ターボプレップ
ターボプレップの紹介ビデオ(ショート版 | ロング版)もご覧ください。
データの前処理には時間がかかります。さまざまなソースやフォーマットからデータを集めてきたあなたは、今はこう思っているのではないでしょうか。すべてのデータを適切に整形するにはどうすればいいのか? 何が重要かどう決めたらいいのでしょうか? 他の人が結果を理解するには、どう表示すればいいのか?
ターボプレップはデータの前処理を簡単に行うためのツールです。ターボプレップはいつでも操作中のデータが見えるインタフェースを提供しています。そこにはモデルの構築・プレゼンに使用するためのデータを準備するあらゆる機能が備わっており、変更中のデータを見ながらデータをステップバイステップで変更し、すぐに結果を確認することができます。
バックグラウンドでは、あなたがデータを準備している間に、ターボプレップはRapidMinerのプロセスを作成しています。プロセスを保存し、後から似たデータセットに適用することができます。そのため、同じ作業を二度する必要はありません。
ターボプレップはデータのクレンジングや前処理に特化したものです。データを用いて予測を行い、結果を解釈したい場合は、オートモデルをご覧ください。この時、対象のデータが一貫性のないデータでは予測することはできないでしょう。データについて理解できていれば、ターボプレップはすべてのデータをつなぎ合わせ、価値のないデータを削除し、データを一貫性のある有用なフォーマットへ変換し、結果を表示することに役立つでしょう。
ターボプレップで行える機能は主に五つのカテゴリに分けられます。
- Transform -この機能はデータから有用なサブセットを作成します(Filter, Range, Sample, Remove) 。もしくは個別の列のデータを変更します(Replace)。
- Cleanse – この機能は欠損値、重複値、正規化、ビニングなどのクリーニングを行います。オートモデルで述べられているような低い質のデータは、 Auto Cleansingによって自動で取り除くことが可能です。
- Generate – この機能は既存の列から新しい列を作成します。あらゆる論理処理や数学的な処理は、特徴量エンジニアリングや複雑なデータ変換に特に役立ちます。
- Pivot – この機能はデータから集計表(ピボットテーブル)を作成する作業を簡単にします。
- Merge – この機能は二つ以上のデータセットを結合します(Join)。
ターボプレップの中の🛈マークをクリックすると、これらのカテゴリの詳細を見ることができます。
