Streamingエクステンションの使用
Streamingエクステンションは、ストリーミング分析プロセスを構築し、Apache Flink またはApache Sparkストリーミングクラスタにデプロイすることができます。プロセスの設計は、Streaming Nestと呼ばれる特別なネスト構造をもつオペレータ内部で、既知のオペレータを基に行います。
データフローは、ストリーミング処理のデータソースとシンクにApache Kafkaのtopicを使用して動作します。Kafkaの接続を作成する方法については、Kafka Connectorエクステンションのページを参照してください。
Streamingエクステンションのインストール
エクステンションをインストールするには、拡張機能メニューに移動し、 ![]() マーケットプレイス(更新と拡張機能)を開いて、Streamingエクステンションを検索します。詳細については「エクステンションの追加」を参照してください。
マーケットプレイス(更新と拡張機能)を開いて、Streamingエクステンションを検索します。詳細については「エクステンションの追加」を参照してください。
ストリーミングクラスタへの接続
このエクステンションは、プロセスをデプロイできるストリーミングクラスタへの接続を必要とします。この接続には、RapidMinerの接続フレームワークを使用します。これにより、接続を一元管理し、オペレータ間の接続を再利用することができます。このプロセスは技術的に独立しているので、FlinkでもSparkクラスタでも、接続オブジェクト以外は変更することなく同じプロセスを実行することができます。
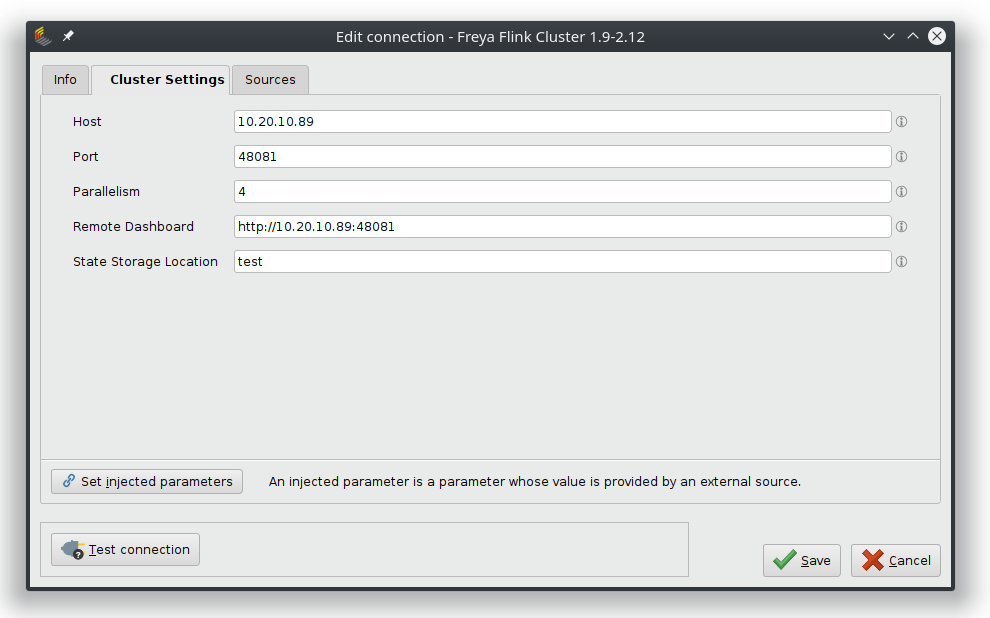
Flinkへの接続
リポジトリ内に動作するFlink接続オブジェクトを作成するには、必要なプロパティを追加する必要があります。それは、ホストやポート情報、適用される並列レベル、リモートダッシュボードのアドレスなどです。
