Azure Data Lake Storage Gen2接続の使用
本ガイドでは、Gen2 Azure Data Lake Storageアーキテクチャを対象としています。古いストレージ・アーキテクチャについてはGen1のドキュメントを参照してください。
Azure Data Lake Storageコネクタを使用すると、RapidMiner Studioから直接Azure Data Lake Storage Gen2アカウントにアクセスすることができます。読み込みと書き込みの両方の操作がサポートされています。また、![]() Loop Azure Data Lake Storage Gen2オペレータを使用して、Azure Data Lake Storageディレクトリ内の一連のファイルを読み込むこともできます。このドキュメントでは、以下の方法について説明します。
Loop Azure Data Lake Storage Gen2オペレータを使用して、Azure Data Lake Storageディレクトリ内の一連のファイルを読み込むこともできます。このドキュメントでは、以下の方法について説明します。
Azure Data Lake Storage Gen2アカウントの接続
Azure Data Lake Storageコネクタを使用する前に、リモート接続をサポートするようにAzure環境を設定し、RapidMinerで新しいAzure Data Lake Storage Gen2接続を設定する必要があります。
そのためには、次の主なステップを実行する必要があります(以下の詳細を参照ください)。
- AzureポータルでWebアプリケーションの登録
- リモート接続の情報を取得
- RapidMinerで新しいAzure Data Lake Storage Gen2接続を設定およびテスト
ステップ1: AzureポータルでWebアプリケーションの登録