データの前処理を終えると、以下の 追加アクションを利用できます。
- Model – オートモデルへデータを渡し、モデルの構築を行います。
- Charts – 様々なチャートを用いてデータを表示します。
- Create Process – 後に再利用できるように、データ前処理の過程をRapidMinerプロセスとして保存します。
- History – データ前処理の履歴を確認し、前のステップへロールバックして変更することが可能です。
- Export – データをファイル、もしくはRapidMinerリポジトリへ保存します。
RapidMiner Studio内で、ターボプレップはデザイン画面、結果画面、オートモデルの隣に表示されます。
例: 集計表で結果を表示する
以下から、ターボプレップをTitanicデータセットに適用しましょう。モデル構築へのデータ準備が今回の目的ではないことに注意してください。Titanicデータセットのクリーニングに関する問題は、オートモデルの中で述べられています。ターボプレップはCleansing > Auto Cleansingで同じようにデータをクリーニングすることが可能です。
ターボプレップを用いたデータクレンジングについて、紹介ビデオ もご覧ください。
今回の目的は、生存に関する重要な要因をとらえるたった一つのデータテーブルを作成することです。ここで、私たちは オートモデル のドキュメントの結果を知っていると仮定します。特に、私たちはタイタニック号での生存は次の要因にかかっていることを知っています。
- Sex(性別)
- Passenger Class(乗客クラス)
- Age(年齢)
オートモデルでは対話型モデルの中でこれらの要因を調べることが可能です。今回、私たちはターボプレップを使用して集計表を作成し、結果を表示させます。
これから、このデータを男性と女性の二つに分け、それぞれのデータを別々に調べます。そして、最後にデータを結合させましょう。このような操作を行う理由は、性別はタイタニック号での生存を決める要因の中でもっとも重要であり、また乗客クラスと年齢のような重要な要因の役割も解釈したいためです。
ゴールは、男性と女性の両方を含んだ次のような形式のテーブルを作成することです。
タイタニック号での女性の乗客の生存率
| 年齢 | 1st class | 2nd class | 3rd class |
|---|---|---|---|
| 0-9 | 0.0 | 1.0 | 0.51 |
| 10-19 | 1.0 | 0.92 | 0.55 |
