インタラクティブ分析
この機能を使用するには、Altairユニットライセンスが必要です。
インタラクティブ分析のビデオガイドもご覧ください。
RapidMinerを使用してバイナリ分類の問題に直面した場合、決定木は有用なソリューションを提供します。インタラクティブ分析画面はRapidMiner Studioの拡張機能であり、データの正確なニーズに合わせてノードごとにカスタマイズしたセグメンテーションモデルを構築することができます。決定木は従属変数と独立変数の関係に基づいてデータセットを分割します。決定木は教師あり学習のための汎用的なデータマイニング手法です。また、あなた自身で修正でき、運用に使用できるプロセスを作成します。
決定木は大きく3つの問題を扱います。
- 二項分類
- 分類
- 回帰
インタラクティブ分析画面は、直感的で使いやすいインタフェースを使用して、なじみのない変数を探索し、ロジスティック回帰モデルなどの他のモデリング手法で使用できる予測性の高い独立変数を特定することにより、データの評価を支援します。
RapidMiner Studioを使用する場合、決定木ビューはデザイン画面、結果画面、ターボプレップ画面、オートモデル画面の隣に表示されます。
データが散乱していたり、一貫性のない状態で、まだモデル構築の準備ができていない場合は、ターボプレップの使用をお勧めします。
例: タイタニック号での生存者の予測
決定木をどのように使うのかをお伝えするために、RapidMiner Studioに含まれるTitanicデータセットを用い、タイタニック号での生存者の予測を行います。このデータセットではバイナリ変数として表されます。RapidMiner Studioの上にあるボタンより決定木を選択し、始めましょう。
データの選択
