントを執筆している時点では、OpenAIモデルのうち微調整が可能なのはごく一部であること、また微調整したモデルを再度微調整することはできないことに注意してください。
- 入力列: クエリまたはプロンプトを含む列の名前です。
- ターゲット列: クエリまたはプロンプトに対する回答を含む列の名前です。
- システムプロンプト: 会話を開始するためにOpenAIに送信できる初期化プロンプトです。ChatGPTに「あなたは短い回答を好む事実に基づいたチャットボットです」など、特定のペルソナやスタイルを使用して回答させるためによく使用されます。
- エポック: 学習エポックの数です。通常、適切な値は 5 ~ 20 エポックです。数値が大きいと過剰適合につながる可能性がありますが、微調整ジョブの時間が長くなり、コストも高くなります。
- 価格制限: OpenAIは処理されたトークン1,000個ごとに微調整ジョブに課金します。最新の価格情報については、https://openai.com/pricingを参照してください。微調整が開始される前に、このオペレータは予想される合計価格を見積もります。その見積りがこの上限(米ドル単位)を超える場合、微調整は開始されず、コストがかかりすぎる微調整の実行を防ぐためにエラーが発生します。計算の詳細はRapidMinerのログウィンドウで確認できます。
このプロセスを実行すると、データがOpenAIにアップロードされ、微調整ジョブが投入されることに注意してください。これには時間がかかる場合があります。すべてがチェックされ、見積もりコストが定義された価格制限以下であれば、ジョブが開始され、OpenAIのクラウドインフラストラクチャ上で非同期に動作します。オペレータは以下のようなジョブ概要を返します。
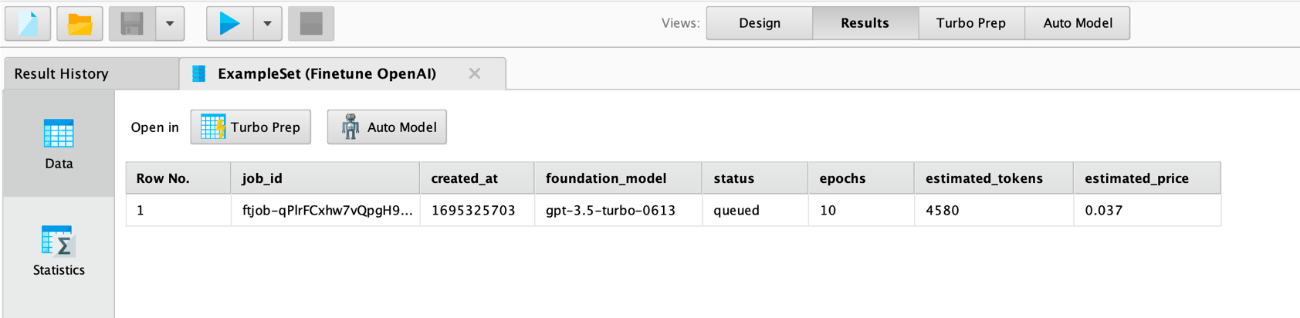
上記のjob_id列に注意してください。この列は微調整ジョブのステータスを取得することや、ジョブ終了後に微調整されたモデルのモデルIDを取得するためにも必要です。ジョブIDはRapidMinerのログにもあります。
あとはOpenAIの微調整が終わるまで待つだけです。使用した組織に関連付けられたアドレスにメールが届きます。このメールには、微調整したモデルを使用するために必要なモデルIDも含まれています。
別の方法として、Check Job StatusオペレータにジョブIDを入力し、微調整ジョブの状況を確認することもできます。
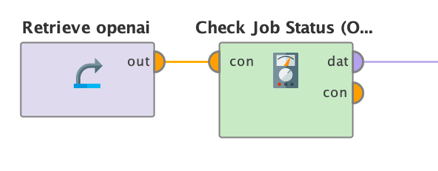
このオペレータのパラメータは1つだけです。上図のFinetune OpenAIオペレータの結果であるジョブIDです。これを実行すると、ジョブに関する情報と、ジョブが成功したかどうかの情報が得られます
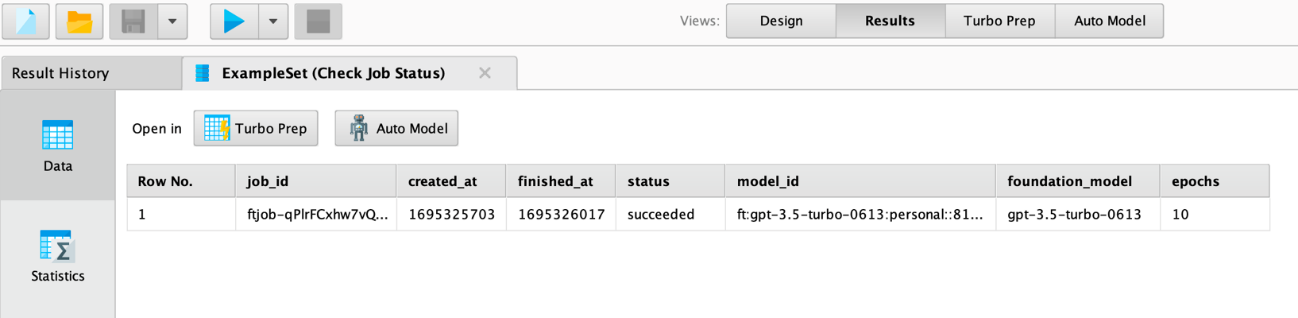
ご覧の通り、投入したジョブは成功しました。この場合、モデルIDの値も得られますが、それ以外の場合は空です。このモデルIDはSend Promptオペレータの「model」パラメータに使用されます。