| 20-29 | 0.96 | 0.86 | 0.46 |
| 30-39 | 0.97 | 0.90 | 0.42 |
| 40-49 | 1.0 | 0.91 | 0.25 |
| 50-59 | 0.95 | 0.83 | |
| 60-69 | 0.87 | 0.0 | 1.0 |
| 70-79 | 1.0 |
RapidMiner Studioの上部にあるボタンよりTurbo Prepを選択し、操作を始めましょう。
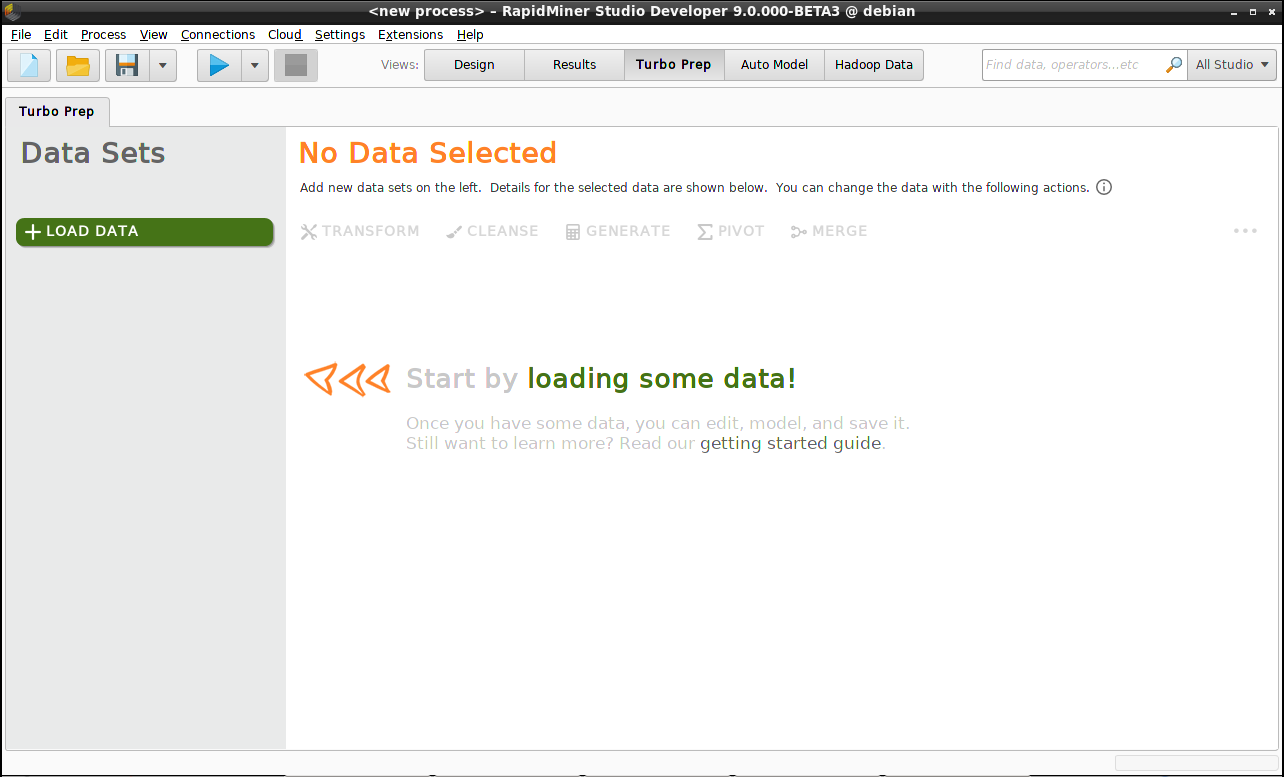
データの読み込み
ターボプレップを起動した後、最初のステップはリポジトリの一つからデータセットを一つ選択することです。
- Load Dataをクリックします。
- リポジトリの Samples > dataの中にあるTitanicデータセットを選択します。(もしデータがリポジトリにない場合は、画面上部のImport Data を選択してください)
- もう一度 Load Data をクリックします。データセットが画面の左側に表示されます。
一度読み込まれると、Titanicデータセットは数々のオプションを持ったコンテキストメニュー(右クリック)を持つことを覚えておいてください。
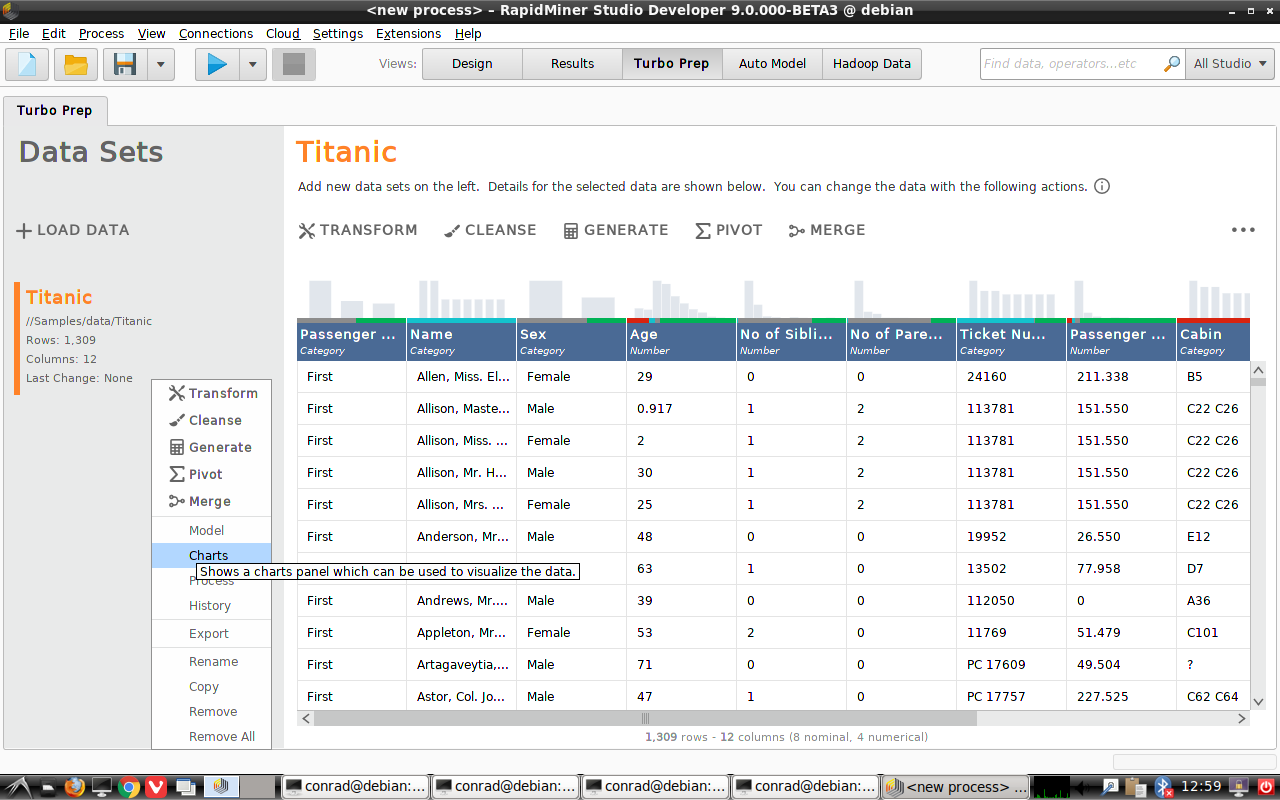
例えば、 Charts を選択し、Chart styleに Histogram Colorを選択します。男女の生存率の違いを見るために、”Sex”を関数として”Survived”をプロットしましょう。(※新バージョンのChartsの場合は、次のように設定します。Plot type: Bar(Column)、Aggregate dataにチェックを入れ、Group by: Survived、Aggregation Function: Count、Value column: “Survived”、Color Group: “Sex”)
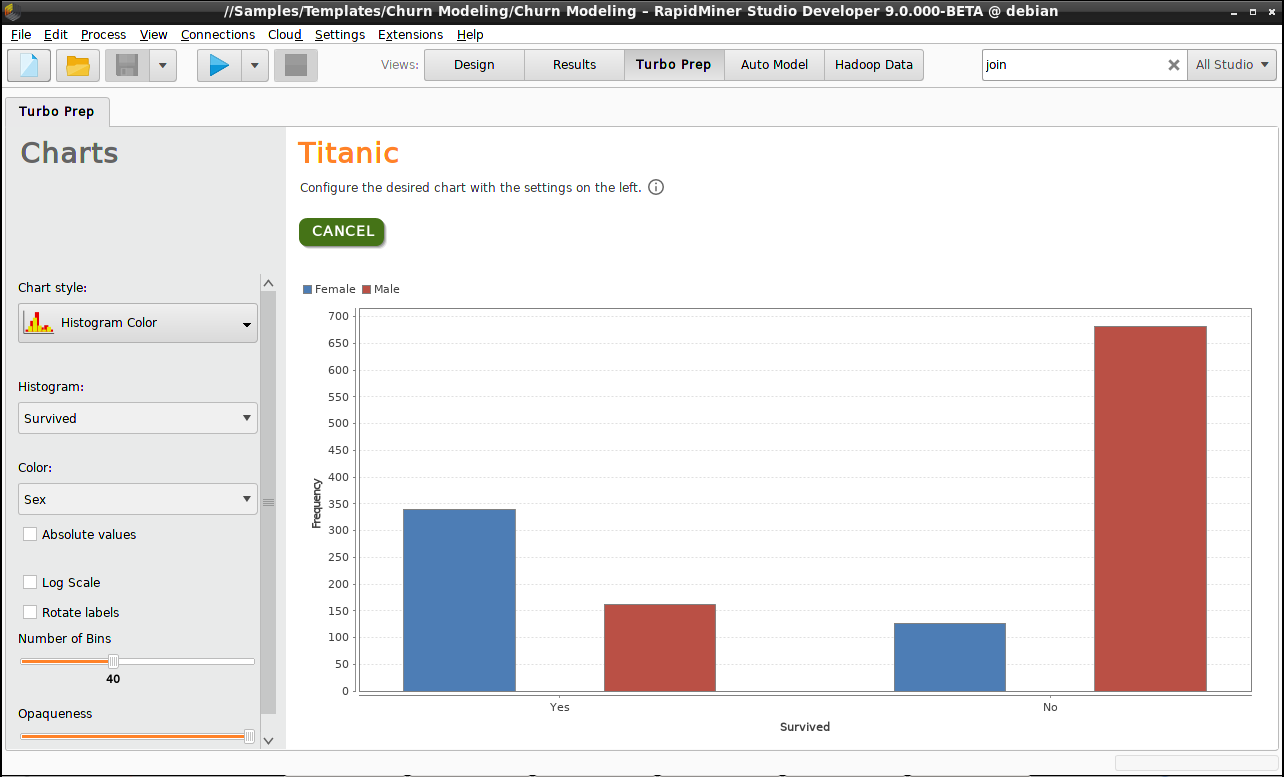
Cancelをクリックすると、チャートビューからデータビューに戻ります。
作成
データビューの上部にある Generateカテゴリを選択します。このカテゴリの機能の目的は、既存のデータ列を基に新しいデータ列を作成することです。例えば、Titanicデータセットは “No of Siblings or Spouses Onboard(船上の兄弟姉妹/配偶者の数)”と”No of Parents or Children Onboard(船上の親/子どもの数)”の二列を含んでいます。もしあなたが新しい特徴を見つけようと考えているなら、これら二つの列を “No of Relatives Onboard(船上の親類の数)” という新しい列に合算するかもしれません。
