RapidMiner Studioのビルトインサンプルの使用
チュートリアルが終了したら、RapidMiner Studioのビルトインサンプルリポジトリ(解説ヘルプテキスト付き)を使用して、より多くの練習問題を行うことができます。サンプルデータとプロセスは、リポジトリパネルにあります。
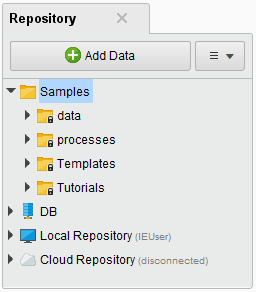
- data フォルダには、サンプルで使用される12種類のデータセットが含まれています。ここには、さまざまな種類のデータが含まれています。
- processes フォルダには、前処理、可視化、クラスタリング、およびその他多くのトピックを紹介する130以上のサンプルプロセスが含まれています。
サンプルを使用するには,processes フォルダを展開してください。
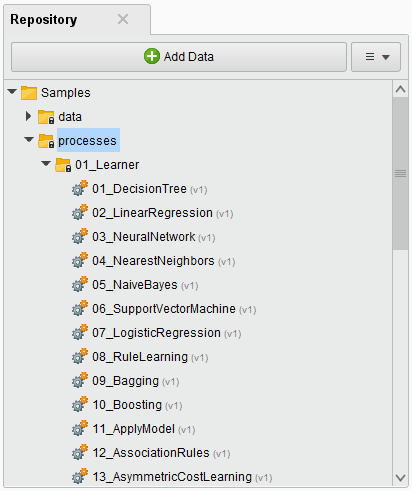
これらのプロセスを利用するには、2つの方法があります。
- ダブルクリックして、個々のオペレータをヘルプテキスト付きで表示します。この方法は学習に最適です。
- ドラッグアンドドロップを使用して、プロセスをすぐに実行できるようにします。
ダブルクリックで詳細を表示
サンプルプロセスをダブルクリックして表示することで、多くのことを学ぶことができます。
- プロセスを選択します。この例では、01_DecisionTree を使用します。
- プロセス名をダブルクリックします。RapidMinerがプロセスを開き、キャンバスに表示します。
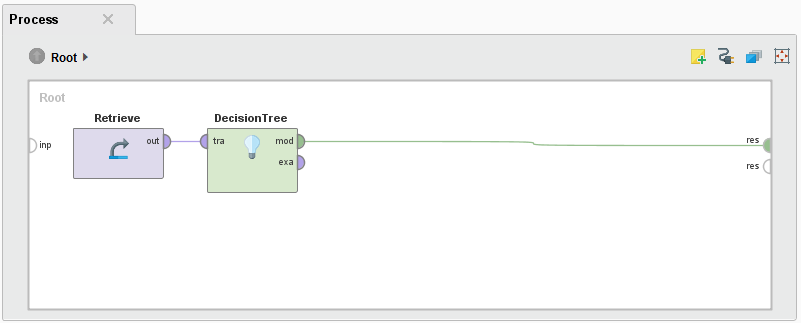
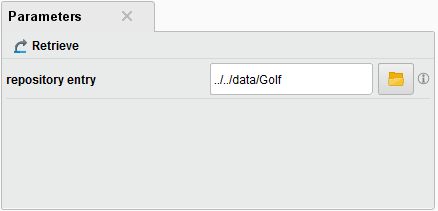
- オペレータに設定されたパラメータを表示するには、そのオペレータをクリックします。例えば、Retrieve オペレータをクリックすると、パラメータパネルに使用中のデータセット(Golf)が表示されます。
 をクリックしてプロセスを実行します。
をクリックしてプロセスを実行します。
ドラッグアンドドロップで効率化
リポジトリからプロセスをキャンバスにドラッグすると、上記とは違った見え方になります。RapidMinerは自動的に Execute オペレータを作成し ![]() をクリックすると、ドラッグしたプロセスを実行します。
をクリックすると、ドラッグしたプロセスを実行します。
ここでも、例として、01_DecisionTreeを使用します。
- 01_DecisionTreeをキャンバスにドラッグします。
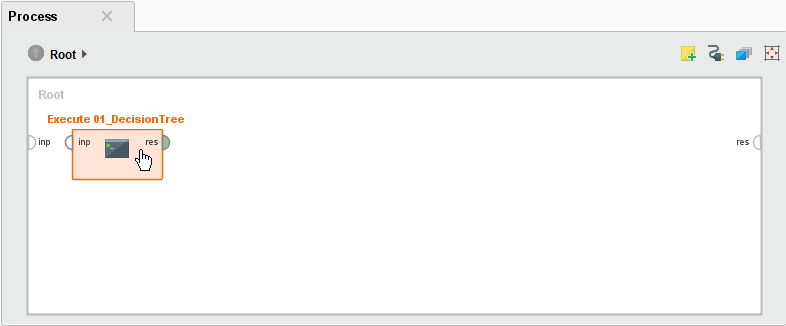
- 表示されているのは Execute オペレータであることに注目してください。このプロセスを構成するオペレータは表示されません。表示するには、リポジトリパネルでプロセスをダブルクリックする必要があります。
- Execute オペレータの結果(res) ポートをプロセスの結果ポートに接続し、
 をクリックしてプロセスを実行します。
をクリックしてプロセスを実行します。
経験を積み、多数のオペレータを使用する複雑なプロセスを設計するようになると、複数の構造があるプロセスを構築したくなるでしょう。複数のオペレータのプロセスを保存しておけば、必要に応じて再利用することができます。例えば、多くの分析を行う場合、データ更新のプロセス、データ前処理のプロセス、モデル作成のプロセス、モデル性能チェックのプロセスなどを作成することができます。各プロセスをリポジトリに保存し、必要に応じてキャンバスにドラッグします。そうすれば、メインプロセスには、相互に接続されたExecuteオペレータだけが追加され、きれいに整った状態となります。