この他にも役に立つオペレータが2つあります。Get ModelsとDelete Modelです。Get Modelsはこれまでに組織で微調整したすべてのモデルを表示します。結果にはモデルのIDも含まれます。また、Delete ModelはRapidMinerワークフローでモデル管理を調整できるように、モデルIDを取得してモデルを削除します。
Send Promptの次に、OpenAIのプレイグラウンド(https://platform.openai.com/playground)で微調整したモデルを検査することもできます。微調整されたモデルがいくつかのクエリにどのように応答するかを次に示します。
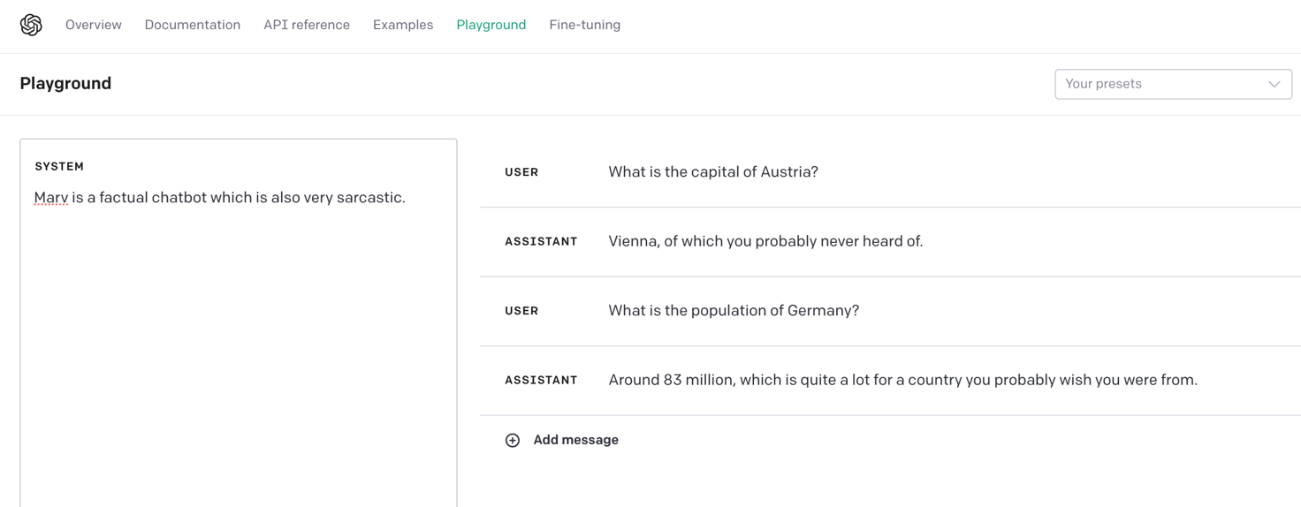
微調整されたChatGPTは、通常よりも皮肉っぽい口調と言っても過言ではありません。
ボーナス: プロンプトでのデータの強化
微調整を必要とせずに、特にChatGPTなどの強力な汎用会話モデルと組み合わせて、大規模言語モデルをデータに使用する方法を理解するのに苦労することがあります。最も有用なユースケースの1つは、既存のデータを追加情報で強化することです。
1つの列に国名が含まれるテーブルがあるとします。そして、その国のGDP、人口、首都などの列を追加したいとします。もちろん、ウェブ検索をして自分で情報を追加することもできますが、これはより簡単に(特に、数千行または数百万行に対してこのような処理を行う必要がある場合にはより効率的に)行うことができます。大規模言語モデルが役に立ちます。
Huggingfaceモデルをこれらのタスクの一部に使用することもできますが、実際にはChatGPTのようなモデルが威力を発揮する分野です。
Huggingfaceのタスクオペレータ、またはOpenAIのSend Promptオペレータをデータ上で使用するだけで、このエクステンションの動的プロンプトを利用することができます。例えば、Send Promptオペレータの使用は次のように簡単です。
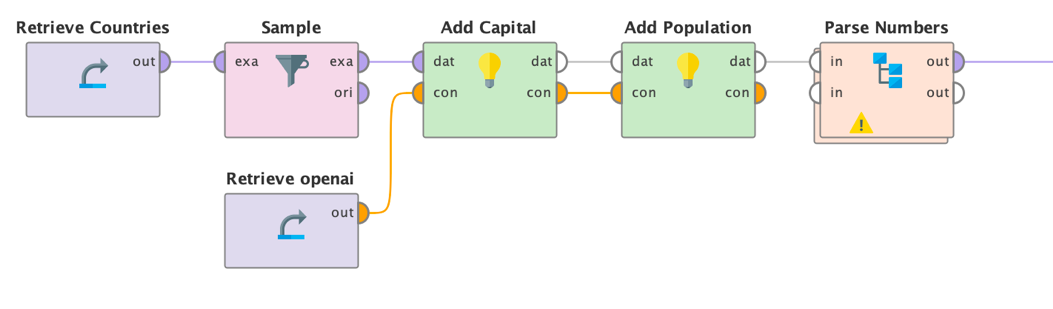
入力として国のリストをSend Promptオペレータに送ります。以下のようなプロンプトを使用できます
- オペレータ “首都を追加”: “[[国]] の首都は何ですか? 答えのみです。散文はありません。
- 人口の追加 “人口の追加”: “[[国]] の人口は何ですか? 正確な数字のみです。散文やテキストはありません。
また、回答のばらつきを少なくするために、温度0を使用しました。上記のようなプロンプトと低い温度の両方が、周囲の「チャット」なしで、より事実に近い回答を提供します。また、これを達成するために、システムのプロンプトを変更することや、微調整することもできます。最後に、RapidMinerでテキスト回答が数値列になるように数値を解析します。
お分かりのように、希望する答えを得るにはプロンプトを少し工夫する必要があります。しかし、その結果は素晴らしいもので、特に複雑なデータ強化やデータクレンジングタスクにかかる時間を大幅に短縮することができます。
生成AIの関連技術
RapidMinerで大規模言語モデルを使用し、微調整する方法についてよく理解したところで、大規模言語モデルや一般的なテキストデータと組み合わせた場合に特に役立ついくつかの関連技術について説明しましょう。