“Survived”を数値にする
現在の分析では、生存率を測定しようとしています。したがって、平均やほかの統計量を計算しやすいように、”Survived”を”Yes”と”No”ではなく数値の1と0を用いて新しい列を作成しましょう。新しい列に名前(“survived_value”)を付け、式エディタの中で”Yes”を1に、”No”を0に変換する関数を作成します。左側のリストから列名を式エディタの中へドラッグでき、同様に右側のリストから関数を利用できます。
if([Survived]=="Yes",1,0)
Update Preview をクリックすると結果の列を見ることができ、 Commit Generate で結果を保存できます。”Survived”の列は今となっては余分で、それを削除(Transform > Remove)することもできますが、今はする必要はありません。
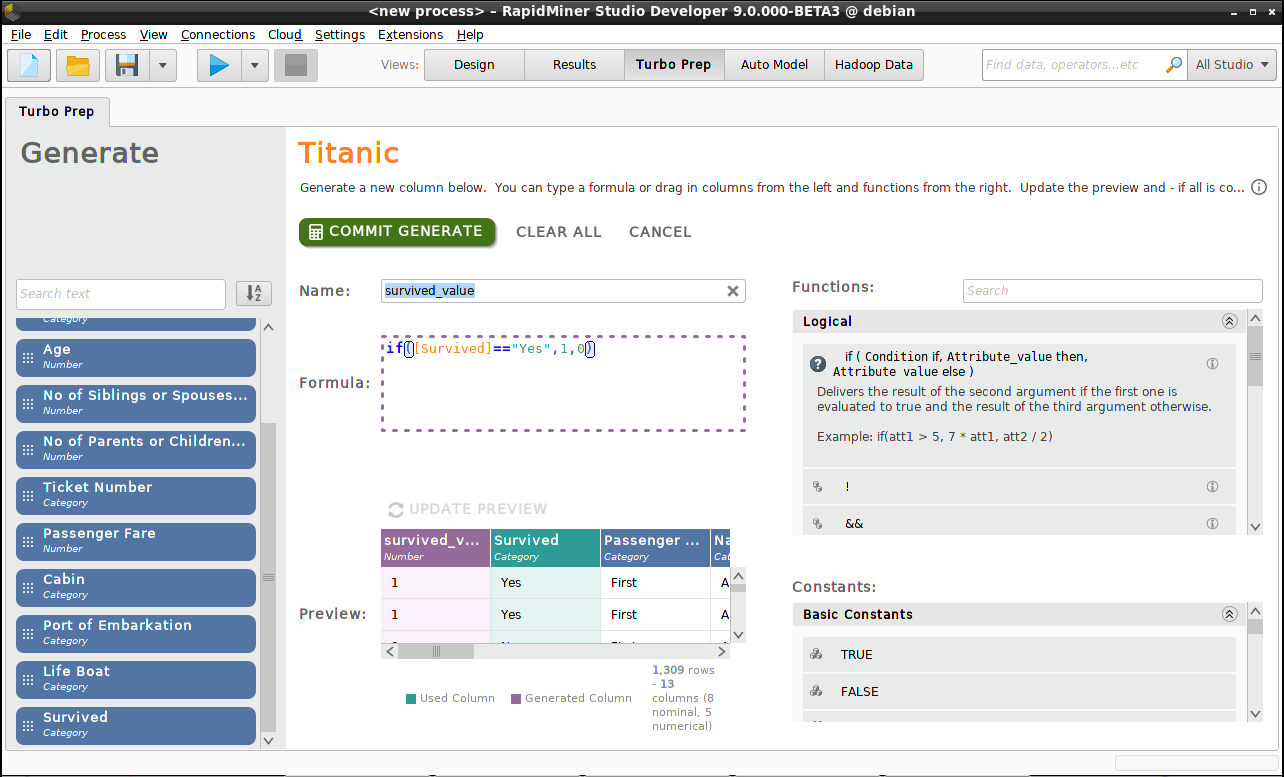
注意: Transform > Replace (“Yes”を1に、”No”を0に置換する)と、 Transform > Change Type (“Change to number”)の組み合わせでよく似た結果を得ることができます。この場合は、新しいデータ列は作成されず、”Survived”のオリジナルのデータ列がカテゴリデータから数値へ変換されます。
“Age”のビンを作成
先ほど、船上での”Passenger Class”と”Age”の影響を解釈したいと述べました。集計表の作成に適したデータにするために、乗客を年齢のグループ(年齢0-9, 10-19, 20-29, etc.)に分けましょう。これを行うために、再び Generateをクリックし、列名(“age_category”)を付け、式エディタで関数を作成します。 floor は丸め込む関数で、20-29の範囲にあるどんな数字も20に丸め込まれることに気を付けてください。
10 * floor([Age] / 10)
Update Preview をクリックすると結果の列を見ることができ、 Commit Generate で結果を保存できます。
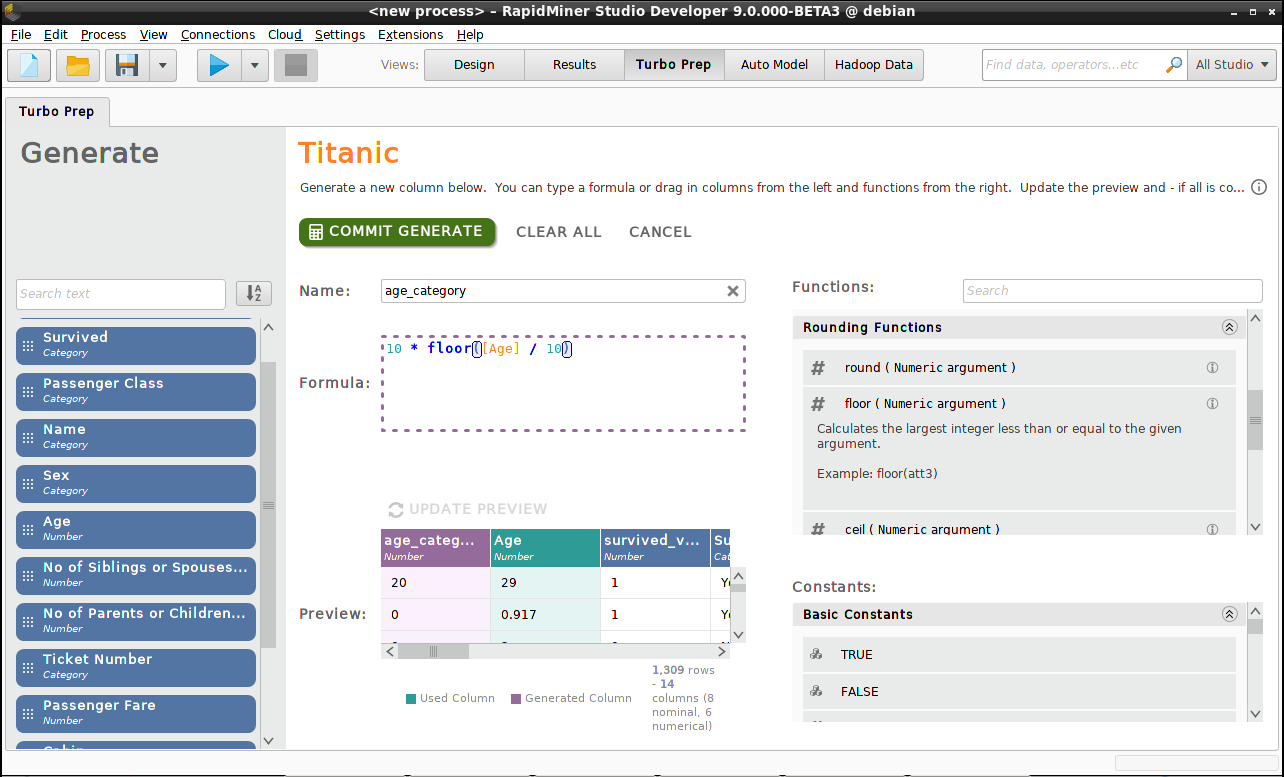