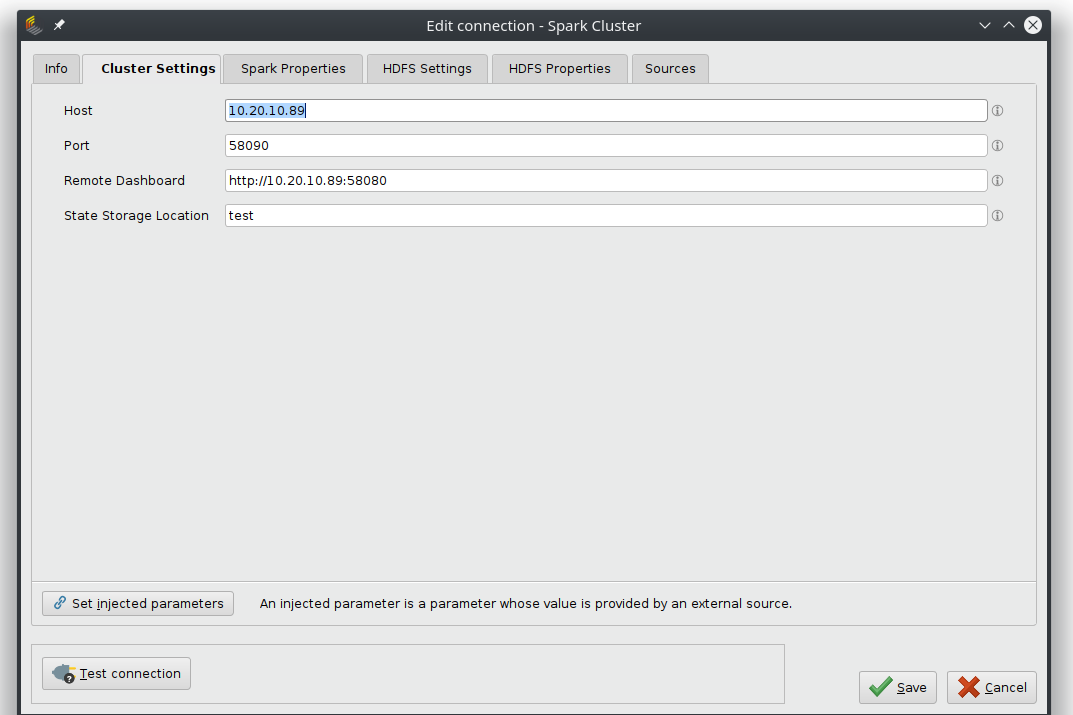
Sparkへの接続
動作するSpark接続オブジェクトを作成するには、必要なプロパティを追加する必要があります。Spark Settingsタブでは基本的な接続を扱い、ホストのアドレスやポート番号、リモートダッシュボードへのリンクが必要です。
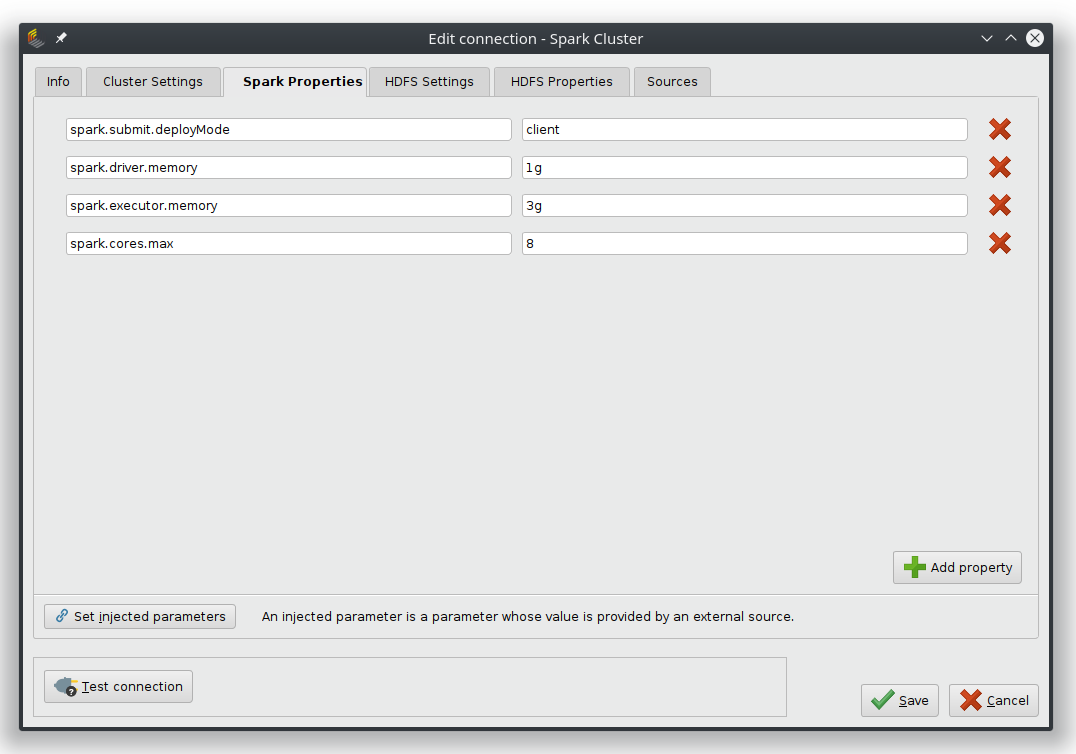
Spark PropertiesタブとHDFSタブでは、クラスタのプロパティを保持することができ、これらは使用するsparkのバージョンとサーバー設定に依存します。
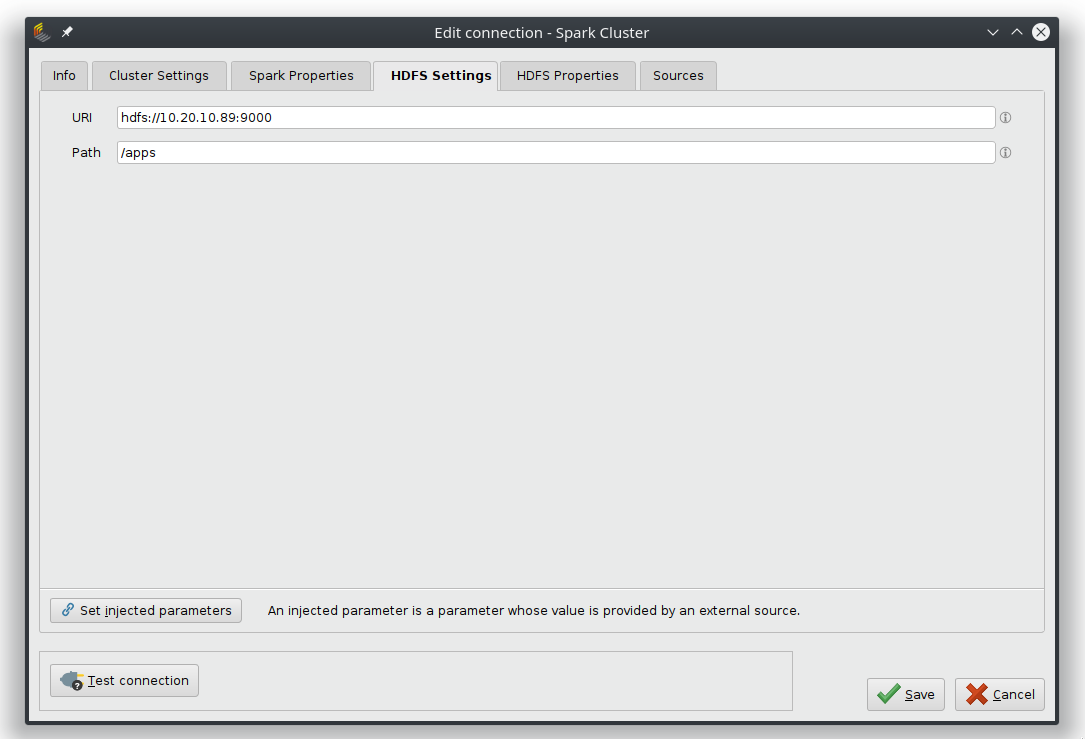
HDFS Settingsタブでは、オプションでHDFSファイルシステムへのURLとパスを設定できます。
ストリーミングプロセスの構築
