オートモデル
オートモデルの紹介ビデオ(ショート版 | ロング版)もご覧ください。
Altair AI Studioを使い始めたばかりの方でも、ベテランの方でも、オートモデルを使用することで手間を大きく削減できます。オートモデルはAltair AI Studioのエクステンションであり、モデルの構築や検証のプロセスを加速させます。そして何よりも、オートモデルで作成したモデルは後に細かく調整でき、運用に適用できるプロセスを作成できます。そのため、オートモデルで作成したモデルはブラックボックスではありません。
オートモデルは大きく3つの問題を扱います。
- Prediction(予測)
- Clustering(クラスタリング)
- Outliers(異常検知)
予測のカテゴリでは、分類と回帰の両方の問題を解くことができます。オートモデルはデータを評価し、問題解決に向け関連するモデルを提供します。また計算が終われば、モデルの結果の比較に役立ちます。
オートモデルは結果を得るだけでなく、内部ロジックを理解するのが難しいディープラーニングなどのモデルでも、結果を理解するのに役立ちます。Altair AI Studio内で、オートモデルはデザイン画面、結果画面、ターボプレップの隣に表示されます。
データが散乱していたり、一貫性のない状態で、まだモデル構築の準備ができていない場合は、ターボプレップの使用をお勧めします。
例: タイタニック号での生存者の予測
オートモデルをどのように使うのかをお伝えするために、Altair AI Studioに内蔵されているデータセットの1つである、Titanicデータセットを用い、タイタニック号での生存者の予測を行います。Altair AI Studioの上にあるボタンよりAuto Modelを選択し、始めましょう。