注意: 年齢の範囲が0-80歳であるため、 Cleansing > Discretizationより、”Age”列のデータを等しく8つに分けることでよく似た結果を得ることができます。この場合、新しいデータ列は作成されず、”Age”のオリジナルデータ列が数値から{range1, range2,… range8}の値を持ったカテゴリデータへ変換されます。
データのコピー
Titanicデータセットから二つのコピーを作成し、”Titanic_male”と”Titanic_female”という名前をつけます。
- データビューより、Titanicデータセットを右クリックし、メニューから Copy を選択します。
- コピーを右クリックし、メニューから Rename を選択します。コピーに”Titanic_female”と名前を付けます。
- ステップ(1)と(2)を繰り返して”Titanic_male”を作成します。
これで、三つの独立したデータセットがデータビューに表示されています。男性と女性のデータセットを作成するために、データを変形する必要があります。
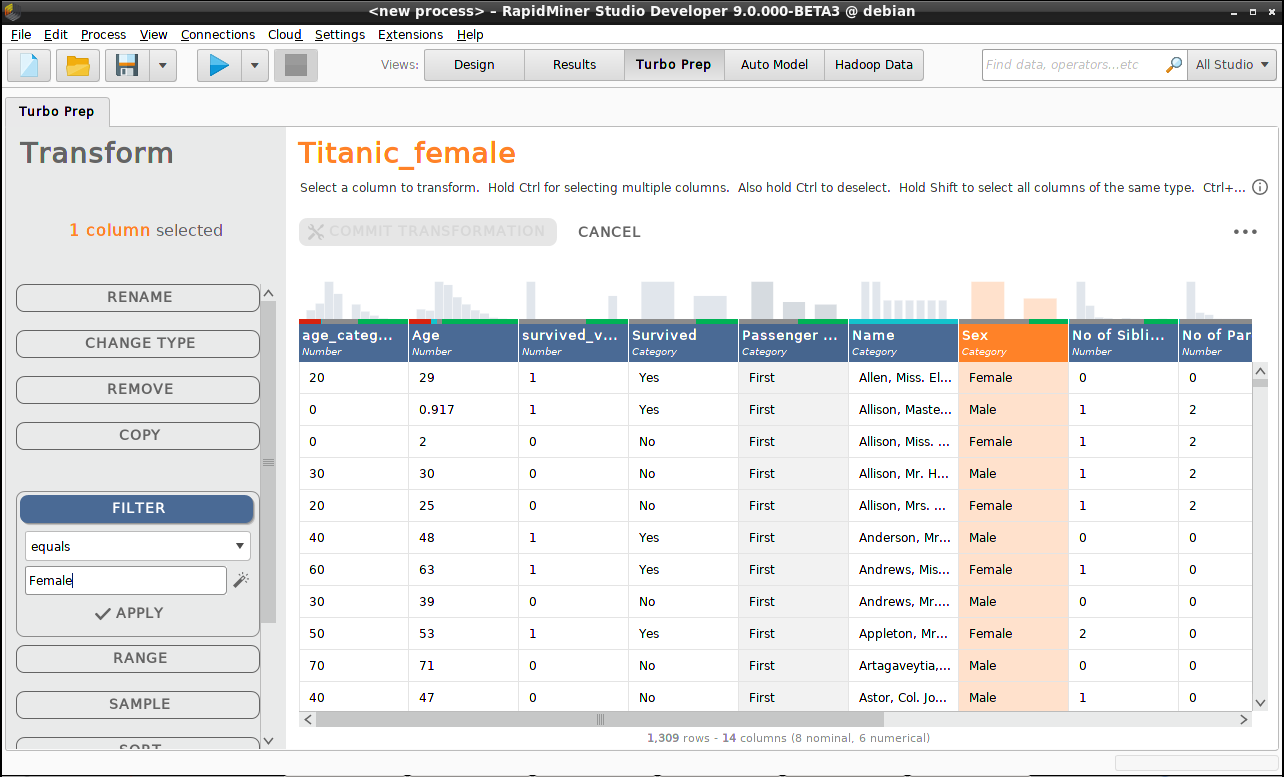
変形
データビューの上部にある、 Transformカテゴリを選択します。”Titanic_female”データセットについて、私たちの目的は、男性の乗客に関するすべてのデータを削除し、女性の乗客に関するすべてのデータを維持することです。
- “Sex”列をクリックします。
- 左側の関数リストから Filter を選択します。リレーションシップに”equals”を、値に”Female”を選択します。 Applyをクリックします。
- Commit Transformationをクリックします。
“Titanic_female”の変形が完了したら、フィルター関数の値に”Male”を用いて”Titanic_male”に対してもこの操作を繰り返します。
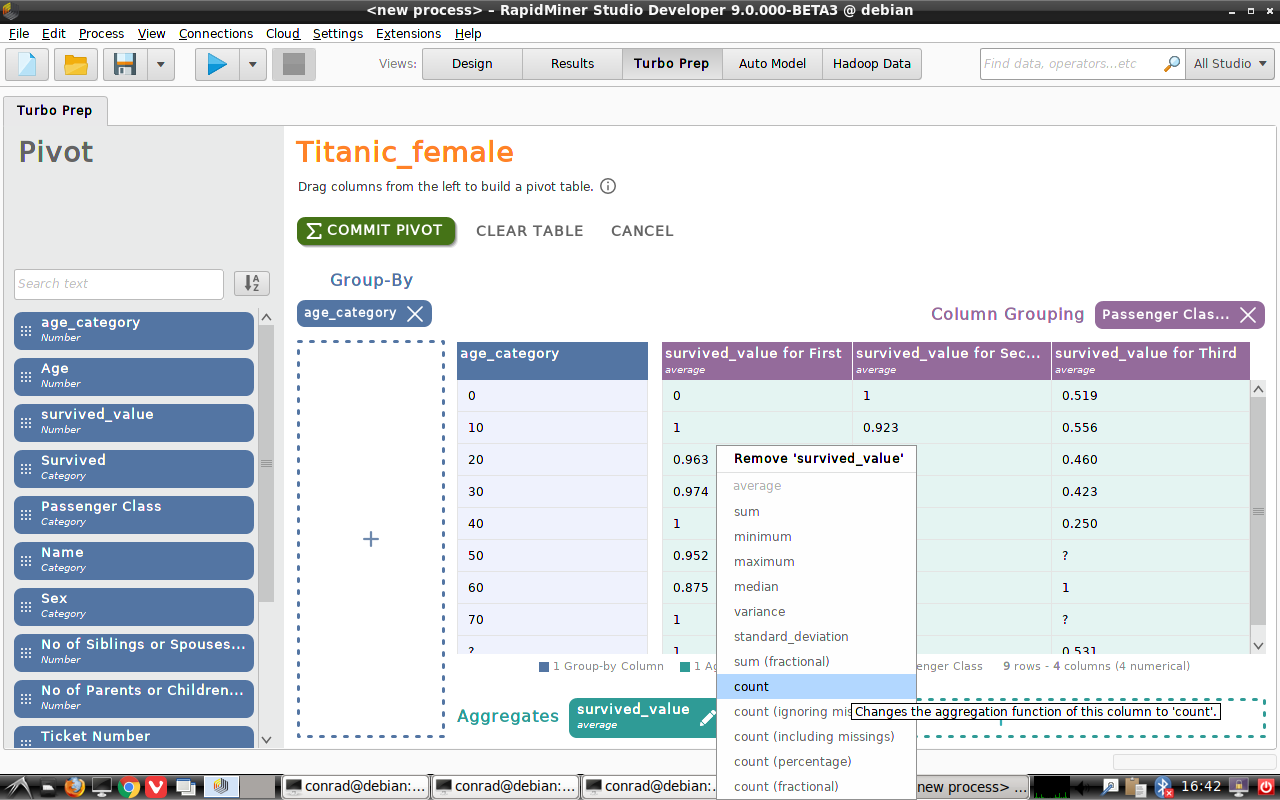
ピボット
ターボプレップを用いたデータのピボットについて、 紹介ビデオ もご覧ください。
データビューの上部より、 Pivotカテゴリを選択します。ピボットテーブルは集計表の一つです。たいてい、行と列はオリジナルのデータセットのカテゴリデータで構成され、個々のセルが合計値(例えば”Total Sales”のような)や平均値(例えば”Survival Rate”のような)形式で数値データを含み、すべてのデータ点はこれらのカテゴリのいずれかに所属します。
ターボプレップを用いると、ピボットテーブルの作成は簡単です。左側から列名をドラッグし、三つの箱の一つに入れるだけです。
