Deep Learningエクステンションのインストール
免責事項: このドキュメントでは、RapidMinerのDeep Learningエクステンションの設定方法と使用方法について説明しています。ここではDeep Learningのコンセプトについては説明していません。
目次
GPUは必要か
Deep Learningについて話す際に、少なくとも大規模なデータセットでは、以下の場所のいずれかに1つ以上のCUDA対応のGPUを利用できる方が有利であることを最初に指摘しなければなりません。
- 自身のコンピュータ上
- RapidMiner AI Hub上
- クラウド上
しかし、データセットが小さいか、もしくは単にDeep Learningエクスションに慣れたい場合であれば、GPUは必要ありません。必要なことは、RapidMiner Studio内にRapidMinerマーケットプレイスから以下の2つのエクステンションをインストールすることのみです。
上記に加えて、(オプションで)自身のアプリケーションに関連する追加のエクステンションもインストールします。例えば以下です。
AI Hub上でプロセスを実行することを計画している場合は、RapidMiner AI Hub上にも同じエクステンションをインストールします。
少なくとも今はまだGPUを使用しない予定であれば、これで準備ができました。追加のソフトウェアは必要ありません。製品内のDeep Learningオペレータのヘルプテキストを確認し、リポジトリのSamples/Deep Learningにあるサンプルプロセスを見てみてください。紹介までスキップすることができます。
ND4J Back End
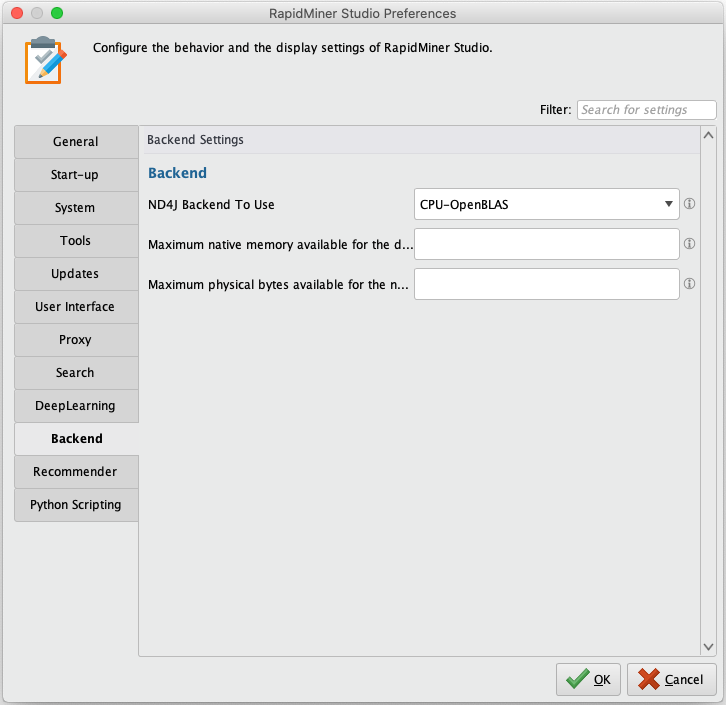
より良いパフォーマンスを得るために、上記で述べた最低限の(デフォルトの)セットアップ以上のことを行いたい場合は、追加のソフトウェアをインストールする必要があります。ND4J Back Endエクステンションは、ニューラルネットワークの学習とスコアリングの計算バックエンドを提供し、設定することに注意してください。現在、3つのバックエンドが選択できます。
- CPU-OpenBLAS (デフォルト): デフォルトのバックエンドは、プロセスが実行されるマシンのCPUを使用します。計算にはOpenBLASライブラリが使用されます。追加のソフトウェアをインストールする必要はありません。RapidMiner Studioで最初のネットワークのセットアップや、より小さなデータセットのテストを行う場合、このオプションを選択します。
- CPU-MKL: このオプションはIntelのMKLライブラリを使用して、CPUでの計算を高速化します。GPUはないが、IntelのMKL対応のCPUがある場合に推奨されます。Intel Math Kernel Libraryをインストールする必要があります。
- GPU-CUDA: このオプションは利用可能な1つのGPU上で高速計算を提供します。自身のGPUと互換性があるか確認した後、NVIDIAのCUDAバージョン10.1をインストールする必要があります。GPUがGPUアクセラレーションライブラリのcuDNN(バージョン7.6)もサポートしている場合は、パフォーマンスを高めるために、これもインストールすることを推奨します。
CPU-MKLとGPU-CUDAバックエンドのどちらに対しても、インストールしたライブラリがクラスパス上で利用可能か確認してください。例えば、それらをLD_LIBRARY_PATH環境変数に追加するなどです。
詳細: 設定
CUDA と cuDNN
RapidMiner Studioと一緒にGPUを使用する場合は、NVIDIAのCUDAバージョン10.1とcuDNNバージョン7.6をインストールする必要があります。
RapidMiner AI Hubのユーザーには、Deep Learning用に特別に設定されたDockerイメージを使用する別の方法を提供しています。これらのGPU対応のDockerイメージでは、CUDAとcuDNNはプリインストールされ、設定もされています。