Azureへの認証は、Webアプリケーションの登録(Active Directory Service Principal)を使用するのがデフォルトかつ推奨の方法です。また、共有キーを使用することも可能です。後者の場合は、このステップを省略できます。
Azure Active Directoryを使用してAzure Data Lake Storage Gen2でのサービス間認証を許可するために、Azure AD Webアプリケーションを作成して設定します。サービス間認証ガイドのステップ1からステップ2まで進めます。最初のステップでは、RapidMinerからAzure Data Lake Storageへのアクセスを提供するWebアプリケーションを登録します。NameとSign-on URLフィールドには任意の値を使用できることに注意してください。2つ目のステップでは、Tenant ID、登録したアプリケーションのアプリケーションID、および RapidMinerがこのアプリケーションを使用できるようにRapidMinerで提供する必要があるキーを取得する方法を説明します。また、新しく登録されたアプリケーションには、そのリソースに対して必要な権限を付与する必要があります。Azure Web Portal、Azure CLI、または Azure Storage Explorerデスクトップアプリケーションなど、いくつかのツールを使用してリソースへのアクセスを制御できます。
Azure Tenantでこれらのステップを実行した後、ターゲットのAzure Data Lake Storage Gen2リソースの一部またはすべてのフォルダにアクセスするように設定されたWebアプリケーションの登録が必要です。RapidMinerのオペレータのファイルブラウザ(下記参照)が機能するためには、コンテナとナビゲーションを許可するすべてのディレクトリに読み取りと実行のアクセス権が必要なことに注意してください。さらに、RapidMinerからクラウドストレージへの書き込みができるようにするには、書き込み権限が必要です。ファイルブラウザなしで作業できる場合は、オペレータが直接使用する対象フォルダ/ファイルへのアクセス許可を制限することができます。