- Group-By – ここに選んだカテゴリデータはピボットテーブルの行になります。
- Column Grouping – ここに選んだカテゴリデータはピボットテーブルの列になります。
- Aggregates – ここに選んだ数値データはたいてい合計されるか、平均値化されます。
“Titanic_female”と”Titanic_male”の各データセットに対して、以下のステップで進めていきます。
- “survived_value”を Aggregatesにドラッグします。ピボットテーブルの最初のバージョンは一つの値、ここではすべての女性(男性)の生存率で構成されます。
- “Passenger Class”を Column Groupingにドラッグします。ピボットテーブルには、各乗客クラスの生存率を持った三つのセルがあります。
- “age_category”を Group-Byにドラッグします。年齢(行)とクラス(列)で並び替えると、ピボットテーブルには、各カテゴリに応じた女性(男性)の生存率が含まれています。
今回の例では、生存率は各ピボットテーブルの各セルの”survived_value”の平均をとっています。しかし、”survived_value”を右クリックして”sum”(生存した乗客の人数)や”count”(乗客の合計人数) などの異なった統計量を選択することもできます。
ピボットテーブルを作成できれば、 Commit Pivotをクリックします。
結果
“Titanic_female”と”Titanic_male”の二つのピボットテーブルをよく観察すると、いくつかの結論を導くことができます。
- 女性の乗客の場合、ファーストクラスとセカンドクラスの乗客はサードクラスの乗客よりかなり生き残るチャンスがあった(90% vs 50%)。
- 男性の乗客の場合、ファーストクラスの乗客はセカンドクラスやサードクラスの乗客よりかなり生き残るチャンスがあった(35% vs 15%)。
- 小さな子供でもない限り、サードクラスの男性はセカンドクラスの男性より実際には生き残る可能性が高かった。
- ファーストクラスとセカンドクラスの女性を除いて、40歳以上の乗客は、若い乗客より生き残る可能性が低かった。
女性の乗客の生存率は 上のテーブルで挙げている通りです。
タイタニック号での男性の乗客の生存率
| 年齢 | 1st class | 2nd class | 3rd class |
|---|---|---|---|
| 0-9 | 1.0 | 1.0 | 0.37 |