Deep Learningエクステンションの紹介
RapidMinerのDeep Learningエクステンションでは、シーケンシャルニューラルネットワークの作成と利用はできますが、(まだ)非シーケンシャルニューラルネットワークの作成はできません。ネットワークは、ネスト構造を持つDeep LearningまたはDeep Learning (on Tensor)オペレータ内で、レイヤーオペレータを次々追加していくことで作成できます。レイヤーオペレータにはすべて、Add <LayerType>オペレータの名前が付けられ、<LayerType>にはレイヤーのタイプ名が付きます。例えば以下です。
- fully-connected
- CNN
- LSTM
他のRapidMinerのオペレータとは違い、ブレークポイントを設定してレイヤーオペレータの途中の出力を得ることはできません。これらのレイヤーオペレータはネットワーク構造の設定に使用されるだけで、出力ポートではその時点までの構造の設定を提供するのみです。
バックグラウンドで自動的に行われるため、次元の処理用のレイヤーを追加する必要はなく、手動でデータの入力型を定義する必要もほぼありません。そのため、Flatten層は必要ありません。
学習に使用するエポック数やearly-stopping機能のような一般的なパラメータは、前述したネスト構造をもつDeep Learningオペレータのパラメータで設定されます。一方、使用するニューロンの数や活性化関数のような個々のレイヤーの設定は、それぞれのAdd <LayerType> Layerオペレータでレイヤーごとに設定します。ただし、バイアスと重みの初期化は例外です。バイアスと重みの値を初期化する方法には、Deep Learningオペレータからすべてのレイヤーに対して設定する集中型と、レイヤーオペレータに対してoverwrite networks weight/bias initializationパラメータを選択して個々に設定する方法があります。
与えられた学習データと潜在的なテストデータから得られたスコアだけでなく、レイヤーの重みやバイアスも、Deep Learningオペレータの出力ポートから得ることができます。さらに、RapidMiner StudioやRapidMiner AI Hubのログ、または提供されているwebインターフェイスよりスコアを監視することができます。
Deep Learningエクステンションにより、CPUやGPU環境に応じて異なる計算バックエンドを動作させることができます。これらのバックエンドは、ND4J Back Endという名前の、依存関係のあるバックエンドエクステンションを通じて利用できます。またこのエクステンションでは、メモリを扱う特定のパラメータの設定も可能です。CPUを利用したネットワークの作成と使用は、WindowsやmacOS、ほとんどのLinuxディストリビューションで動作しますが、GPUによる計算は、CUDA 10.1と動作するNVIDIAのGPUに対して、WindowsやLinuxのみサポートしています。
バックエンドエクステンションの名前がすでにヒントになっていますが、Deep LearningとバックエンドエクステンションはDeepLearning4Jプロジェクトを基にしています。DeepLearning4J(DL4J)は、計算バックエンドやディープラーニング機能などを含む、数値計算のライブラリを提供するオープンソースなプロジェクトです。現在使用されているDL4Jライブラリのバージョンは、常にリリースノートに記載されています。
設定
ここでは、RapidMiner Studio内のDeep Learning/ND4J Back Endエクステンションの設定について記載しています。
以下もご参考ください: RapidMiner AI Hub上でのDeep Learning/ND4J Back Endの設定
計算バックエンド
上記で述べたように、Deep Learningエクステンションが機能するには、ND4J Back Endエクステンションが必要です。なぜなら、ND4J Back Endはニューラルネットワークの学習やスコアリングに使用される計算バックエンドの提供や設定を行うためです。
