Solrコネクタの使用
Solrコネクタを使用すると、Solrサーバーから検索結果を読み取ることができます。Search Solrオペレータを使用すると、さまざまな検索クエリを実行できます。このドキュメントでは、以下の方法について説明します。
Solrエクステンションのインストール
まず、Solrエクステンションをインストールする必要があります。
![]() Install Solr Extension in Studio
Install Solr Extension in Studio
Solrサーバーの接続
Solrコネクタを使用する前に、新しいSolr接続を設定する必要があります。接続の設定には、Solrサーバーの接続詳細が必要です。通常、SolrサーバーのURLは「/solr」で終わります。Solrサーバーのインストールで認証が必要な場合は、有効な認証情報も必要です。
- RapidMiner StudioでSolr接続を保存するリポジトリを右クリックして、
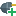 Create Connectionを選択します。
Create Connectionを選択します。
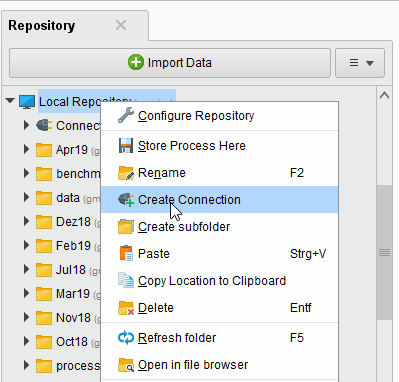
または、Connections > ![]() Create Connectionをクリックし、以下のダイアログのドロップダウンからリポジトリを選択することも可能です。
Create Connectionをクリックし、以下のダイアログのドロップダウンからリポジトリを選択することも可能です。
- 新しい接続の名前を入力し、Connection Typeを
 Solrに設定します。
Solrに設定します。
 Createをクリックし、Edit connectionダイアログのSetupタブに切り替えます。
Createをクリックし、Edit connectionダイアログのSetupタブに切り替えます。- Solrサーバーの接続詳細を入力します。
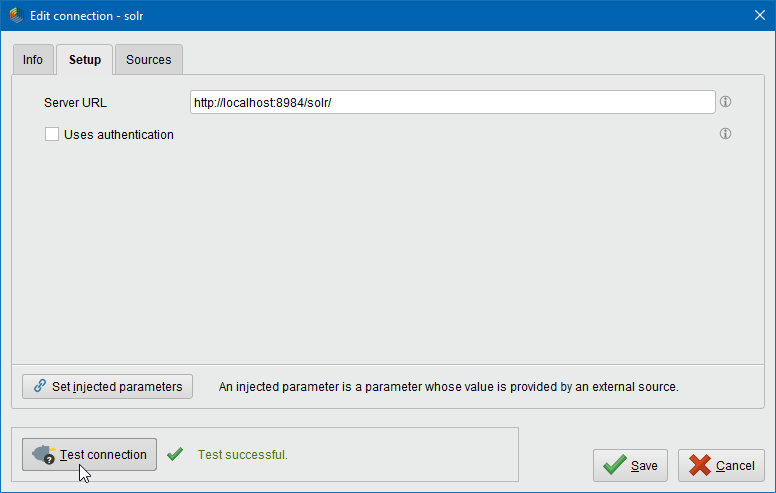
事前に設定されたURLは、ローカルマシン上で動作するSolrサーバーのデフォルトURLです。Solrはデフォルトではユーザー認証を必要としませんが、Uses authenticationを選択するとユーザー名とパスワードを指定することができます。
必須ではありませんが、 ![]() Test connectionボタンをクリックして、新しいSolr接続をテストすることをお勧めします。テストに失敗した場合は、接続設定が正しいかどうかを確認してください。
Test connectionボタンをクリックして、新しいSolr接続をテストすることをお勧めします。テストに失敗した場合は、接続設定が正しいかどうかを確認してください。
 Saveをクリックして接続を保存し、Edit connectionダイアログを閉じます。
Saveをクリックして接続を保存し、Edit connectionダイアログを閉じます。
これで、新しく作成した接続をSolrオペレータで使用することができます!