インタラクティブ分析画面を開いたら、最初のステップとして、SamplesリポジトリからTitanicデータセットを選択します。TitanicデータセットはSamples > dataの下にあります。データセットを選択し、画面下部のNextをクリックします。
モデルの選択
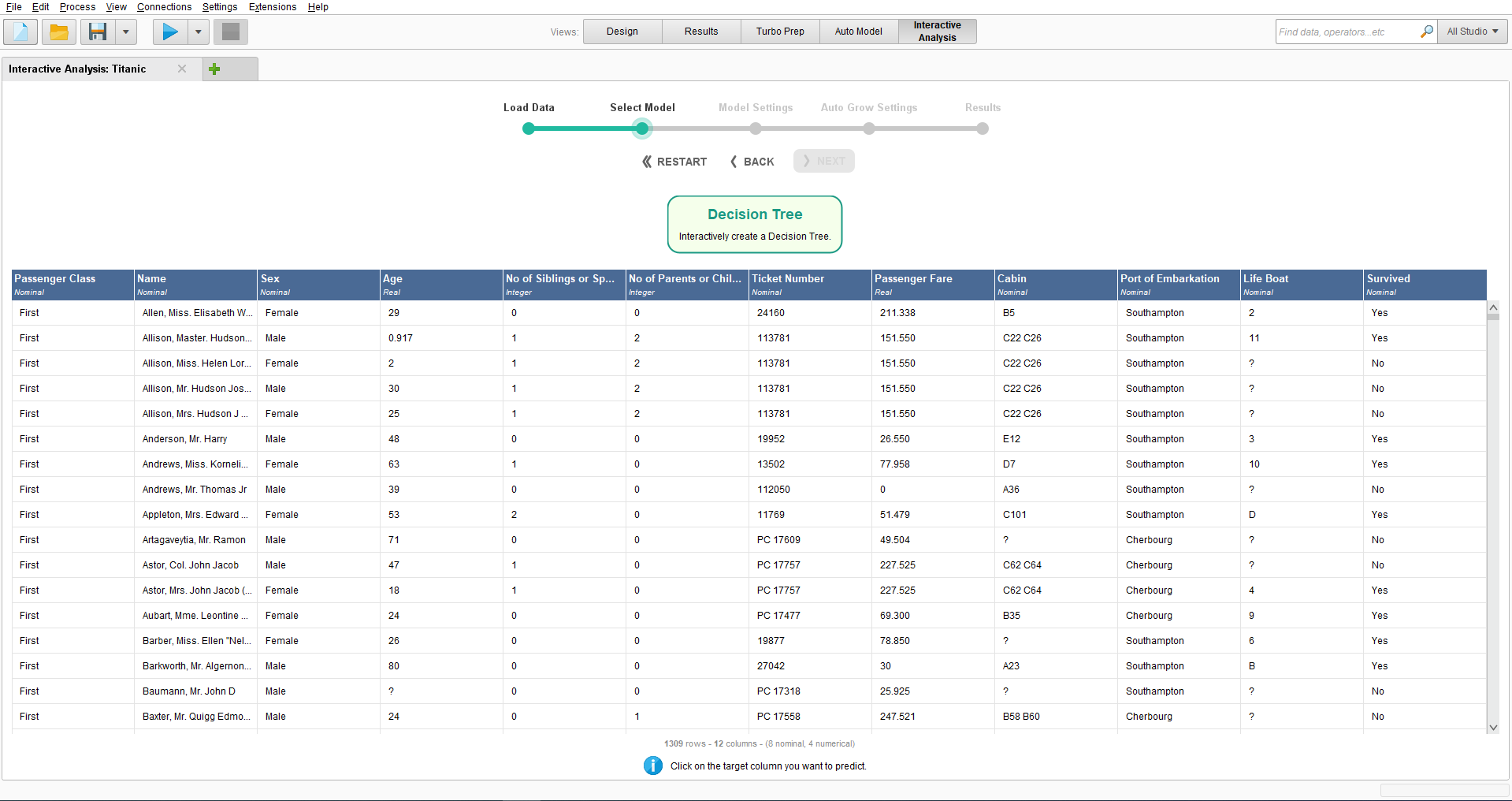
Titanicデータセットを選択したら、タイタニック号の生存者を予測したいため、「Survived」列を選択してからNextをクリックします。
RapidMiner Studio 10.2では、連続ターゲット変数は現在サポートされていません。この機能は将来のリリースで追加される予定です。
モデルの設定
“Survived”は”Yes”もしくは”No”の2つの値しかもっていないので、今回の問題は分類問題となります。一般に、分類問題では、インタラクティブ決定木は各クラスのデータ点の数を分割レポートで表示します。特定の分割検索方法または基準を使用したい場合は、分割検索方法リストと測定ドロップダウンボックスを使用して、トレーニングパラメータパネルからこれを選択することができます。そして、Generate Split Reportをクリックして、分割レポートを更新します。
分割レポート
この画面のレポートは、データセットの各変数(ターゲット “Survived “変数を除く)について、単変量情報とターゲットに関する情報を含むレポートを生成します。Quality列にすべての情報を要約したデータ品質レポートが変数ごとに生成され、これに基づいて、Status列にその変数をモデルに含めるかどうかが、信号システム(赤/黄/ 緑)を用いて推奨されます。ステータスが緑の変数が、従属変数として自動的に選択されます。変数がモデリングに選択されたりされなかったりする理由はいくつか考えられます。例えば、Ticket Number列のステータスは、「ID-ness」が 70% を超えていることを示すため赤色になります。つまり、一意の値の数がデータセット内の総行数の 70% を超えていることを示すので、この変数はあまり効果的な予測変数にはなりません。