データの選択
オートモデルを起動した後、最初のステップはリポジトリの1つからデータセットを1つ選択することです。もしデータがリポジトリにない場合は、画面下部にある”import new data”をクリックします。
今回の例では、TitanicデータセットはSamples > dataの下にあります。データセットを選択し、画面下部のNextをクリックします。
タスクの選択
データセットを選択し終えたら、どの種類の問題を解決したいのかを決める必要があります。オートモデルは3つの異なるタスクを定義しています。
- Predict(予測)
- Clusters(クラスタリング)
- Outliers(異常検知)
今回の例では、タイタニック号の生存者を予測したいので、Predictを選択し、”Survived”列をクリックしてからNextをクリックします。
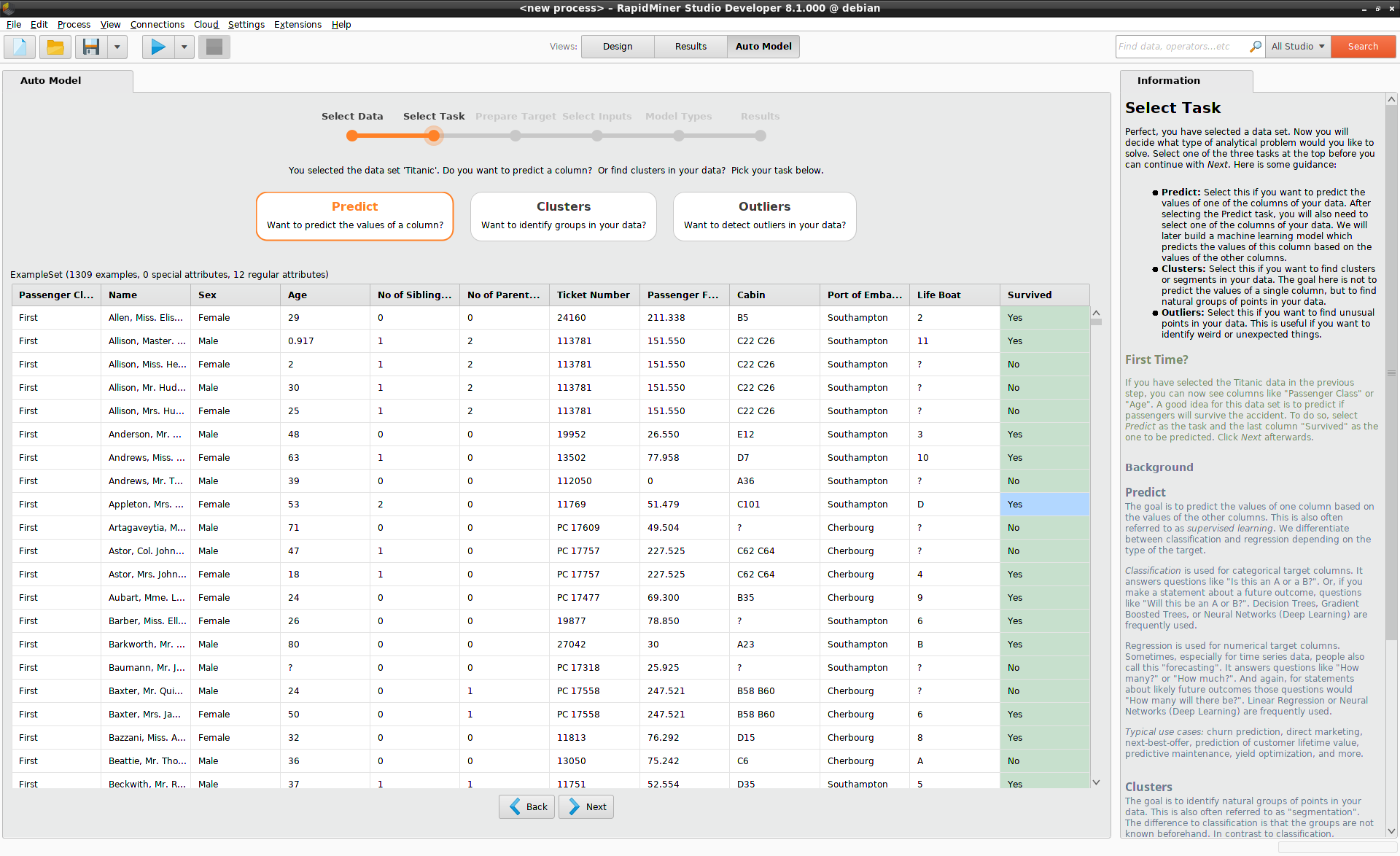
ターゲットの準備
“Survived”は”Yes”もしくは”No”の2つの値しかもっていないので、今回の問題は分類問題となります。一般に、分類問題について、オートモデルは各クラスのデータ点の数を棒グラフで表示します。10クラス以上ある場合は、データ点の多い10クラスが表示されます。
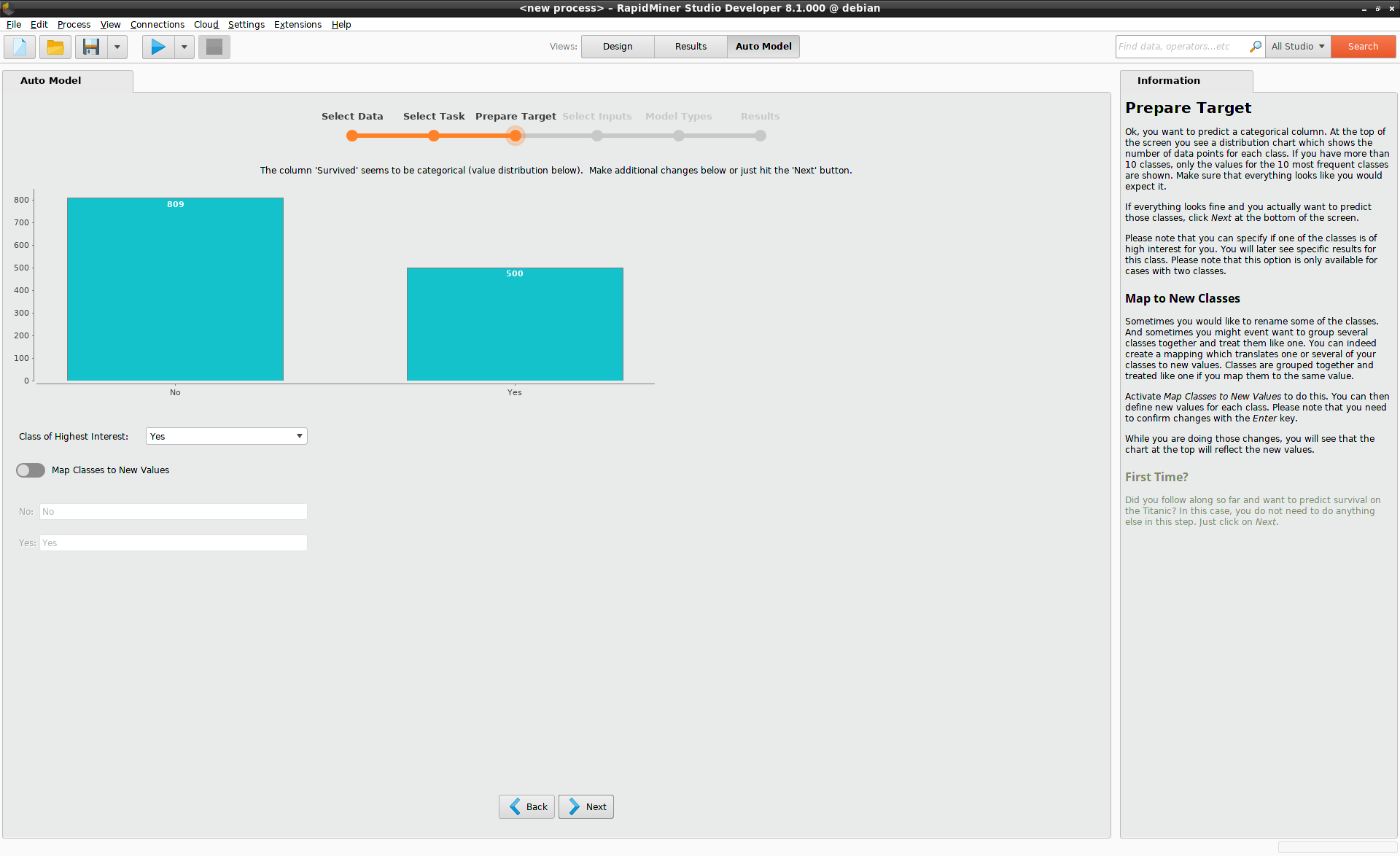
関心があるクラス
「適合率」と「再現率」のようなパフォーマンスはどのクラスが”positive(陽性)”かに依存するため、Class of Highest Interestは後の結果を表示するときに重要になります。今回のタイタニック号の例では、Class of Highest Interestは”Yes”です。