Solrサーバーの検索
Solrには、Search Solr (Data)とSearch Solr (Documents)の2つの検索オペレータがあります。Search Solr (Data)オペレータは、Solrサーバーにクエリを行い、データテーブルとして結果を得ることができます。Search Solr (Documents)オペレータも同様に動作しますが、データをドキュメントのコレクションとして提供します。これは、Textエクステンションを使用すると、さらに処理が可能です。ここでは、Search Solr (Data)オペレータの設定を説明しますが、Search Solr (Documents)オペレータにも適用できます。
- RapidMiner Studioで
 空のプロセスを作成し、Search Solr (Data)オペレータをプロセスにドラッグし、その出力ポートをプロセスの結果ポートに接続します。connection entryパラメータの横にある
空のプロセスを作成し、Search Solr (Data)オペレータをプロセスにドラッグし、その出力ポートをプロセスの結果ポートに接続します。connection entryパラメータの横にある  ボタンをクリックして、保存先のリポジトリのConnectionsフォルダからSolr接続を選択します。
ボタンをクリックして、保存先のリポジトリのConnectionsフォルダからSolr接続を選択します。
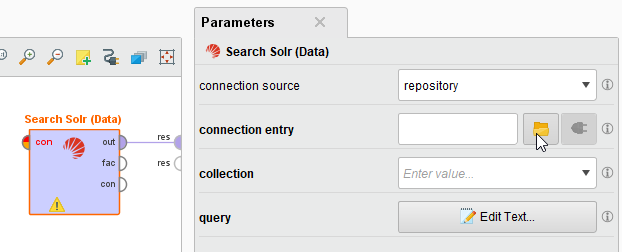
または、リポジトリからプロセスにSolr接続をドラッグして、オペレータの出力をSearch Solr (Data) オペレータに接続することもできます。
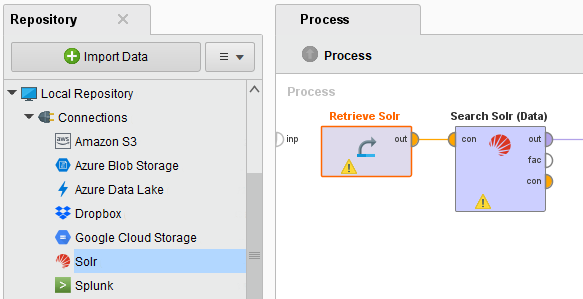
- collectionパラメータのドロップダウンメニューからコレクションを選択します。
- queryパラメータの横にあるボタンをクリックして、検索クエリを定義します。フィルタを追加してクエリを絞り込むことができます。filter queryパラメータが表示されていない場合は、高度なパラメータを表示をクリックして表示します。
- オプションで、faceted searchのdate facets など高度なパラメータを指定することができます。最大検索結果数のデフォルトの上限を100に変更することができます。
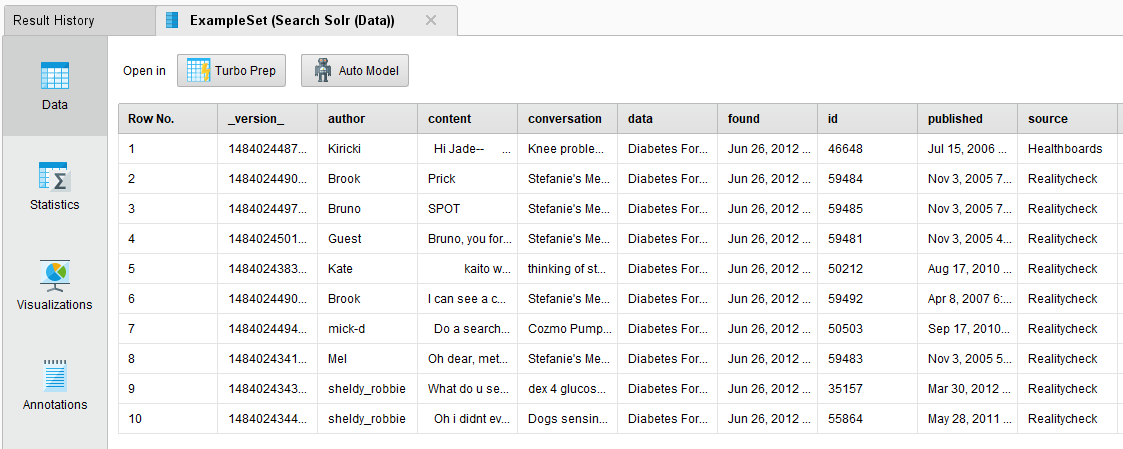
 をクリックしてプロセスを実行します。結果画面には、クエリの結果のテーブルが表示されます。Solrコレクションフィールドが列になり、すべての行がSolrエントリから取得されます。
をクリックしてプロセスを実行します。結果画面には、クエリの結果のテーブルが表示されます。Solrコレクションフィールドが列になり、すべての行がSolrエントリから取得されます。