データ列のすべてが予測に役立つわけではありません。いくつかのデータ列を取り除くことで、モデルのスピードを上げ、かつ(または)モデルのパフォーマンスを改善できます。しかし、その判断はどのように行うのでしょうか?重要なポイントはパターンを見つけ出すことです。データにある程度変化があり、ある程度パターンを識別できなければ、そのデータは役に立たないでしょう。
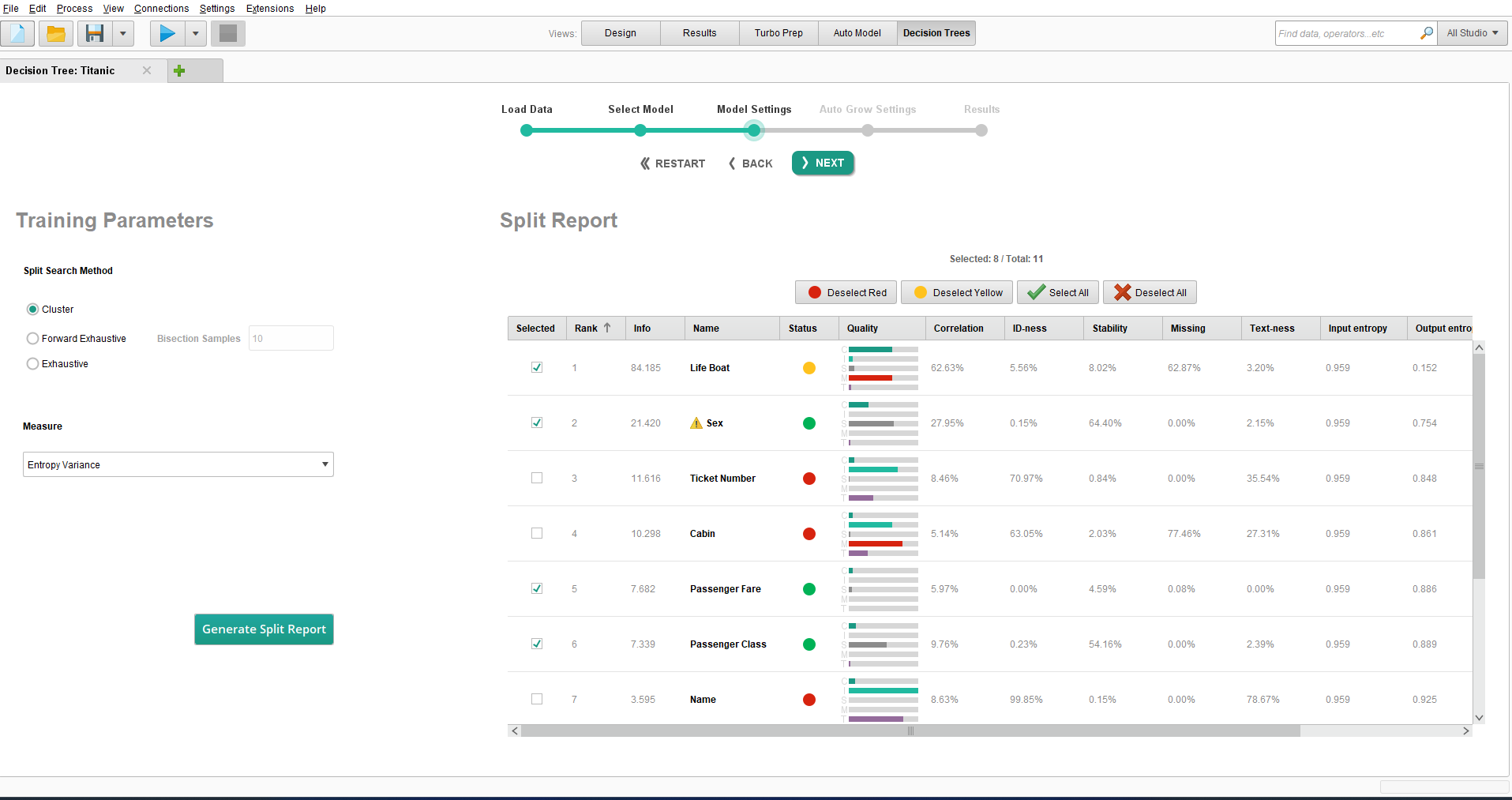
注目すべき点を簡単にまとめると以下のようになり、値は各データ列のクオリティバーの横に並んで表示されます。
- 目的変数に酷似している、もしくは全く似ていない列(Correlation)
- ほぼ全ての値が異なる列(ID-ness)
- ほぼ全ての値が同じ列(Stability)
- 欠損値がある列(Missing)
分割レポートは色分けされたステータスバブル(赤/黄/緑)を用いて状態を要約します。一般的なルールとして、少なくとも赤のステータスバブルを持つ列を外すことをお勧めしますが、もちろん、ステータスに関係なく好きな列を外すことが可能です。機械学習モデルへの入力は選択した列のみ含まれます。
Titanicデータセットの場合、”Name”と”Ticket Number”はIDに相当します。”Cabin”の値はほとんどの乗客に対して欠損しています。したがって、赤のステータスバブルを持つこれら3列は、モデル構築の際に除外すべきです。これらのうちパターンの発見に役立つものはありません。
“Life Boat”は”Survived”と非常に高い相関があるため、黄色のステータスバブルを持っています。”Lifeboat”は”Survived”と事実上の同義語なので、”Life boat”列を削除し、モデルに生存の根本的な理由を発見させるのが良いでしょう。