RapidMiner Studioでは、設定 > プリファレンスからプリファレンスダイアログを開き、Backendを選択して、ND4J Backend To Useを以下の値から設定します。
- CPU-OpenBLAS (デフォルト)
- CPU-MKL
- GPU-CUDA
メモリの制限
学習やスコアリングに必要な計算はJava Virtual Machine(JVM)の外側で行われるため、使用するメモリに制限をかけることが推奨されます。
RapidMiner Studioでは、設定 > プリファレンスからプリファレンスダイアログを開き、Backendを選択して、Maximum native memory available for the deep learning backendを設定します。
トレーニング UI ポート
トレーニングUIにポートを設定すると、現在実行している学習プロセスをwebブラウザから監視することができます。表示される情報には、エポックや、学習データとテストデータ(提供されている場合)から計算された各スコア、レイヤー構造についてのメタデータが含まれています。
RapidMiner Studioでは、設定 > プリファレンスからプリファレンスダイアログを開き、DeepLearningを選択して、DeepLearning Training UI Portを設定します。
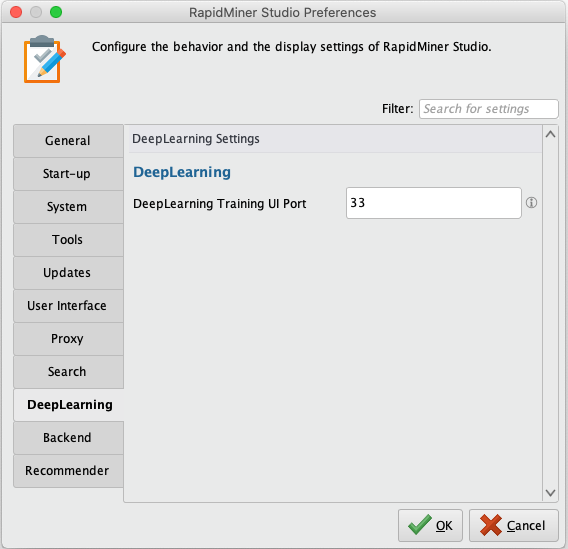
トレーニングUIにアクセスするには、ブラウザを開き、URLにlocalhost(または自身のコンピュータのIPアドレス)を入力し、コロンと設定したポート番号を入力します(例:localhost:33)。
データハンドリング — テンソルと次元
ニューラルネットワークは、RapidMinerのExampleSetのような二次元のテーブルデータだけでなく、画像やテキスト、多変量時系列のような三次元データなどにも適用することができます。ニューラルネットワークはテンソル形式での数値データを必要とし、多くの場合正規化が有効であるため、データのタイプによって必要となる前処理が異なります。
RapidMinerでは、データセットの前処理を行うオプションが数多く用意されています。この章では、使用するデータタイプごとに便利な機能を紹介し、Deep Learningオペレータの次元の扱い方や、クラウド上に保存されたデータの活用法について説明します。
テーブルデータ(ExampleSets)用と、テンソルデータ(ここでは主に画像、テキスト、時系列)用に、2つのDeep Learningオペレータがあることに注意してください。また、通常のRapidMiner内のExampleSetsは二次元配列ですが、三次元配列の同義語として「テンソルデータ」という用語を使用することに留意してください。
- Deep Learningオペレータ – 入力にExampleSetsのみを受け付けます
- Deep Learning (Tensor)オペレータ – 他のすべてのタイプのデータを受け付けます
Apply Modelオペレータも2つあることに注意してください。
- Apply Model – Deep Learningで作成されたモデルと使用します
- Apply Model (Generic) – Deep Learning (Tensor)やDeep Learningで作成されたモデルと使用します
入力型 / アップスケーリング / ダウンスケーリング
どちらのDeep Learningオペレータも、デフォルトではデータの入力型を推測しようとします。これは多くの場合で正常に機能します。期待した入力型が認識されない場合は、高度なパラメータのinfer input shapeを無効にし、設定したいnetwork typeを選択して、次元に関する新しいパラメータに値を入力することができます。
ネットワークの内側では、レイヤー間で次元のアップスケーリングとダウンスケーリングが自動的に行われます。
Decoderなどを作成するための、アップサンプリングを行う追加レイヤーはまだ利用できません。