ステップ2: リモート接続の情報を取得
Active Directory Service Principal(推奨)または共有キーを使用してリソースにアクセスすることができます。RapidMinerで接続を作成するには、次の情報を取得する必要があります。
Active Directory Service Principalの場合
- アカウント名
- 作成したWebアプリケーションのアプリケーションIDとアプリケーションキー
- 自社のアカウントを識別するテナントID
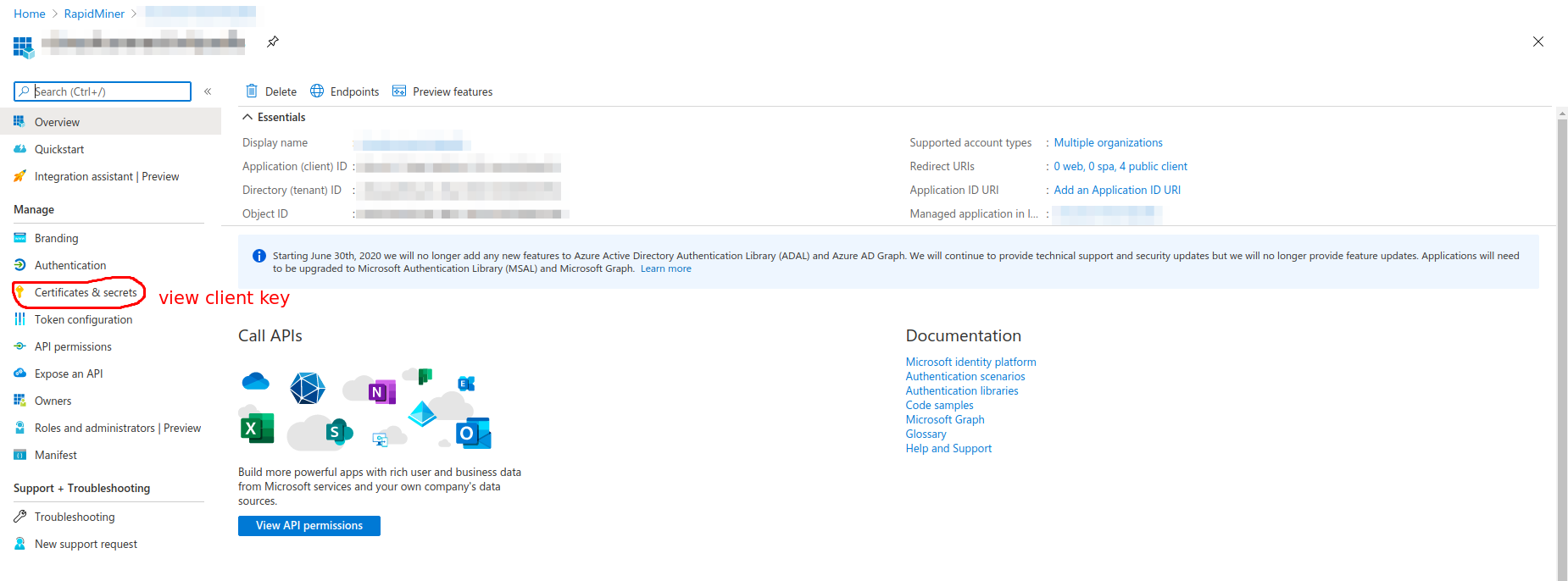
共有キーの場合
- アカウント名
- アカウントのキー
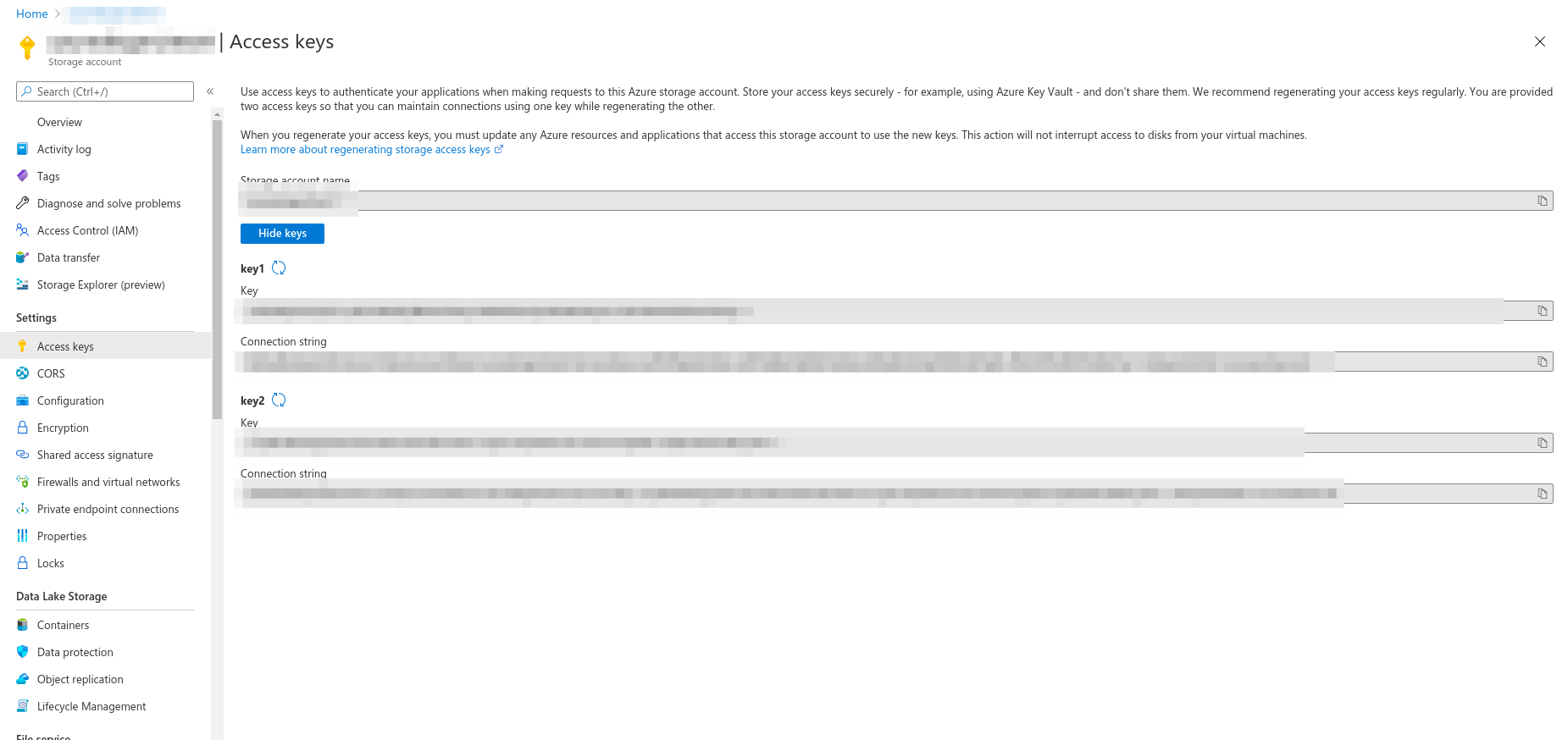
ステップ3: RapidMinerで新しいAzure Data Lake Storage Gen2接続を設定およびテスト
すべての情報が揃ったら、RapidMinerで接続を設定するのは簡単です。
- RapidMiner StudioでAzure Data Lake Storage Gen2接続を保存するリポジトリを右クリックして、
 を選択します。
を選択します。
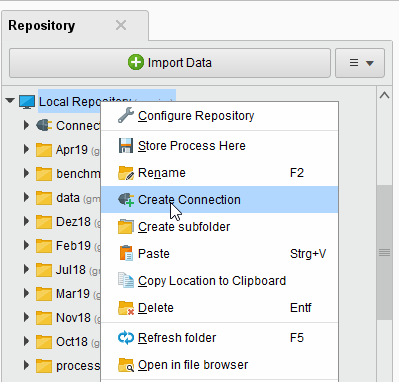
または、Connections > ![]() Create Connectionをクリックし、以下のダイアログのドロップダウンからリポジトリを選択することも可能です。
Create Connectionをクリックし、以下のダイアログのドロップダウンからリポジトリを選択することも可能です。