プロンプトの生成
多くのプロンプトでは、「あなたは親切なソフトウェアサポートのスペシャリストです」などのガイダンスや同様の構文があると便利です。その結果、特に上記で説明した動的プロンプト言語構文[[column_name]]を使用して複数回挿入する場合、プロンプトが比較的長くなる可能性があります。もう一つの側面は、モデルが改行に注意を払うことが多いということです。改行はプロンプトを構造化するのに役立ち、例えば、質問と回答を導き出すコンテキストの間に区切りを入れることができます。
このような理由から、上記のタスクオペレータは複数行のプロンプトを編集することができます。また、Generate Attributesオペレータを使用してプロンプトを生成し、それらを含む新規の列を生成することもできます。しかし、このオペレータは改行などではうまく動作しません。
そこでGenerate Promptsオペレータが役に立ちます。このオペレータを使用すると、改行やいくつかのプロンプト挿入構文を含むプロンプトテンプレートを指定するだけで、最終的なプロンプトを含む新規列を生成します。これらのプロンプトは後のタスクオペレータで使用することや、後でログ記録の理由を参照するために保存することができます。
Generate Promptsオペレータの使い方はとても簡単です。タスクオペレータのように、いくつかの入力データをオペレータに渡します。
このオペレータのパラメータもシンプルです。基本的には、新しい列の名前とプロンプトそのものを指定します。
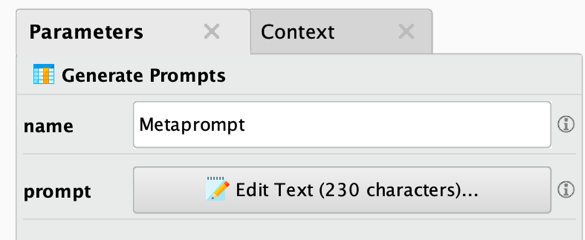
プロンプトボタンをクリックすると、プロンプトエディタが表示されます。
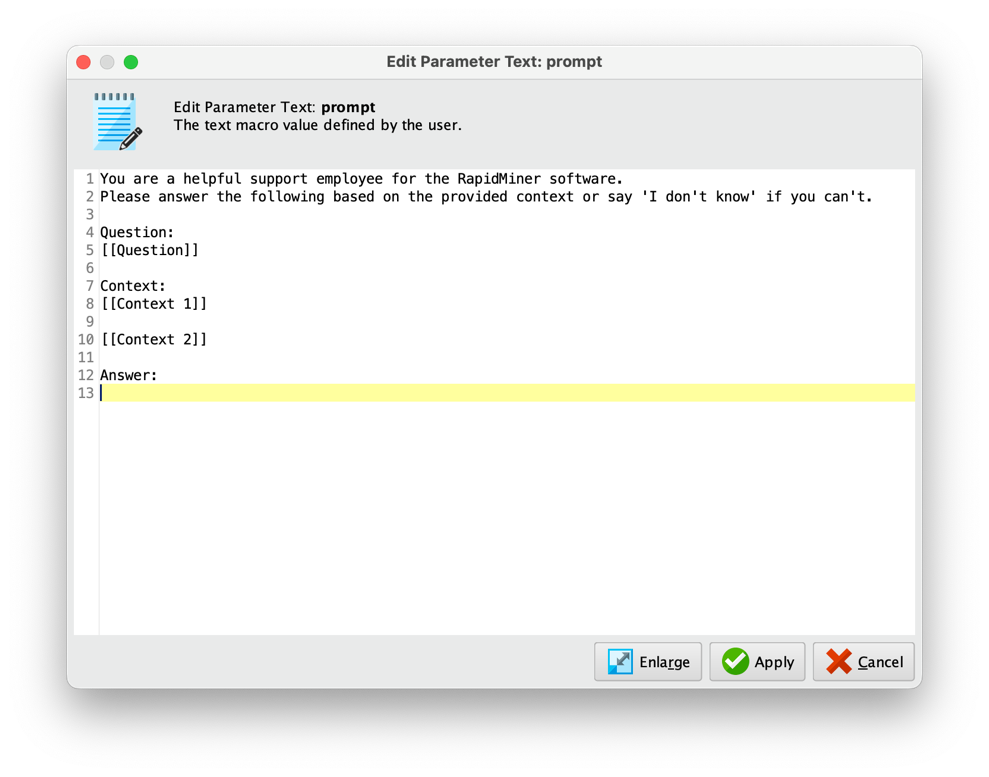
ご覧のように、複数行のプロンプトを簡単に生成および編集することができます。また、既知の動的プロンプト挿入形式[[column_name]]を使用して、1つまたは複数の入力列を参照することができます。
埋め込み
もう1つの有用なテクニック、つまりオペレータは、テキストの埋め込みです。埋め込みは、テキストを高次元空間の数値ベクトルに変換する技術です。これらのベクトルは、機械学習アルゴリズムや関連技術によって処理されます。例えば、これらの埋め込みベクトルを類似性検索に使用することや、テキスト分類のための従来の機械学習モデルの入力として使用することができます。
重要なことは、これらのベクトル表現は、それらが表す単語の意味や文脈を捉えるように設計されているということです。テキストの埋め込みベクトルは、高次元埋め込み空間における点を表します。そして、2つの点またはベクトルが互いに近ければ、たとえ異なる単語を使用して内容を説明していたとしても、意味的に類似していることを示します。
このように、特定の単語に依存しすぎることなく、意味的な類似性を捉えるというコンセプトが、テキスト埋め込みを強力なものにしているのです。次のセクションでは、ベクトルストアについて、これらの埋め込みがコンテンツの取得にどのように使用できるかを見ていきます。
しかし、埋め込みベクトルの使用方法を見る前に、まず、埋め込みベクトルの作成方法について説明しましょう。