| 10-19 | 0.42 | 0.06 | 0.08 |
| 20-29 | 0.44 | 0.09 | 0.19 |
| 30-39 | 0.41 | 0.09 | 0.17 |
| 40-49 | 0.32 | 0.05 | 0.06 |
| 50-59 | 0.28 | 0.0 | 0.0 |
| 60-69 | 0.07 | 0.16 | 0.0 |
| 70-79 | 0.0 | 0.0 | 0.0 |
| 80-89 | 1.0 |
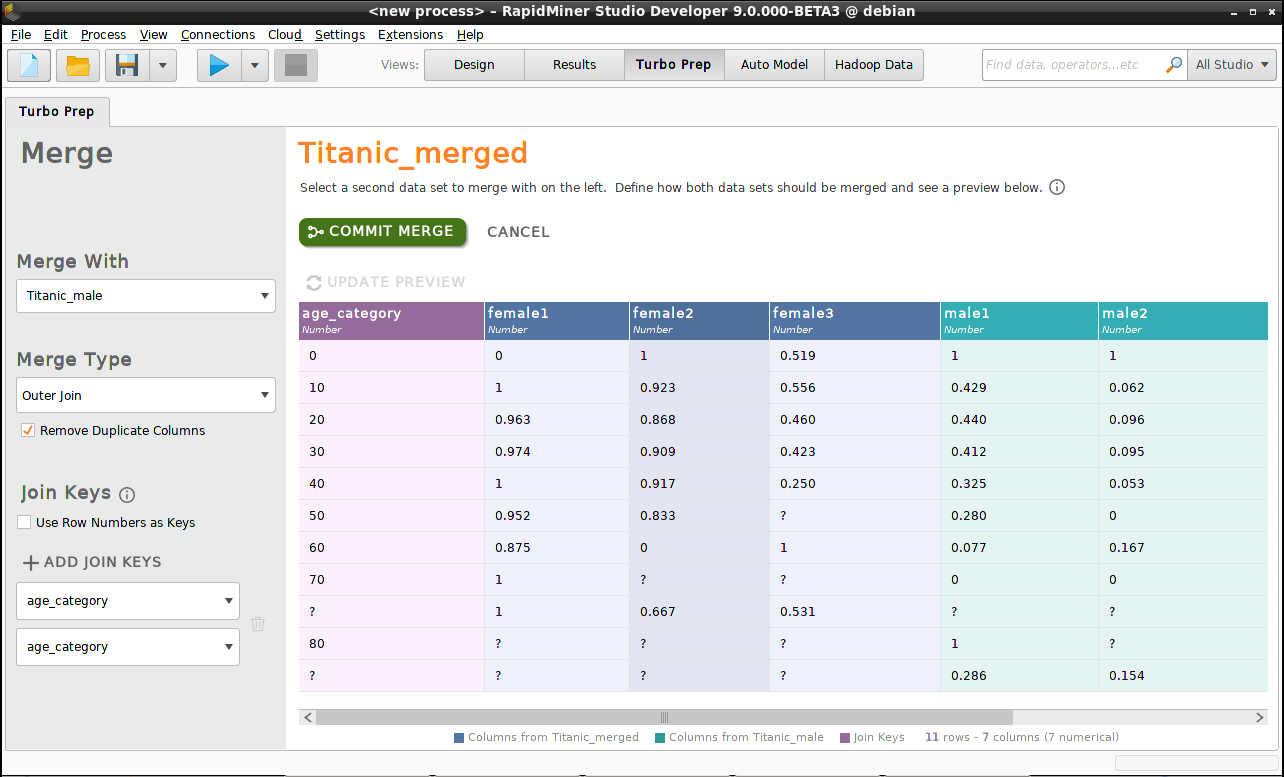
結合
ターボプレップを用いたデータの結合について、 紹介ビデオ もご覧ください。
“Titanic_female”と”Titanic_male”の二つのピボットテーブルを結合させましょう。残念なことに、二つのピボットテーブルはほぼ同じ構造をしており、データセットの名前のみでどちらのデータが男性であるか、またどちらが女性かを分けています。重要な情報を失うことを避けるため、三つのクラスの乗客の名前を変更しましょう(Transform > Rename)。”Titanic_female”ならば{female1, female2, female3}と変更し、”Titanic_male”ならば{male1, male2, male3}と変更します。
それでは、”Titanic_merged”という名前の新しいピボットテーブルを作成しましょう。
- “Titanic_female”を右クリックし、 Copyを選択します。
- コピーデータを右クリックし、 Renameを選択します。”Titanic_merged”と名前を変更します。
データビューの上部より、 Mergeカテゴリを選択します。”join“は、データの各行がユニークな「キー」によって分けられるという考え方に基づいています。二つのデータセットの二つの行が同じキーを持っているとき、それらのデータは結合されます。キーが一つのデータセットのみに存在し、もう一方に存在しないときには混乱が生じます。その場合、結合するテーブルにそのデータを含むか含めないか決めなければなりません。
| 方法 | 結合するテーブルに含まれるデータ |
|---|---|
| Inner Join(内部結合) | 両方のデータセットにあるキーのみ表示する |
| Left Join(左結合) | 最初のデータセットにあるキーのみ表示する |
| Right Join(右結合) | 二つ目のデータセットにあるキーのみ表示する |
| Outer Join(外部結合) | どちらかのデータセット(全てのデータ)にあるキーを表示する |