クラスを新しい値へマッピング
このステップでは、ターゲットの値を”Yes”と”No”から他の値へ変更するオプションを含んでいます。3つ以上のクラスがあるときは、クラスの結合にも使用できるため、このオプションはより役立ちます。新しい値を入力する際、入力後はEnterキーを押してください。今回の例では、このオプションは無視します。Nextをクリックして次に進みます。
入力の選択
データ列のすべてが予測に役立つわけではありません。いくつかのデータ列を取り除くことで、モデルのスピードを上げ、かつ(または)モデルのパフォーマンスを改善できる場合があります。しかし、その判断はどのように行うのでしょうか?重要なポイントはパターンを見つけ出すことです。データにある程度変化があり、ある程度パターンを識別できなければ、そのデータは役に立たないでしょう。
注目すべき点を簡単にまとめると以下のようになり、値は各データ列のクオリティバーの横に並んで表示されます。
- 目的変数に酷似している、もしくは全く似ていない列(Correlation)
- ほぼ全ての値が異なる列(ID-ness)
- ほぼ全ての値が同じ列(Stability)
- 欠損値がある列(Missing)
オートモデルは色分けされたステータスバブル(赤/黄/緑)を用いて状態を要約します。一般的なルールとして、少なくとも赤のステータスバブルを持つ列を外すことをお勧めしますが、もちろん、ステータスに関係なく好きな列を外すことが可能です。機械学習モデルへの入力は選択した列のみ含まれます。
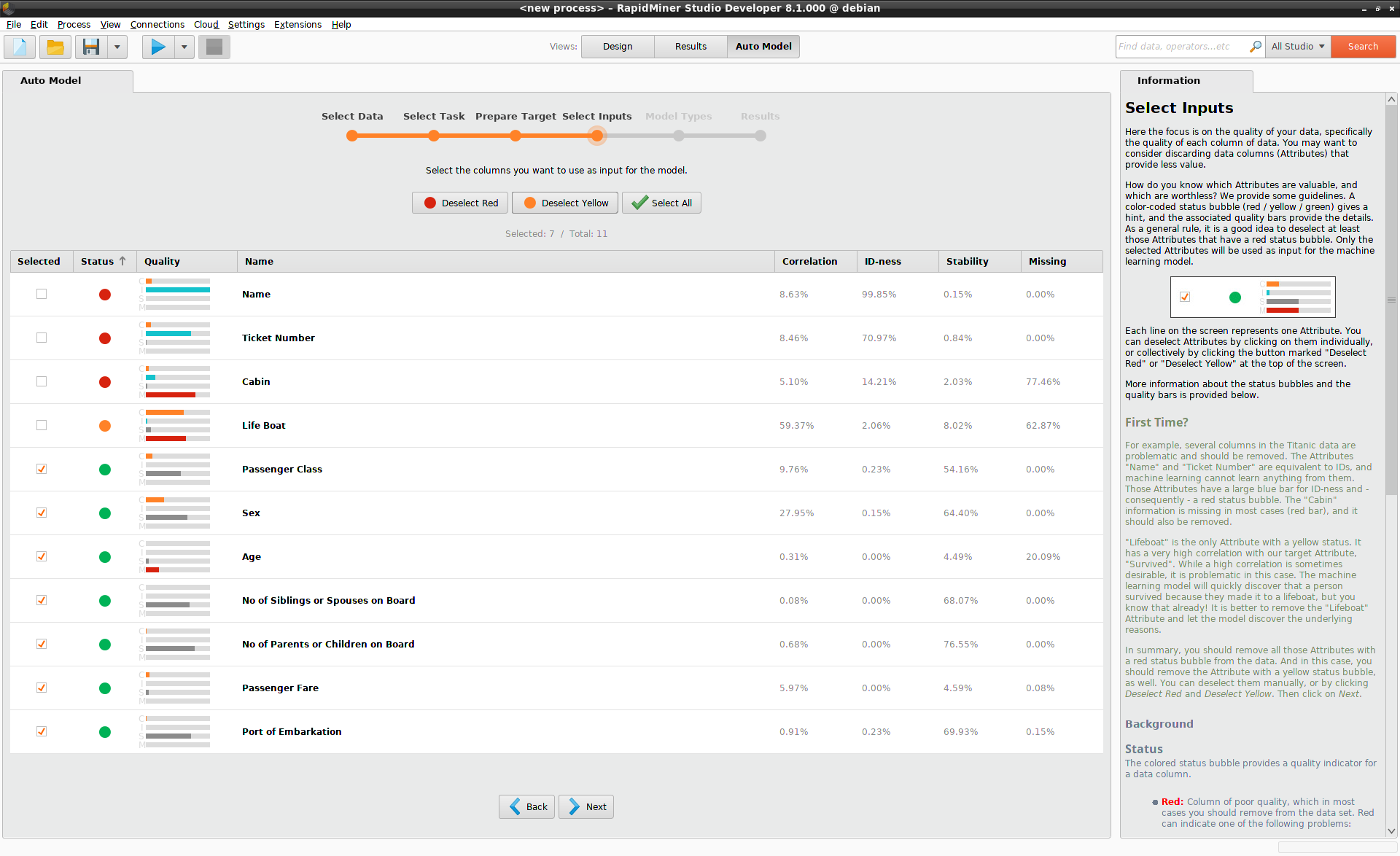