少し言い換えると、モデルが計画を立てるのに役立つかどうかの視点で作成を進めることです。乗客は事前に救命ボートに乗れるかを知ることはできないので、救命ボートを計画の一部にはできません。しかし、チケットにいくら払うのか、また家族を一緒に連れていくかどうかは決めることができます。
今回の例では、黄色のステータスバブルが付いた”Life Boat”も外し、Nextを押します。
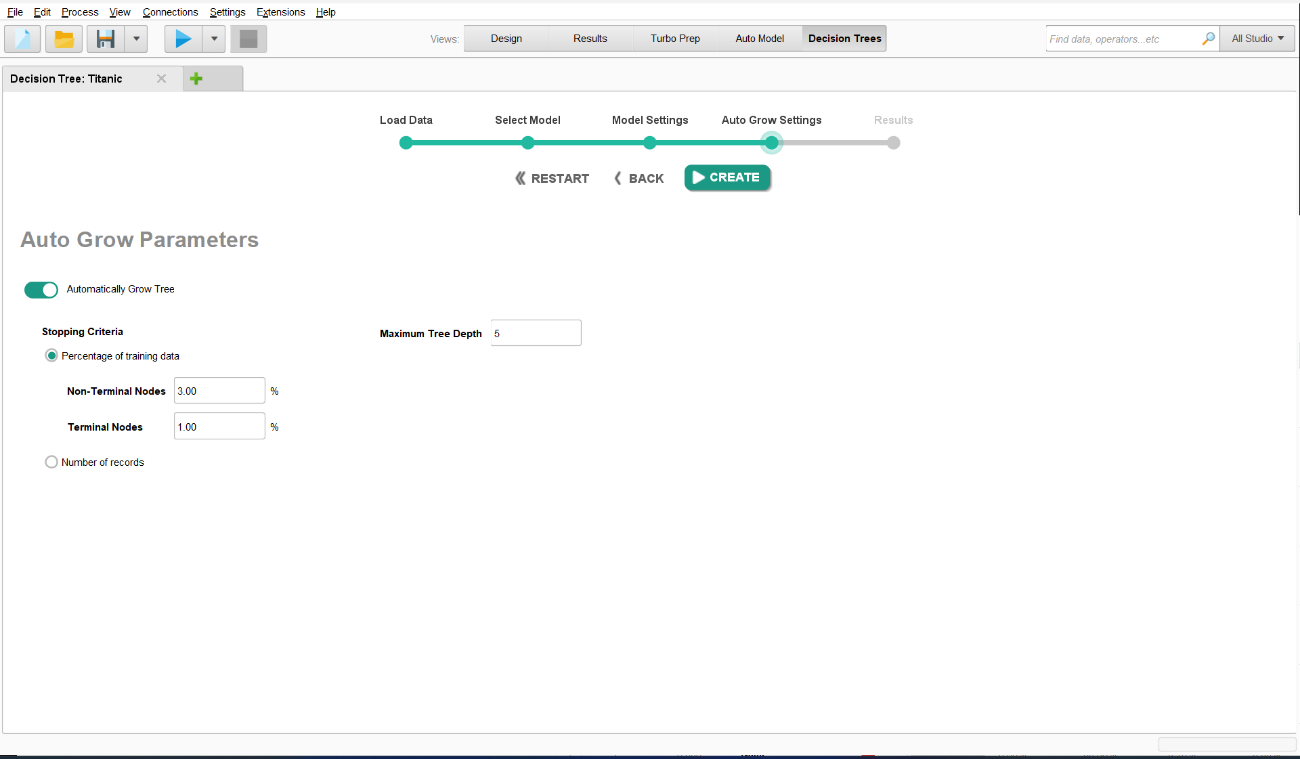
自動成長の設定
モデルの変数を選択した後、決定木の成長設定を行います。決定木はデータセット全体(通常はトレーニングデータセット)を表すベースノードから始まります。
データセットはモデルを学習するのためのトレーニングデータセットと、未知のデータに対するモデルの精度をチェックするためのテストデータセットにあらかじめ分割しておくとよいでしょう。トレーニングデータセットとテストデータセットの両方で、モデルが同じレベルの予測可能性を持つことが理想的です。もしトレーニングデータセットでの予測値がテストデータセットよりも正確であれば、モデルが過剰適合しているため、トレーニングデータセットの割合を減らすか、再サンプリングしたほうがよいでしょう。
トレーニングデータセットのベースノードは、変数によってさらにノードに分割されます。例えば、バイナリ変数はベースノードを2つのノードに分割し、これらのノードはさらに別の変数によって分割されます。バイナリまたは離散の場合は変数値によってノードが分割され、連続変数は1つまたは複数の不等式によって分割されます。
これらのインタラクティブな決定木では、ベースノードから自分でツリーを育てるか、ツリーを育ててもらうかを選択できます。後者の場合でも、個々のツリーを育てることができます。