- 新しい接続の名前を入力し、Connection Typeを
 に設定します。
に設定します。
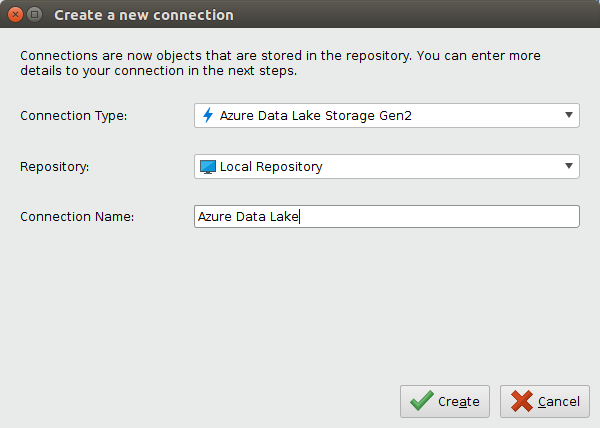
 Createをクリックし、Edit connectionダイアログのSetupタブに切り替えます。
Createをクリックし、Edit connectionダイアログのSetupタブに切り替えます。- Azure Data Lake Storage Gen2アカウントの接続詳細を入力します。Active Directory Service Principal(推奨)、または共有キーのいずれかを選択します。前者はアカウント名、クライアントID(WebアプリケーションのID)、クライアントキー(Webアプリケーションにアクセスするためのパスワード)、テナントIDを、後者はアカウント名とアカウントキーを入力します。
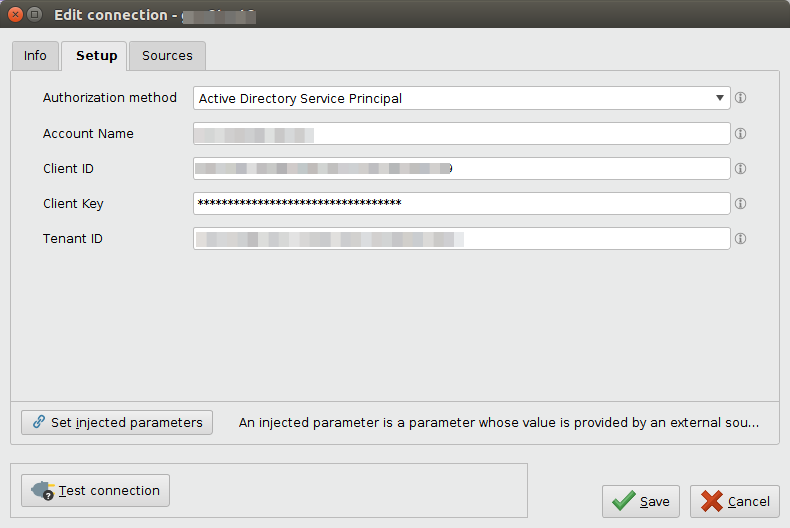
- 必須ではありませんが、
 Test connectionボタンをクリックして、新しいAzure Data Lake Storage Gen2接続をテストすることを推奨します。テストに失敗した場合は、接続詳細が正しいかどうかを確認してください。
Test connectionボタンをクリックして、新しいAzure Data Lake Storage Gen2接続をテストすることを推奨します。テストに失敗した場合は、接続詳細が正しいかどうかを確認してください。  Saveをクリックして接続を保存し、Edit connectionダイアログを閉じます。これで、Azure Data Lake Storageオペレータを使用することができます!
Saveをクリックして接続を保存し、Edit connectionダイアログを閉じます。これで、Azure Data Lake Storageオペレータを使用することができます!