Titanicデータの場合、”Name”と”Ticket Number”はIDに相当します。”Cabin”の値はほとんどの乗客に対して欠損しています。したがって、赤のステータスバブルを持つこれら3列は、モデル構築の際に除外すべきです。これらのうちパターンの発見に役立つものはありません。
“Life Boat”は”Survived”と非常に高い相関があるため、黄色のステータスバブルを持っています。”Lifeboat”は”Survived”と事実上の同義語なので、”Life boat”列を削除し、モデルに生存の根本的な理由を発見させるのが良いでしょう。
少し言い換えると、モデルが計画を立てるのに役立つかどうかの視点で作成を進めることです。乗客は事前に救命ボートに乗れるかを知ることはできないので、救命ボートを計画の一部にはできません。しかし、チケットにいくら払うのか、また家族を一緒に連れていくかどうかは決めることができます。
今回の例では、黄色のステータスバブルが付いた”Life Boat”も外し、Nextを押します。
モデルのタイプ
オートモデルは問題に関係のあるモデルを提供してくれます。時間的な制約がない場合は、これらすべてでモデルを構築し、構築が終わればパフォーマンスを比較することが最も良い選択でしょう。通常は、構築したモデルの正解率を優先するのか、もしくは構築にかかる時間を優先するのかは自身で決める必要があります。オートモデルは合理的な妥協点に到達するのに役立つでしょう。
タイタニック号の例では、オートモデルは以下のモデルを提供します。
- Naive Bayes
- Generalized Linear Model
- Logistic Regression
- Deep Learning
- Decision Tree
- Random Forest
- Gradient Boosted Trees (XGBoost)