同じ手順で、Search Solr (Documents)オペレータを使用します。collectionとqueryを指定した後、document body fieldを選択できます。このパラメータは、どのSolrフィールドがRapidMinerのドキュメントボディに格納されるかを指定します。他のSolrフィールドはドキュメントのメタデータレコードになります。
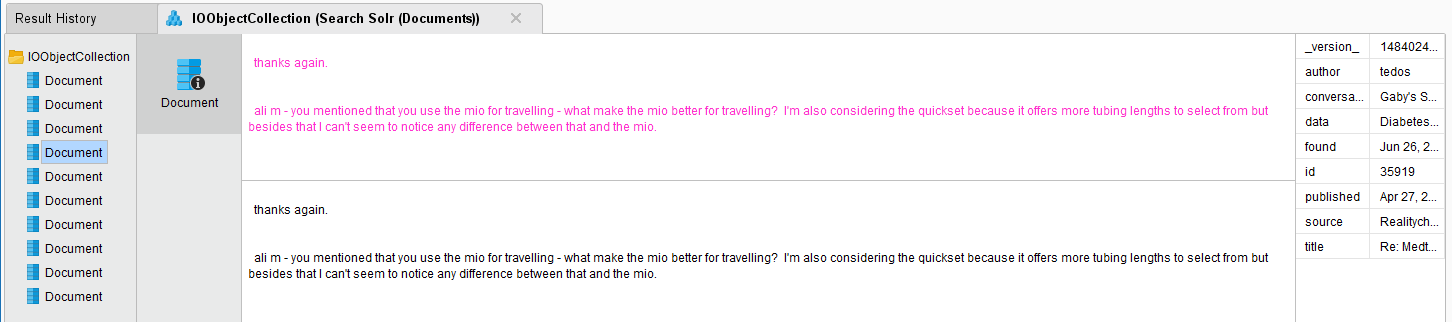 これで、すべてのSolrエントリはSearch Solr (Data)オペレータのように、行ではなくドキュメントに変換されます。
これで、すべてのSolrエントリはSearch Solr (Data)オペレータのように、行ではなくドキュメントに変換されます。
Solrサーバーの追加
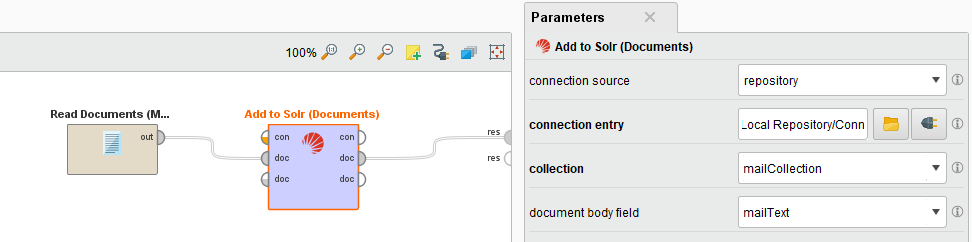
Solr検索に関しては、Solrに追加するオペレータが2つあります。Add to Solr (Data)は、データテーブルの内容をSolrサーバーにアップロードします。Add to Solr (Documents)オペレータも同様に機能しますが、Textエクステンションからのドキュメントのコレクションとしての入力を想定しています。
ここでは、Add to Solr (Data)オペレータの設定を説明しますが、Add to Solr (Documents)オペレータにも適用できます。
- RapidMiner Studioで
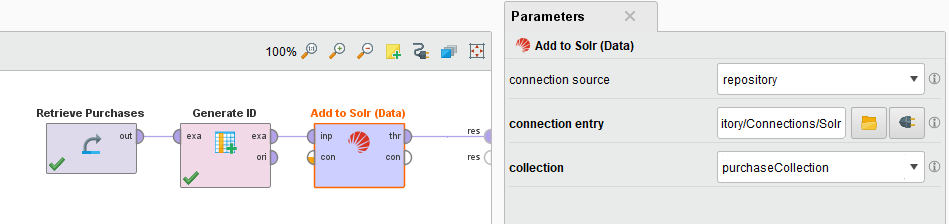
 空のプロセスを作成し、Add to Solr (Data)オペレータをプロセスにドラッグし、上記のように接続を指定します。
空のプロセスを作成し、Add to Solr (Data)オペレータをプロセスにドラッグし、上記のように接続を指定します。 - collectionパラメータのドロップダウンメニューからコレクションを選択します。
- オペレータの入力ポートを、追加するデータテーブルと接続します。すべての列がSolrフィールドになり、すべての行がそれぞれのフィールドのSolrエントリになります。
Add to Solr (Documents)オペレータは、ドキュメントのコレクションを入力として使用するだけで、全く同じように機能します。ドキュメントのメタデータレコードは、キーと関連する値で構成されています。キーはSolrフィールドになり、1つのドキュメントは関連する値を持つSolrエントリを指定します。ドキュメントには追加のボディがあるため、document body fieldパラメータを使用して、そのためのSolrフィールドを指定することができます。