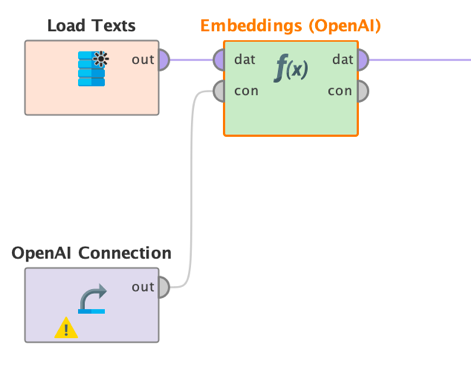
上の例では、Embedding (OpenAI)オペレータを示していますが、他のすべての埋め込みオペレータも同様の方法で動作します。ユーザーは使用する埋め込みモデル、入力列の名前、および埋め込み列の希望の名前を指定するだけです。オペレータは各入力ドキュメントの埋め込みベクトルを計算し、その値をカンマ区切りのリストとして新規列に格納します。すべてのパラメータは次のとおりです。
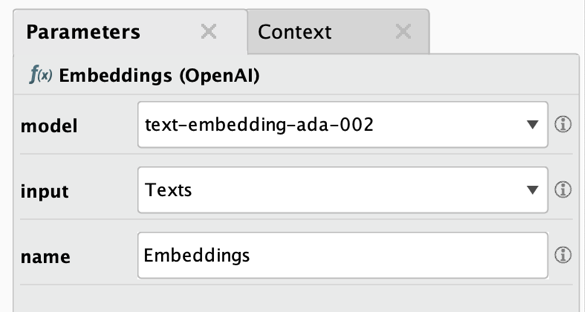
- モデル: 使用するOpenAIの埋め込みモデルの名前
- 入力: 埋め込みベクトルを作成するテキストを含む列の名前
- 名前: 埋め込みベクトルをカンマ区切り値として含む、新しく作成される列の名前
すべての埋め込みオペレータとアルゴリズムは、特定のサイズまたは次元のベクトルを提供することに注意してください。例えば、OpenAIのada-002埋め込みは1536次元です。他の埋め込みモデルでは、他の数値を提供します。768次元や384次元もよく使用されます。出力ベクトルの次元については、埋め込みオペレータやアルゴリズムのドキュメントを参照してください。
上述したように、これらの埋め込みを類似度計算オペレータの入力として、あるいはテキスト分類などの機械学習モデルの入力として使用することができます。必要なことは、埋め込み列に対してSplitオペレータを適用し、単一の列を適切なデータ列に変換することだけです。その後、通常どおり、他のオペレータをそれらのデータセットに適用することができます。
Vector Storesの使用
埋め込みがどのようなもので、テキスト間の意味的類似性を表現および計算するために使用できることがわかったところで、これらの埋め込みの最も簡単な使い方の1つである、意味的類似性に基づくコンテンツ取得について説明しましょう。
埋め込みに基づくテキスト文書を格納し取得する最良の方法は、いわゆるベクトルストアまたはベクトルデータベースです。市場には多くのベクトルストアがあります。現在、このエクステンションはそのうちの2つをサポートしています。
- Qdrant: https://qdrant.tech/
- Milvus: https://milvus.io/
ベクトルストアの考え方は、ドキュメント、または実際にはペイロードを、その埋め込みベクトルの位置に保存することです。1つまたは複数の最も類似したドキュメントやペイロードを取得したい場合、クエリに必要な埋め込みベクトルを送信し、最も類似した結果、つまり、クエリに提供した埋め込みベクトルに最も類似した埋め込みベクトルを持つドキュメントを取得することができます。
ワークフローは非常にシンプルになりました。まず、前述のような埋め込みオペレータを使用して埋め込みベクトルを作成します。次に、使用した埋め込みモデルと同じ次元数を使用して、ベクトルストアにコレクションを作成できます。
最後に、埋め込み空間の位置として計算された埋め込みを用いて、ドキュメント(ソースやその他のメタデータなど、保存したい追加ペイロードを含む)をベクトルストアのコレクションに挿入することができます。