Runをクリックしてモデルを構築し、結果を生成します。

結果
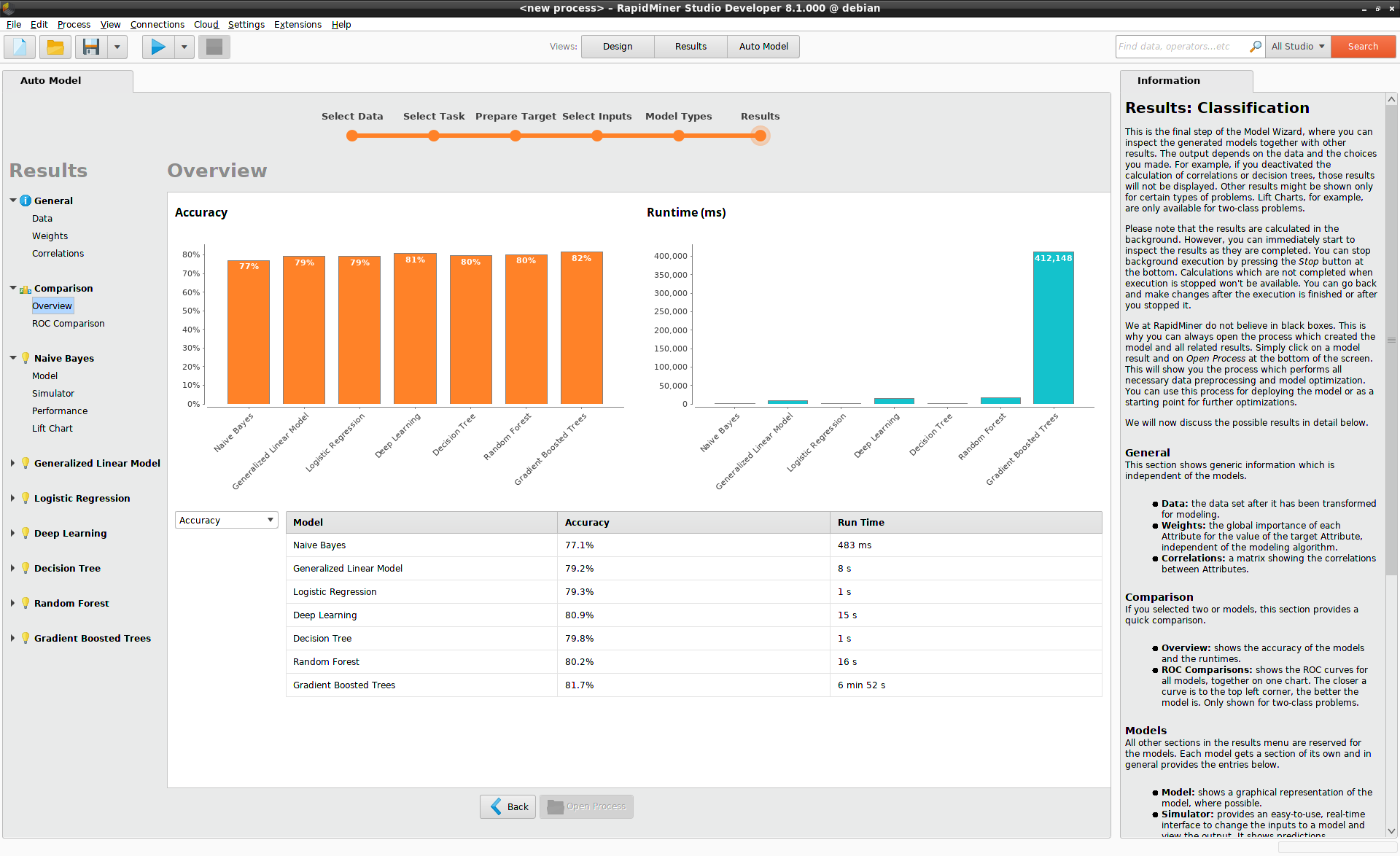
選択したデータセットとモデルによっては、結果を得るまでに時間がかかります。上部のプログレスバーが計算の進捗を追跡しています。Stopボタンをクリックして、いつでもモデル構築を止めることができます。結果が利用可能になると、Comparison > Overviewに中間結果が表示されます。
今回のTitanicデータセットの場合は、Gradient Boosted Trees (XGBoost)モデルが構築にもっとも時間がかかりましたが、正解率ももっとも高いです。Comparison > Overviewより、モデルの正解率や実行時間を比較可能です。Deep LearningよりもGradient Boosted Treesの限界性能の優位性と実行時間がかなり長いことを考慮すると、この場合はDeep Learningを使用するのが好ましいでしょう。
モデルシミュレータとその他の有用なオペレータ
オートモデルは結果を得るのに役立つだけでなく、結果を理解することにも役立ちます。Deep Learningは正確ではありますが直感的でないモデルを作成することで有名です。モデルは Deep Learning > Modelで概要を確認できます。以下から、オートモデルよって提供されたいくつかの便利なユーザーインタフェースを用いてDeep Learningモデルを調べましょう。
モデルシミュレータ