この例では、自動的に成長するツリーから始めるので、Auto Grow Treeが選択されていることを確認してください。設定では、ツリーを自動的に成長させる際の制限を指定できます。Stopping Criteriaで各ノードの最小データ量を指定し、Maximum Tree Depthでツリーがベースノードから逸脱できるレベルを指定できます。この例では、すべてデフォルト値のままにして、Createをクリックします。
結果
選択したデータセットとモデルによっては、結果を得るまでに時間がかかります。上部のプログレスバーが計算の進捗を追跡しています。
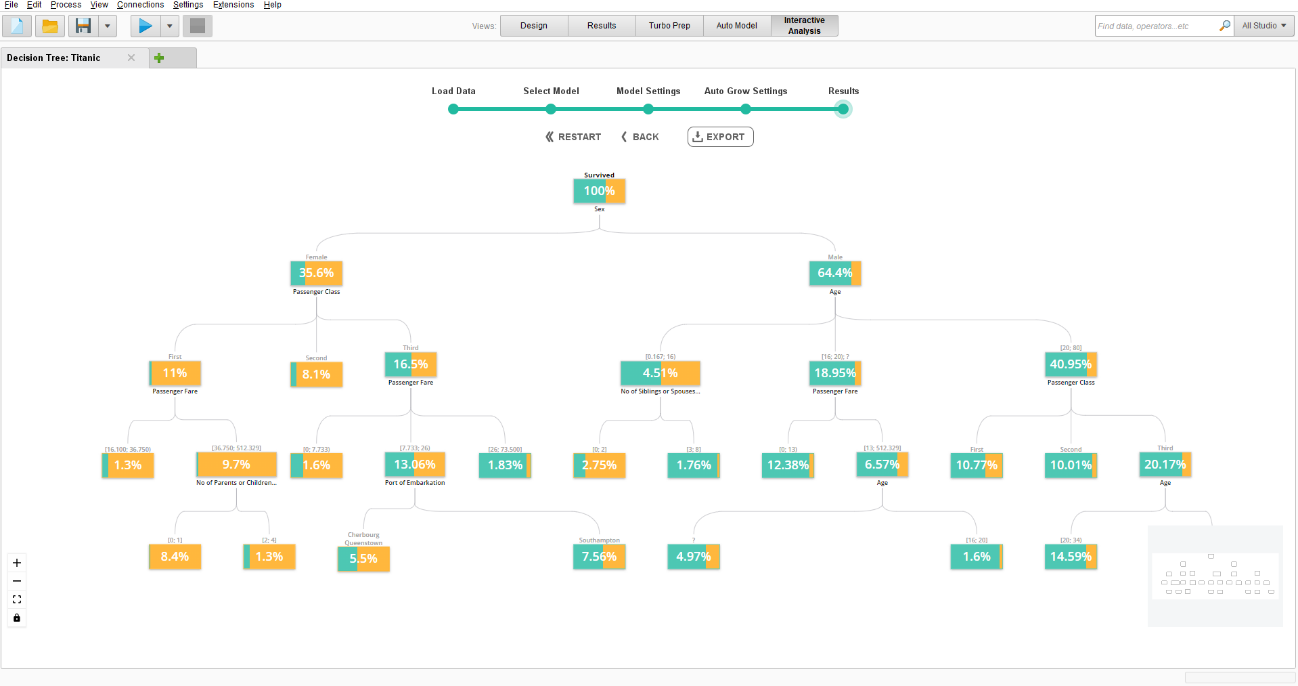
結果が準備できると、決定木は複数のノードのビューを含むキャンバスに表示されます。これらのノードはすべて、ノードのパーセンテージで示されるデータセットの一部を表します。ベースノードはデータセット全体を表すため、比率は常に100%です。各ノードには、ターゲット変数の比率を表すオレンジ/紫色の色分けされた分割もあります。ノードにカーソルを置くと、正確な数値を確認することができます。ツリーを自動的に成長させることを選択しなかった場合は、ルートノード(まだ分割されていないノード)をクリックして、左側のFind splitボタンを選択するとノードが1レベル分割され、中央のAuto growボタンを選択するとノードが完全に分割されます。ノードがすでに分割されている場合は、そのノードをクリックしてRemove child nodesボタンを選択すると、このノードを再びルートノードにすることができます。ノードは1つの独立変数の値によって分割されます。変数が離散型の場合は選択値によって、変数が連続型の場合は不等式によって分割されます。ノードを分割する独立変数は、分割ノードを選択して変数名の両側の矢印キーをクリックすることで変更できます。また、View split reportボタンを選択すると、変数の分割レポートを表示することもできます。