ExampleSets
ExampleSetsは二次元配列で、行と列のみが利用できます。Deep Learningオペレータはこれをネイティブに処理します。ダミーエンコーディングが自動的に行われるため、項目型のラベルを与えることも可能です。ニューラルネットワークの学習と適用ができるように、他のすべての列は意味のある数値表現に変換するようにしてください。例えば、Nominal to numericalやParse Numbersなどのオペレータを使用して、特別属性ではないすべての属性を数値に変換することができます。
シーケンシャルデータ (例: 時系列)
シーケンシャルデータは非シーケンシャルデータと比較すると、エントリの実際の順序が重要であるという明確な違いがあります。したがって、整列したExampleSetを与える必要があります。以下の2つの形式で系列データを与えることができます。
オプション 1
ExampleSet to Tensorオペレータは、2列を持つ長いExampleSetを入力に受け付けます。1列目は各行にシーケンスを割り当てるバッチIDに使用され、2列目のIDで与えられたシーケンスの順番を区別します。このオプションは、データベースから時系列データを読み込む際などに推奨されます。
例: 5つの測定値をもつ10テンソルの時系列で、各測定値は20のタイムステップを含んでいる場合、100エントリ(行)と12属性(列)をもつExampleSetになります。2属性はID属性と呼ばれ、残りの10属性はセンサーの読み取り値を表しています。バッチIDは1から5のエントリを含み、各エントリは20回出現します。シーケンスIDは1から20までカウントされ、5回出現します。バッチ間で様々な長さのシーケンスを持つことも可能で、その場合エントリの数値はバッチごとに異なります。ニューラルネットワークに必要なデータのマスキングは、自動的に行われます。
オプション 2
TimeSeries to Tensorオペレータは、ExampleSetのコレクションを入力に受け付けます。与えられたExampleSet内の各行はタイムステップやテキストのトークンなど、シーケンスの一部を表し、各ExampleSetは1つのシリーズ全体を表しています。このオプションでは、ID列のような列を作成する必要はありません。シリーズIDが与えられた各ExampleSetの順番より取得されます。異なる長さのExampleSetを持つことも可能で、シーケンスのエントリの数字も異なります。ニューラルネットワークに必要なデータのマスキングは、自動的に行われます。
現在はmany-to-one と many-to-manyシナリオへのネットワークの学習がサポートされています。前述のどちらのオペレータも、ラベルが一定かそうでないかでシーケンスのタイプを推測します。このオプションは上書き可能です。
many-to-oneは、例えば、分類のシナリオのような、一連のエントリで1つの値を予測するような場面で使用されます。一方、many-to-manyは与えられた一連の入力で、複数の予測が行われるときに使用されます。
テキスト
Text Processing と Word2Vecエクステンションも参照してください。
ニューラルネットワークは内部の計算に数値データを必要とします。したがって、テキストは最初に数値表現に変換される必要があります。テキストから数値表現への変換は、よくWord2VecやGloVeなどの単語埋め込みを使用して行われます。これらの埋め込みは、学習させた単語ごとに数値ベクトルを与えるようテキストコーパスで学習された、事前学習済みの表現です。これらの埋め込みを使用してテキストを変換するには、最初にテキストをトークン化させる必要があります(例えば、Text Processingエクステンションのオペレータの使用など)。その後「Text to Embedding ID」オペレータを使用して、選択した埋め込みの辞書のIDに各トークンを変換できます。このIDは後でニューラルネットワーク内で数値ベクトルに変換されます。したがって、ネットワークへの最初のレイヤーとして、埋め込み層を追加する必要があります。データセットをスコアリングした後は、これらのIDは各トークンに戻す際に使用されます。