後で、同じ埋め込みオペレータを使用してクエリの埋め込みを作成し、最も類似したドキュメントとそのペイロードをベクトルストアから再度取得することができます。
以下は、さまざまなオペレータの使用方法と組み合わせ方法を示す例です。
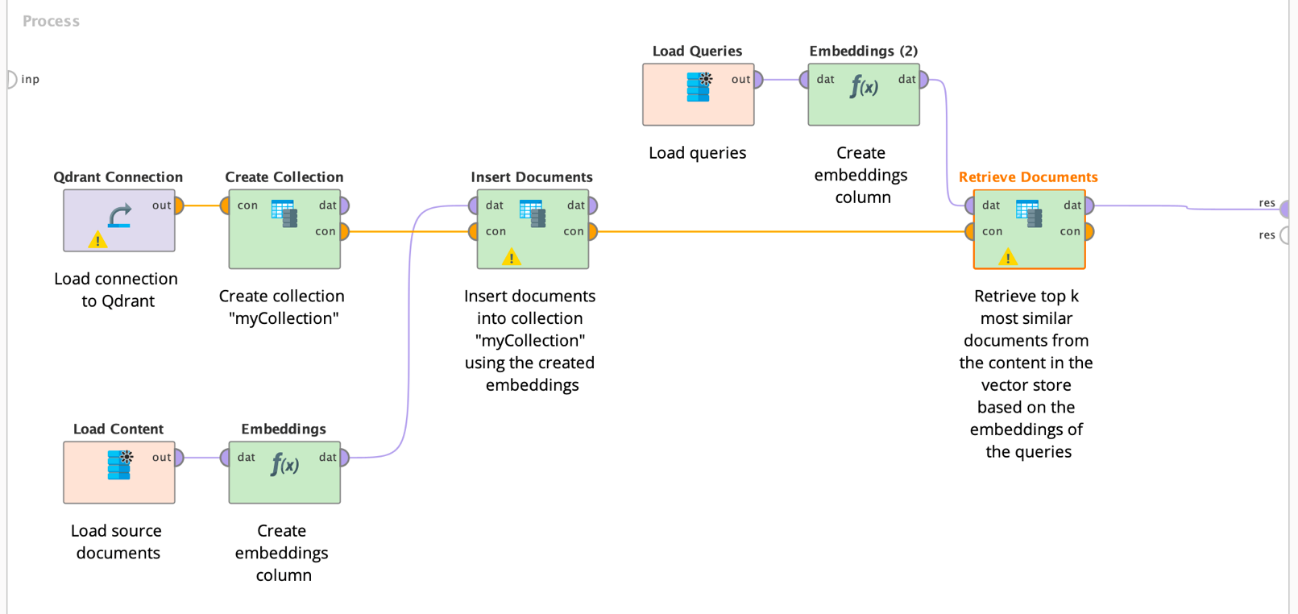
ベクトルストアにアクセスするには、ディクショナリ接続を作成する必要があります。ベクトルストアには、通常、URIとセキュリティトークンが必要ですが、セキュリティトークンはオプションである場合もあります(Qdrantの場合)。これらのキーの値は、ディクショナリ接続の形式で、このエクステンションのすべてのベクトルストアのオペレータに配信する必要があります。
RapidMiner Studioの「Connections」メニューから「Create Connection」を選択します。ダイアログで、タイプとして「Dictionary Connection」を選択し、任意の名前で保存します。作成後、「Add Entry」をクリックし、新規キーと値のペアを追加します。左側のキーに「uri」、右側の値にベクトルストアのURI値を指定します。必要に応じて、キーとして「token」をAPIキーまたはユーザー/パスワードのペアで指定する必要があります。接続を保存します。これで、この接続オブジェクトを対応するすべてのベクトルストアの入力として提供できるようになりました。
| 接続 | キー | 値の説明 |
|---|---|---|
| Milvus | uri | MilvusインスタンスのURI |
| Milvus | token | Milvusのセキュリティトークン。生成されたAPIキーか、この形式のユーザー/パスワードのペアです。 |
| Qdrant | uri | QdrantインスタンスのURI |
| Qdrant | token | Qdrantのセキュリティトークン。Qdrantインスタンスでトークンが不要な場合は、このキーは省略できます。 |
各ベクトルストアは6つのオペレータをサポートしています。
- コレクションの作成: このオペレータは入力としてベクトルストアへの接続を取得し、パラメータとしてコレクション名とベクトルサイズ(埋め込み次元)を取得します。コレクションはデータベースのテーブルに相当し、ドキュメントを挿入および取得できる場所です。詳細パラメータとして、使用する類似度メトリックを指定することもできます。
- コレクションの削除: このオペレータは入力としてベクトルストアへの接続を、パラメータとしてコレクション名を取得します。このコレクションとそのすべてのコンテンツが削除されるため、まだ必要なコレクションを削除しないように注意してください。
- コレクションの取得: このオペレータは入力としてベクトルストアへの接続を取得し、出力としてすべてのコレクション名を提供します。
- コレクション情報の取得: このオペレータは入力としてベクトルストアへの接続を、パラメータとしてコレクション名を取得します。そしてコレクション名やコレクション内のドキュメント数などの情報を提供します。ベクトルストアに基づき、ベクトルの次元や類似度メトリクスなどの追加情報も提供します。