この例では、決定木はすでに完全に成長しており、ここからデータについての洞察を得ることができます。最初のレベルでは、データを性別で分割し、すでにターゲット変数の割合が女性と男性の間でかなり分割されていることがわかります。男性は19%生存しているのに対し、女性は73%生存しています。女性ノードはさらに乗客クラス別に分割され、ファーストクラスでは96%が生存し、次にセカンドクラスでは89%、最後にサードクラスでは49%が生存していることがわかります。男性ノードはさらに年齢別に分割され、0~18歳の生存率は51%、18~20歳は12.5%、20~80歳は19%です。このことから、ファーストクラスの女性は生存する可能性が非常に高いのに対し、成人男性はかなり低いことがわかります。あるデータにこのモデルを適用すると、各データポイントはツリーを通り、終端ノードの1つに達するまで、ツリーで指定された各変数の値を通ることになります。終端のノードから、そのノードのターゲット変数の割合である確率が返されます。返された確率は、<0.5と≥0.5の確率を独自のバイナリ変数に分割することで予測を行うことができます。このバイナリ変数は、モデルの予測として機能します。例えば、Titanicデータセットの決定木モデルは、生存する確率が0.5以上、生存しない確率が0.5未満を予測する変数を作成できます。
このビューから決定木をエクスポートして、RapidMinerワークフローに適用することができます。これを行うには、ExportボタンをクリックしてExport Modelダイアログボックスを開き、リポジトリフォルダを選択し、Nameテキストボックスにモデルの名前を入力し、Nextをクリックします。モデルのエクスポートが完了したら、CloseをクリックしてExport Modelダイアログボックスを閉じます。これで決定木モデルはRapidMinerワークフローで使用できるようになります。