Azure Data Lake Storageからの読み込み
![]() Read Azure Data Lake Storage Gen2オペレータはAzure Data Lake Storage Gen2アカウントからデータを読み込みます。このオペレータはファイルをダウンロードするのみでファイルを処理できないので、任意のファイル形式をロードするのに使用されます。ファイルを処理するためには、Read CSV、Read Excel、Read XMLなどの追加のオペレータを使用する必要があります。
Read Azure Data Lake Storage Gen2オペレータはAzure Data Lake Storage Gen2アカウントからデータを読み込みます。このオペレータはファイルをダウンロードするのみでファイルを処理できないので、任意のファイル形式をロードするのに使用されます。ファイルを処理するためには、Read CSV、Read Excel、Read XMLなどの追加のオペレータを使用する必要があります。
まずは、Azure Data Lake Storageから簡単なcsvファイルを読み込むことから始めてみましょう。
 Read Azure Data Lake Storage Gen2オペレータをプロセスパネルにドラッグします。connection entryパラメータの横にある
Read Azure Data Lake Storage Gen2オペレータをプロセスパネルにドラッグします。connection entryパラメータの横にある  ボタンをクリックして、保存先のリポジトリのConnectionsフォルダからAzure Data Lake Storage Gen2接続を選択します。
ボタンをクリックして、保存先のリポジトリのConnectionsフォルダからAzure Data Lake Storage Gen2接続を選択します。
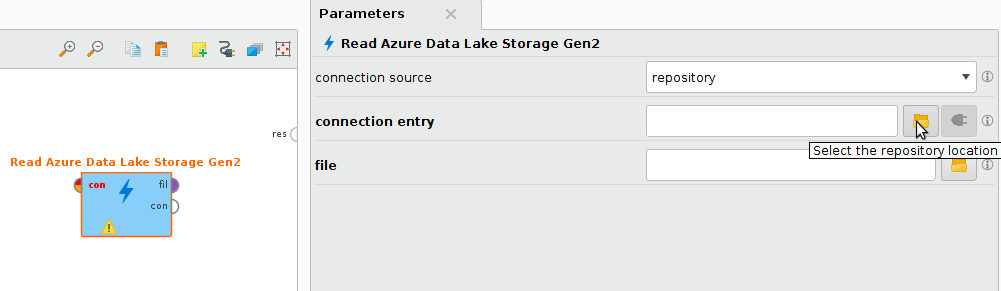
または、リポジトリから Azure Data Lake Storage Gen2接続をプロセスパネルにドラッグして、オペレータの出力を ![]() Read Azure Data Lake Storage Gen2オペレータに接続することもできます。
Read Azure Data Lake Storage Gen2オペレータに接続することもできます。
 ファイル選択ボタンをクリックして、Azure Data Lake Storage Gen2アカウント内のファイルを確認します。ロードするファイルを選択し、