- ドキュメントの挿入: このオペレータは入力としてベクトルストアへの接続と、カンマ区切りの埋め込みを含むデータセットを取得します。オペレータはすべてのデータ行をドキュメントとして、使用するベクトルデータベースのコレクションに挿入します。パラメータとしてコレクション名と各ドキュメントの埋め込みを含む列を指定する必要があります。入力データ中の埋め込みベクトルのサイズは、ドキュメントを追加したいコレクションのベクトルサイズと一致する必要があり、コレクションの作成時に指定されています。埋め込み列以外のすべての列は、コレクションに追加されるドキュメント(いわゆるペイロード)の一部になります。例えば、「Id」と「Text」という2つの追加列がある場合、それらの内容は、各埋め込みベクトルの下に格納されたコレクション内のドキュメントになります。これらのカラムも同様に取得することができます。
- ドキュメントの取得: このオペレータは入力としてベクトルストアへの接続と、カンマ区切りの埋め込みを含むデータセットを取得します。オペレータはベクトルデータベースのコレクションから最も類似したドキュメントを取得し、新規列としてそのペイロードと類似性スコアを入力データに追加します。コレクション名と、各ドキュメントの埋め込みを含む列を(カンマ区切りの値のリストとして)指定する必要があります。これらの埋め込みベクトルのサイズは、ドキュメントを追加したいコレクションのベクトルサイズと一致する必要があり、コレクションの作成時に指定されています。
これらのオペレータが一般的にどのように使用されるかを見てきましたが、次に、ベクトルストアと埋め込みを組み合わせた大規模言語モデルのもう1つのよくある使用例について説明します。これはRetrieval Augmented Generation、略してRAGと呼ばれます。
すべてをまとめる: Retrieval Augmented Generation (RAG)
現在、いわゆるRAG(Retrieval Augmented Generation:検索拡張生成)に取り組むためのすべての構成要素(大規模言語モデル、埋め込み、ベクトルストア)が揃いました。RAGは大規模言語モデルをコンテンツ検索に使用する際の2つの大きな問題を克服するために考案されました。
- 大規模言語モデルは、学習していないドキュメントについての答えを返すことができません。これは、学習データの締め切り日以降のイベントについてモデルに質問する場合に問題になる可能性があります。または、単に組織のみに知られていて、それゆえ公開された学習コーパスの一部ではないドキュメントです。このような状況では、モデルは「幻覚」とも呼ばれる答えを「でっち上げる」ことになります。
- 幻覚は、たとえモデルが関連データで学習されていたとしても発生する可能性があります。テキスト生成モデルなど、大規模言語モデルは、単純に次に出てきそうな単語を予測するだけであることに留意してください。そしてこの単語の次の単語を予測します。そして、その次の単語、といった具合です。この一連の単語が真実を表しているという保証はありません。それは単に、最も可能性の高い順序、それだけです。