より良い知見を得るために、Deep Learning > Simulatorを選択します。ここでは、スライダーとドロップダウンリストが左にあり、棒グラフが右にあるユーザーインタフェースです。最初の状態では、モデルシミュレータにはデータの平均値が選択されています。タイタニック号では、この平均はサードクラスの約30歳の男性に相当し、船内に比較的親族は少ないです。
右上の棒グラフによると、最も可能性の高いシナリオは、この乗客は生存できないだろうということです。彼の生存率は11%です。下の棒グラフは、彼の何がいけないのかを示し、性別と乗客クラスが緑のバーで表示されています。ここでの緑は、性別と乗客クラスが生存者予測の”No”と一致していることを示しています。乗船運賃と船上の親戚の赤いバーは予測との不一致を意味し、つまり生存と正の相関があることを示しています。
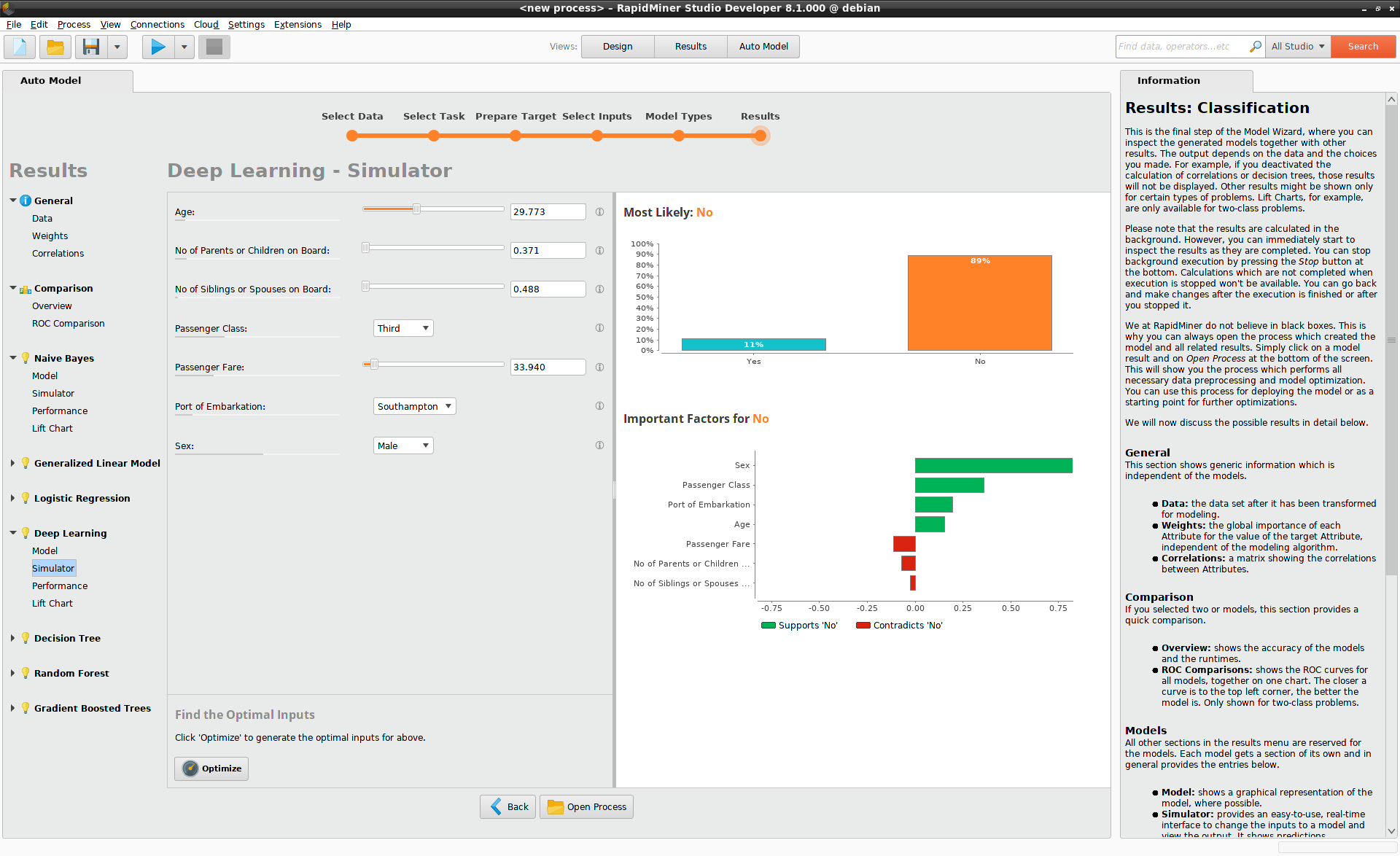
モデルシミュレータの優れた点はインタラクティブな点です。そのため、すべての値を自由に変更でき、予測への影響をすぐに確認できます。例えば、性別を男性から女性に変えると、生存率は約50%まで増加します。乗客クラスをファーストやセカンドに変更すると、生存率は90%まで増加します。
スライダーやドロップダウンリストを操作することで、たとえDeep Learningで構築されたモデルでも、モデルに対しいくつかの直感をすばやく得ることができます。
モデルシミュレータは1つのデータ点の近傍でのモデルの挙動(local correlation)を分析することで予測を作成します。どのデータ列が最もグローバルに重要であるかを確認するには、列名の下に表示されている灰色のバー(global correlation)に注目してください。これらのうち、最も長いバーはSex、Passenger Class、Passenger Fareの順になります。