今回の例では、”join keys”は”age_category”ですが、”Titanic_male”は80歳以上の乗客も含んでおり、”Titanic_female”にそのような乗客はいません。内部結合、もしくは左結合を用いると、このデータは失われてしまいます。含むには、右結合、もしくは外部結合を選択する必要があります。すべてのデータを含む最も確実な方法は、外部結合を用いることです。
- Merge With – “Titanic_male”です。開始点に”Titanic_female”を用いるためです。
- Merge Type – “Outer join”です。これを選択することで、どのデータも失われません。
- Join Keys – “age_category”です。
Commit Mergeをクリックします。”Titanic_merged”に”age_category”が欠損している行があることに気を付けてください。”age_category”をクリックし、 Transform > Filter > “is not missing”を選択することでそれらを削除することができます。
追加アクション (⋯)
残っていることは何でしょうか? 私たちは”Sex”、”Passenger Class”、”Age”の影響を測定する、タイタニック号での生存率を求めるピボットテーブルを作成し、一つのテーブルにまとめることができました。
データビュー右上にある追加アクションメニュー(⋯)にいくつかヒントがあります。
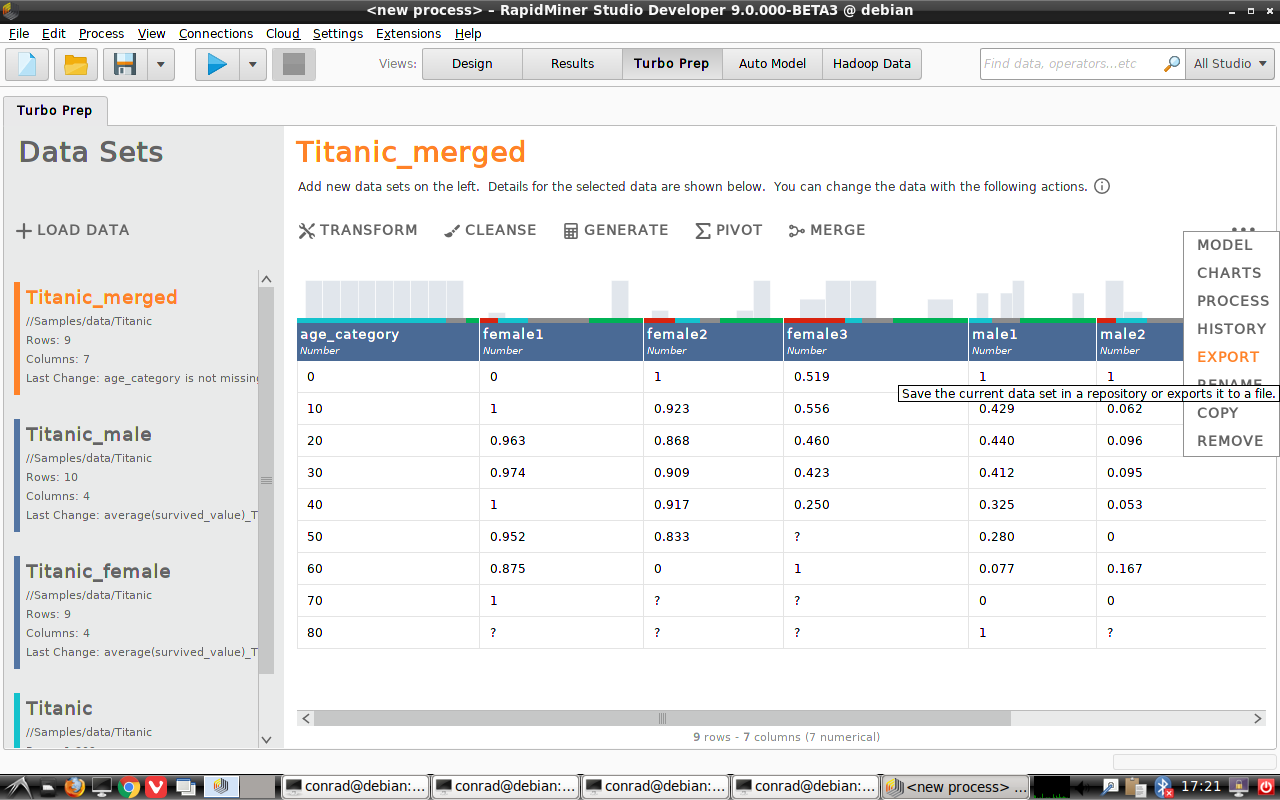
エクスポート
最終的なピボットテーブルをファイルやRapidMinerのリポジトリに保存することができます。利用可能なファイルフォーマットはExcel (.xlsx)、 CSV (.csv)、Qlik (.qvx)です。
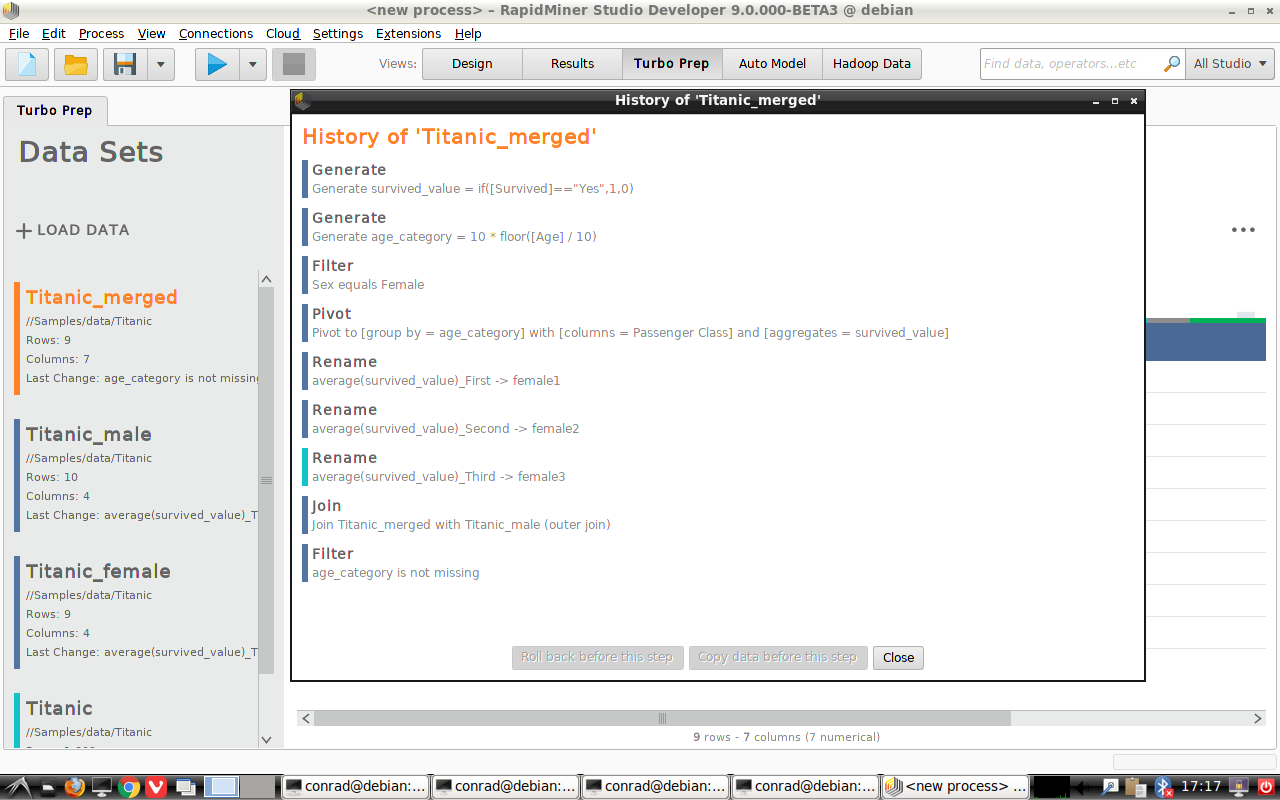
履歴
データの前処理の履歴を確認でき、以前のステップへロールバックし変更することができます。
モデル
今回の例では触れていませんが、もしデータをモデル構築のために準備していたのなら、次のステップは オートモデルになるでしょう。
プロセス
今回の例では触れていませんが、もし週一でデータの新しいバージョンが生成されるなら、RapidMinerプロセスとして今回の作業を保存し、新しいデータセットに適用させることで週一で集計表を作成することができます。
チャート
様々なチャートを用いて、データを可視化することができます。