単語埋め込みは様々なソースからダウンロードでき、Word2Vecエクステンションを使用するなどで、自身のコーパスを基に作成することも可能です。多くのケースでは、既存の埋め込みを使用することが推奨されます。多くのケースでは、既存の埋め込みを使用することが推奨されます。
画像
Image Handlingエクステンションも参照してください。
画像はImage Handlingエクステンションを使用して、読み込みや前処理が可能です。このエクステンションは、フォルダ名をラベルに使用して、ディレクトリから画像のパスのリストを読み込むオペレータを提供します。これらのパスは後で画像にアクセスし、学習に必要になる直前に画像に対して前処理を行うために使用されます。
Pre-Process Imagesオペレータは、Deep Learning (Tensor)オペレータに入力できる、テンソル出力ポートを持ち、それによりネットワークは与えられた画像を数値表現で得ることができます。
Group Model (Generic)オペレータを使用して、Pre-Process Imagesオペレータからの前処理モデルと、学習したDeep Learningモデルを結合した1つのモデルを得ることができ、未知の画像へ適用できます。
クラウドデータ
大量の画像へのアクセスには、Amazon S3やAzure Data Lakeのようなクラウドデータストレージが使用されることが多くあります。Read Amazon S3とRead Microsoft Data Lake Storageオペレータを使用して、RapidMiner Studioから画像へアクセスし、GPU対応のジョブエージェントに使用されるDockerイメージに接続された永続性ボリュームに書き込みます。その後、Read image meta-dataオペレータを使用して永続性ボリュームからこれらの画像を読み込むことで、ネットワークの微調整に様々なパラメータを繰り返す際に時間と帯域幅を節約することができます。
モデルのインポート (Keras)
Deep Learningエクステンションでは、Keras (オリジナルのマルチバックエンドのKerasとTensorflow Kerasの両方)を用いて作成されたモデルのインポートが可能です。現在、インポートはSequentialモデルに限定されています。
RapidMiner内でKerasモデルを使用するには、Kerasのsave_model関数を使用して、アーキテクチャと重みの両方を含んだhd5ファイルにエクスポートします。その後、このモデルのファイルはRead Keras Modelオペレータを使用して読み込み可能です。このオペレータはモデルをネイティブのDL4Jモデルに変換し、RapidMiner内でApply Modelオペレータを用いて適用できます。Pythonをインストールする必要はありません。
分類タスクが行われる場合は、オペレータのパラメータを使用して、項目値を使用するクラス値の数値表現で定義することができます。
クラウドでの学習ワークフロー
- 一般的に、Deep Learningでは、GPUでのモデル学習が望まれます。好みのクラウドサービスプロバイダ上で、RapidMinerのDeep Learningテンプレートをデプロイできます。
- RapidMiner Studio上でプロセスとして最初のネットワークを作成し、ローカルでテストします。
- GPUでの学習用にプロセスを準備します。
- 上記で述べたように、クラウドデータへのアクセスを設定します。
- 選択したもののstoreオペレータやwriteオペレータを使用して、結果を保存できるか確認します。
- バッチサイズを増やして、GPUから利用できるメモリを活用します。
- early stopping機能を設定して、要件が満たされればすぐに学習を止められるようにします。
- 学習プロセスをRapidMiner AI Hubインスタンスに移動させ、GPU対応のジョブエージェント上で実行します。
- オプション: トレーニングUIポートを使用して、学習スコアを監視します。