より詳細な情報は、Model Simulatorドキュメントをご覧ください。
Prescriptive Analytics
次にくるであろう質問は、乗客がタイタニック号で生存する可能性を最大限に高めるにはどうすればよいかということです。
この問いに対しても、オートモデルは答えを持っています!シミュレータの左下に、Optimizeとラベルが付いたボタンがあります。このボタンを押すと、レシピを作るダイアログが表示されます。タイタニック号での男性は女性よりもリスクが高いので、男性の生存戦略を見つけたいと思います。
Optimizeを押し、以下のステップに従って進めます。
- Define Targets > Class to optimize forに”Yes”を選択します。Nextを押します。
- Define Constraints > Constant Attributesで、+ ボタンを押し、”Sex”に”Male”を選択します。Nextを押します。
- Optimization Parametersで、Runを押します。
- Finishを押します。
結果はすぐにシミュレータ内に表示され、その結論は驚くべきものです。タイタニック号で最も生き残る可能性が高い男性の乗客は、小数の親族しかいない4歳の男の子で、セカンドクラスに乗船しています。彼の生存率は91%です。タイタニック号では乗船クラスの影響は間違いなく大きいですが、ドロップダウンリストからPassenger Classを変更するとわかるように、たとえサードクラスに乗船している男の子でも生存率は68%もあります。
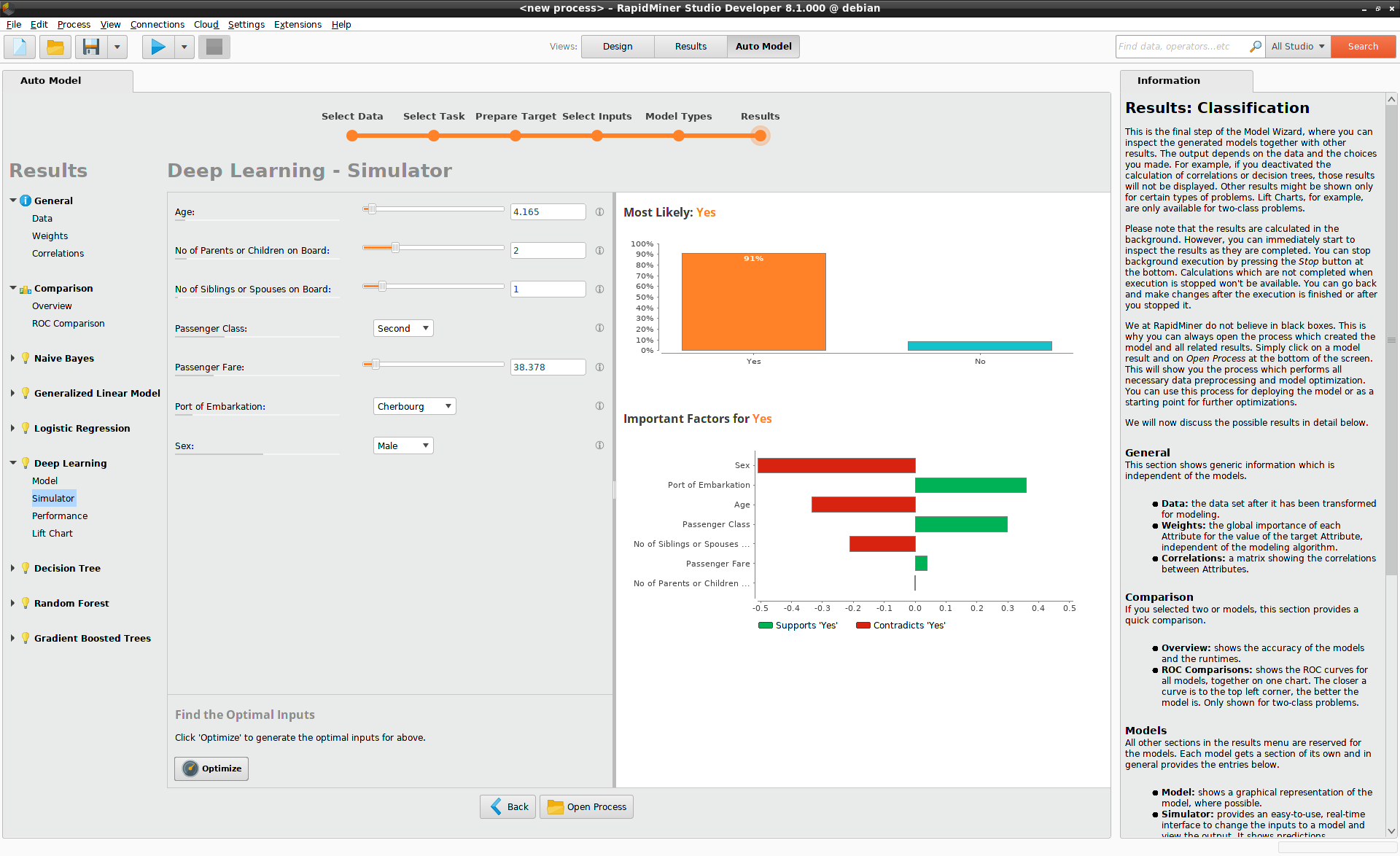