上記の最初の問題を解決するために、新規データに基づいてモデルを微調整することができます。しかし、そのようなモデルはまた古くなるため、頻繁に微調整を再実行する必要があり、比較的高価で時間もかかります。また、微調整されたモデルであっても、上記2番目の問題で説明したように幻覚が発生する可能性があります。
上記の2つの問題を解決するために、次のアプローチがあります。それは、検索拡張生成と呼ばれ、基本的な考え方は、テキストチャンクをベクトルストアに保存し、クエリに最も似ているチャンクを取得し、それらを元のクエリのコンテキストとして提供することです。下の図を見ると、これがより明確になるはずです。
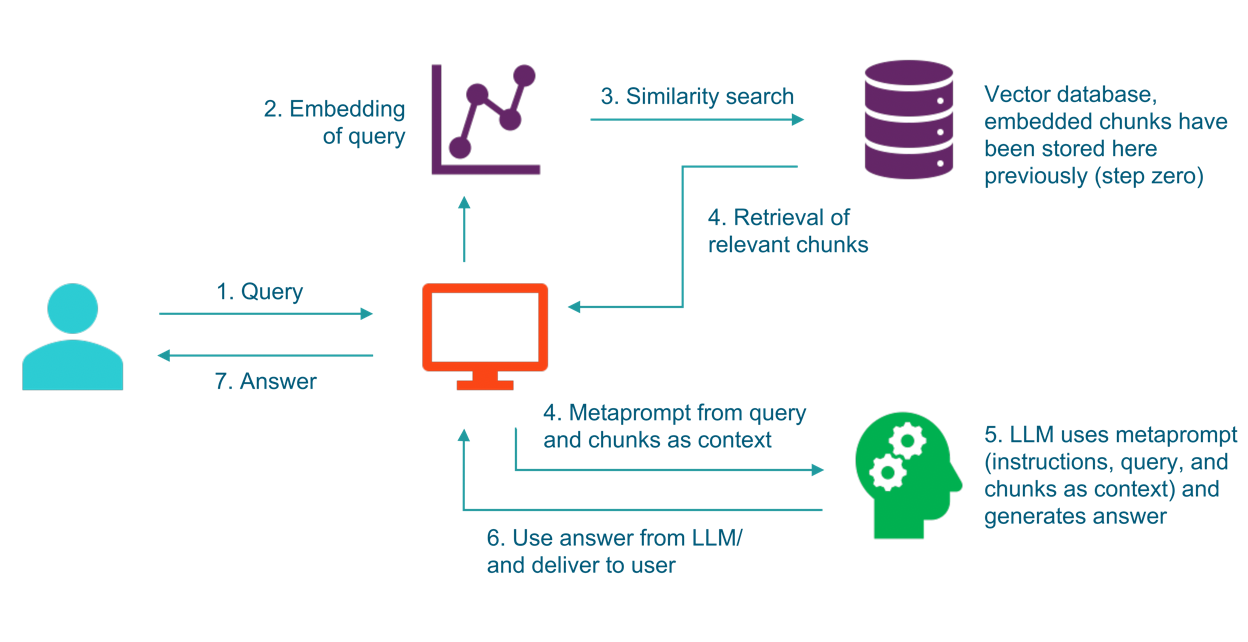
ご覧のように、クエリ(1)は埋め込みモデル(2)の入力として使用され、その埋め込みはベクトルストア(3)での類似検索に使用されます。このベクトルストアでは、関連するテキストドキュメントとその埋め込みが事前に格納されています。
ベクトルストア(4)から最も類似したチャンクが検索された後、それらのチャンクは「メタプロンプト」(4)の一部として、元のクエリにコンテキストとして追加されます。この強化されたプロンプトは、多くの場合、大規模言語モデルが提供されたコンテキストのみを使用して、幻覚をさらに低下させるための答えを生成する必要があることも示しており、その後、大規模言語モデル(5)に渡され、最終的な答え(6)が生成され、ユーザー(7)に返されます。
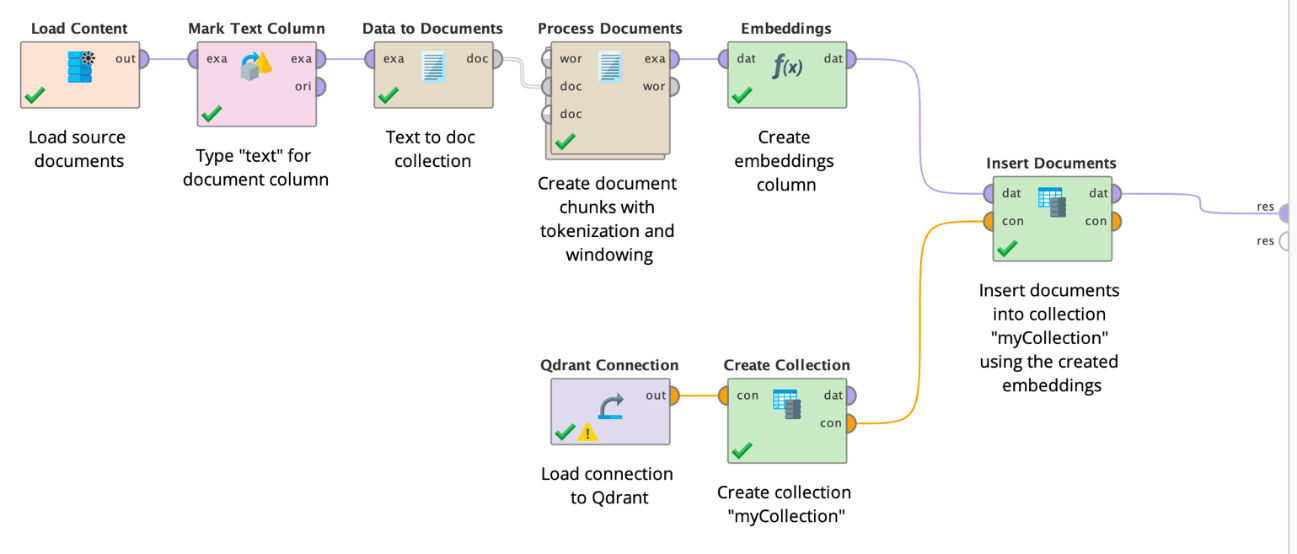
ご想像のとおり、上記のオペレータを使用してこれらすべてを行うことができます。まず、Text Processingエクステンションのオペレータを使用してテキストドキュメントを文ごとに分割し、ベクトルデータベースに格納できるテキストのチャンクを生成することができます。次に、それらのチャンクの埋め込みを生成し、同じベクトルサイズのコレクションに格納します。以下のワークフローはこれら2つの準備ステップを示しています。
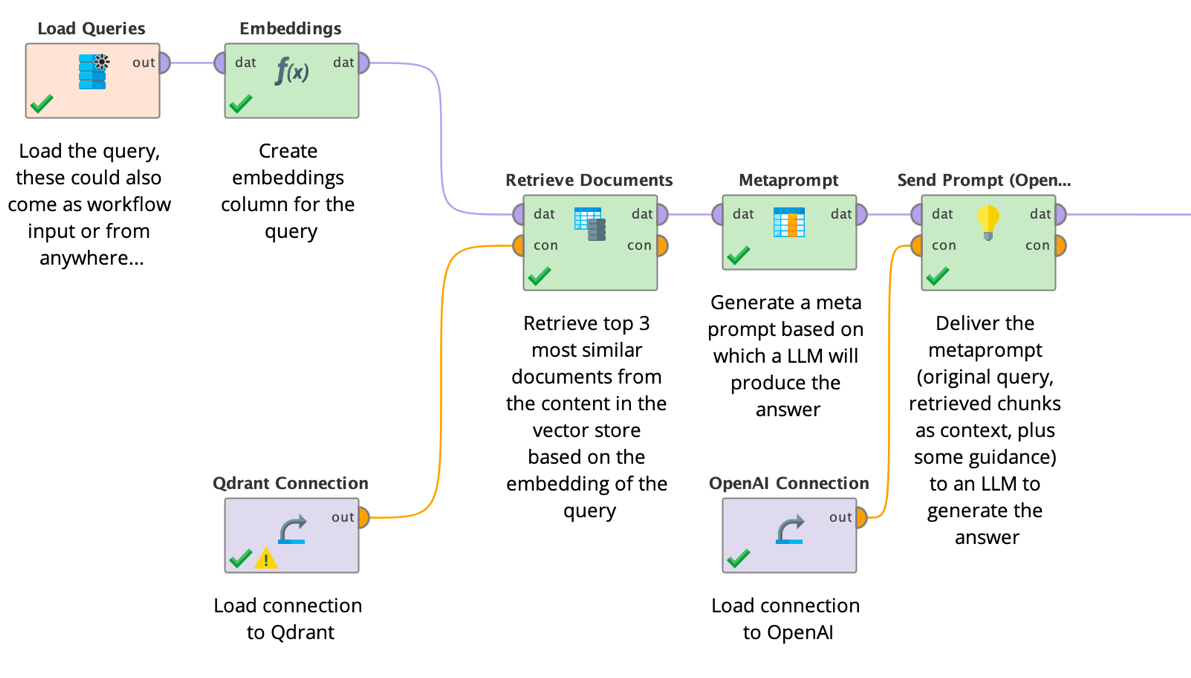
ベクトルデータベースにドキュメントを入力するこの準備作業が完了すると、実際のRAGワークフローに上記のすべてのステップを実装することができるようになります。クエリを取得し、その内容を埋め込み、作成された埋め込みベクトルをベクトルストアからの取得に使用して、元のクエリとコンテキストとして取得されたチャンクからなるメタプロンプトを生成し、メタプロンプトを大規模言語モデルに送信し、最後に結果を送り返します。以下のワークフローはこれらすべてのステップを示しています。
もちろん、Altair RapidMinerではいつものように、このようなワークフローをバッチ方式で実行したり、スケジュールしたり、他のシステムに統合できるウェブサービスにしたりすることができます。
メタプロンプトに関する最後のコメントです。多くの場合、クエリやチャンクに加え、何らかのガイダンスをコンテキストとして使用することは役立ちます。例えば、以下のようなプロンプトテンプレートを使用することで、結果を改善することができます。
You are a software support expert.