ファイル選択ボタンをクリックして、Azure Data Lake Storage Gen2アカウント内のファイルを確認します。ロードするファイルを選択し、  開くをクリックします。ルートフォルダから始まるファイルブラウザを使用するには、ルートディレクトリへのReadおよびExecuteのアクセス権が必要なことに注意してください。その権限を持っていない場合は、パラメータフィールドにパスを入力します。そのパスの親フォルダ(ファイルまたはディレクトリ)へのアクセス権と、コンテナレベルでの実行アクセス権があれば、ファイルブラウザを開くことができます。または、常に手動で入力したパスを使用し、それを使ってオペレータを使用することもできます(その場合、権限は実行時にのみチェックされます)。
開くをクリックします。ルートフォルダから始まるファイルブラウザを使用するには、ルートディレクトリへのReadおよびExecuteのアクセス権が必要なことに注意してください。その権限を持っていない場合は、パラメータフィールドにパスを入力します。そのパスの親フォルダ(ファイルまたはディレクトリ)へのアクセス権と、コンテナレベルでの実行アクセス権があれば、ファイルブラウザを開くことができます。または、常に手動で入力したパスを使用し、それを使ってオペレータを使用することもできます(その場合、権限は実行時にのみチェックされます)。
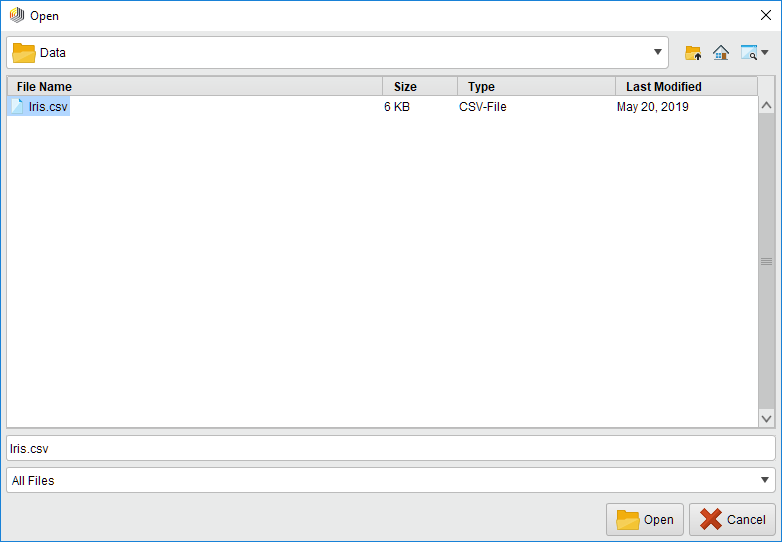
前述のように、![]() Read Azure Data Lake Storage Gen2オペレータは指定したファイルの内容を処理しません。この例では、csvファイル(カンマ区切り値ファイル)を選択しています。このファイルタイプはRead CSVオペレータで処理することができます。
Read Azure Data Lake Storage Gen2オペレータは指定したファイルの内容を処理しません。この例では、csvファイル(カンマ区切り値ファイル)を選択しています。このファイルタイプはRead CSVオペレータで処理することができます。
- その後、
 Read Azure Data Lake Storage Gen2オペレータと結果ポートの間にRead CSVオペレータを追加します。csvファイルの形式に応じて、列の区切り文字などのRead CSVオペレータのパラメータを設定することができます。