モデルシミュレータによる分析の結果、タイタニック号の乗客は、救命ボートには「女性と子供優先」という理念を厳格に守っていたことがわかります。Ageのスライダーを動かすことで、大人の男性の生存率が下がり続けることが確認できます。男性の乗客の生存率が50%を下回る年齢は、以下の条件になります。
- サードクラスの16歳
- セカンドクラスの26歳
- ファーストクラスの39歳
厳密に言うと、男性乗客の生存の可能性を高めるにはどうすればよいかという問いには、まだ答えていません。もし年齢を考慮すると、より高価なチケットは経済的に手が届かないかもしれません。しかし、最適化機能とモデルシミュレータにより、Titanicデータの理解にとても役立ちました。
より詳細な情報は、 Prescriptive Analyticsドキュメントをご覧ください。
No Black Boxes
オートモデルはたくさんの便利なツールを提供していますが、自分で作成したモデルを確認及び調整を行うことも可能です。画面上部にあるOpen Processボタンを押すと、モデルの構築に使用されたプロセスがデザイン画面に表示されます。このプロセスの実行や編集を好きなように行うことができます。オートモデルは問題を解くツールを提供しますが、ブラックボックスではありません。
どうしてこの点を強調しているのでしょうか? それには少なくとも3つの理由があります。
- モデルの仕組みを理解せずに運用することは不適切であるという点です。モデルがどのように動くか確認し、その内容が自身が想定した動作であるかを確かめたいでしょう。
- 新人データサイエンティストはこのプロセスを確認することで、ベストプラクティスを学ぶことができます。
- データサイエンスの専門家は自身のモデルの開始点としてオートモデルのプロセスを使用し、生産性を上げることができます。