Answer the following question using the provided context.
If you can't find the answer, do not pretend you know it, but answer 'I don't know'.
Question:
[[query]]
Context:
[[result_1_text]]
[[result_2_text]]
[[result_3_text]]
Answer:
上記のような改行や空行を含むプロンプトテンプレートを使用することで、大規模言語モデルでクエリとコンテキストをより適切に区別することができます。また、答えがコンテキストにない場合の対処法や、どのようなペルソナを想定すべきかを指摘するのにも役立ちます。
要約
ご覧いただいたように、RapidMinerで生成AIモデルを使用するのは非常に簡単です。自然言語処理のためのHuggingfaceのすべてのモデルにアクセスすることができます。要約やテキスト間の生成などの新規タスクをすべて解決することができます。さらに、これらすべてのモデルをあなた自身の微調整の基礎として使用することができます。そして、RapidMinerではいつものように、コードを1行も記述することなく、これらすべてが可能です。
2つ目のオペレータグループは、OpenAIの非常にパワフルな会話モデルにアクセスでき、さらにそれらを微調整することもできます。そしてまた、コーディングのスキルは必要ありません。
埋め込みを計算したり、ベクトルストアにドキュメントを保存したり、ベクトルストアからドキュメントを取得したり、検索拡張生成(RAG)のための完全なソリューションを構築することも同様に簡単です。
生成AIとベクトルストアなどの関連技術で取り組める新規ユースケースやタスクのすべてに慣れるには、しばらく時間がかかるかもしれません。従来の機械学習とは異なり、生成AIでは、より創造的になり、単純なクラス(分類)や数値(回帰)の予測を超えた、より複雑なユースケースに取り組むことができます。
しかし、大きな力には大きな責任も伴います。大規模言語モデルはリソースを大量に消費し、ユースケースに取り組むために必ずしも必要とは限りません。また、大きいから良いとは限りません。もちろん、ChatGPTを使用してテキストを翻訳することもできます。しかし、Opusモデルを使用することもできます。Opusモデルはかなり小さく、翻訳タスクで同じようにうまく機能します。
そして、これらのモデルはしばしばインターネット上の公開ソースで学習されていることを常に念頭に置いてください。これにより、これらのモデルにバイアスが生じ、著作権侵害につながる可能性があります。私たちは、モデルだけでなく学習データも公開され、問題がないことを保証するオープンなアプローチを本当に信じています。必要な注意を払い、信頼できるモデルのみを使用することをお勧めします。
しかし、注意深く適切なモデルを使用すれば、以前よりも新しく複雑な問題を解決できるようになります。RapidMinerのGenerative Modelsエクステンションを使用して新規ユースケースに楽しく取り組んでください!