Read Azure Data Lake Storage Gen2オペレータと結果ポートの間にRead CSVオペレータを追加します。csvファイルの形式に応じて、列の区切り文字などのRead CSVオペレータのパラメータを設定することができます。
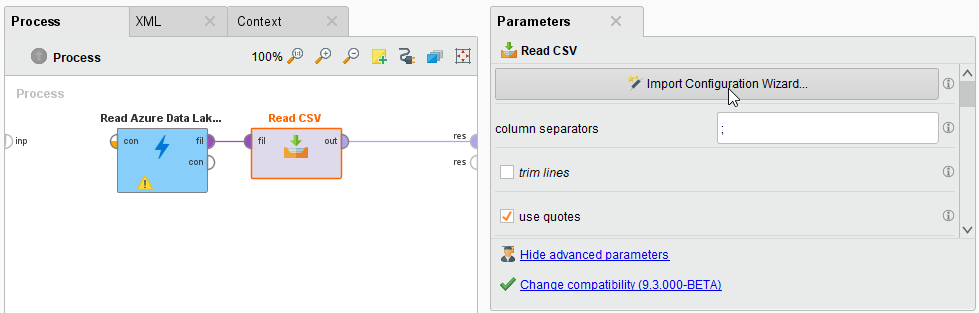
 をクリックしてプロセスを実行します。結果画面には、選択したcsvファイルの行と列を含むテーブルが表示されます。
をクリックしてプロセスを実行します。結果画面には、選択したcsvファイルの行と列を含むテーブルが表示されます。
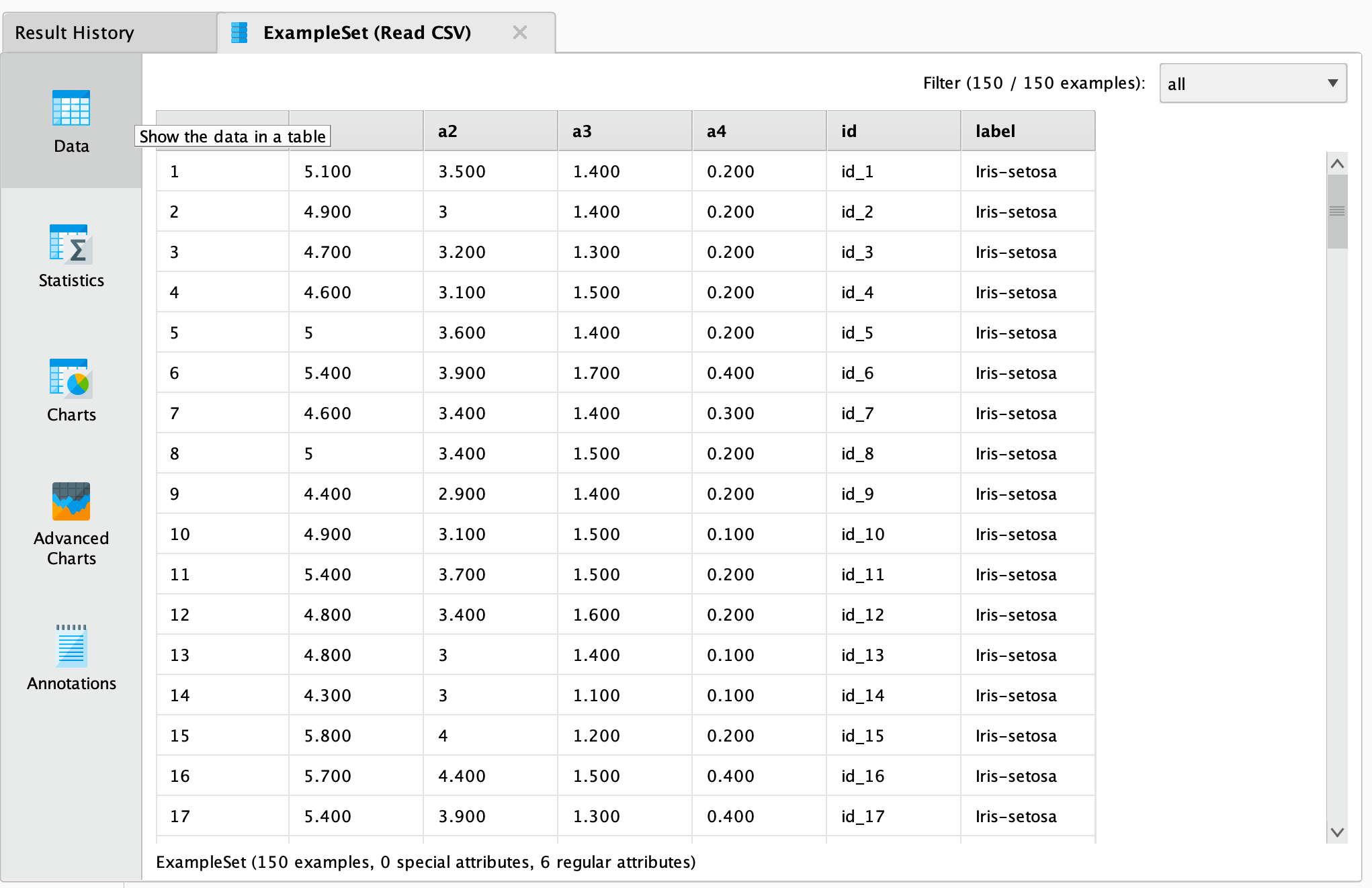
これで、さらにオペレータを使用し、特定のイベントの共通性を判断するなど、このドキュメントを操作できるようになりました。結果をAzure Data Lake Storageに書き戻すには、 ![]() Write Azure Data Lake Storage Gen2オペレータを使用できます。このオペレータは
Write Azure Data Lake Storage Gen2オペレータを使用できます。このオペレータは ![]() Read Azure Data Lake Storage Gen2オペレータと同じ接続タイプを使用し、同様のインタフェースを備えています。また、
Read Azure Data Lake Storage Gen2オペレータと同じ接続タイプを使用し、同様のインタフェースを備えています。また、 ![]() Loop Azure Data Lake Storage Gen2オペレータを使用して、Azure Data Lake Storageディレクトリ内の一連のファイルを読み込むこともできます。これを行うには、connection entryと処理するフォルダ、および入れ子内にオペレータを追加して、ループ処理のステップを設定する必要があります。詳細については、
Loop Azure Data Lake Storage Gen2オペレータを使用して、Azure Data Lake Storageディレクトリ内の一連のファイルを読み込むこともできます。これを行うには、connection entryと処理するフォルダ、および入れ子内にオペレータを追加して、ループ処理のステップを設定する必要があります。詳細については、 ![]() Loop Azure Data Lake Storage Gen2オペレータのヘルプをご覧ください。
Loop Azure Data Lake Storage Gen2オペレータのヘルプをご覧ください。