ストリーミング処理の起点となるのは、Streaming Nestオペレータです。このプロセスの中で、ストリーミング処理が設定され、その内容が、接続入力ポートで定義されたストリーミングクラスタへデプロイされます。
ストリーミングのネスト内部では、StreamingエクステンションのオペレータのみがFlinkやSparkの操作に変換され、ストリーミングサーバーにデプロイされます。Multiplyなどの他のオペレータは、ワークフローを整理するのに役立ちます。Kafka接続オブジェクトは、入出力にデータストリームを使用し、RapidMinerのモデルはApply Model on Streams(後述)と組み合わせて使用することが可能です。
ETLプロセスの構築
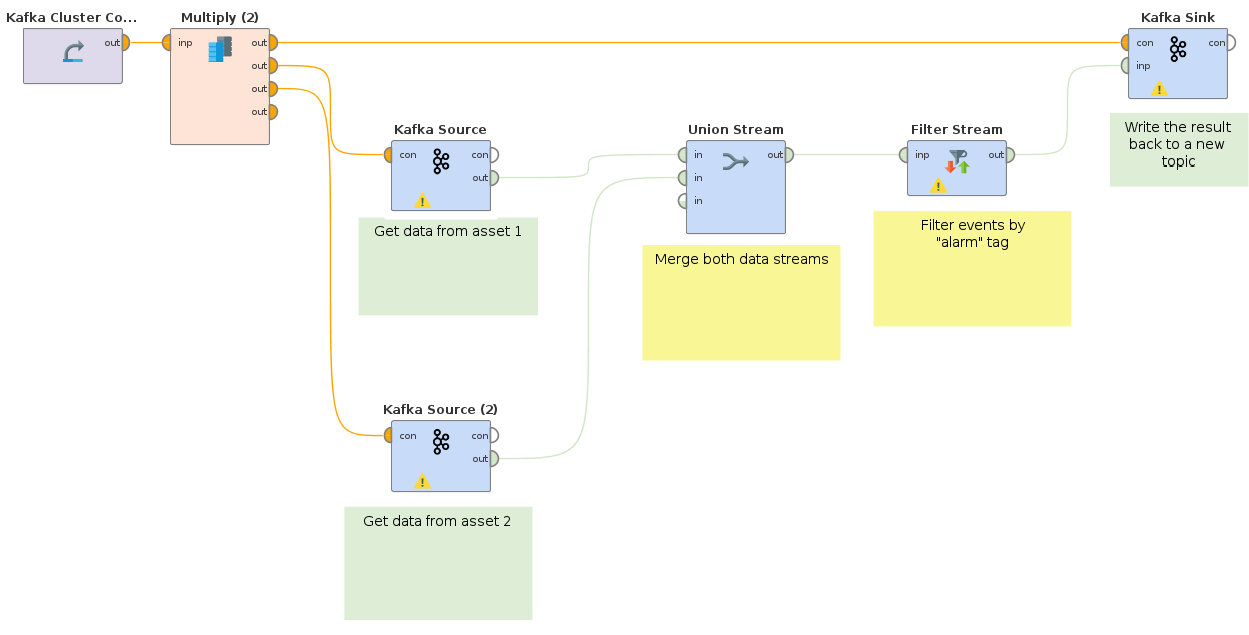
このプロセスは、2つの別々のKafkaトピックから入力される2つのデータストリームを結合し、データ内の特定のキーに対してフィルターをかけます。結果は新しいKafkaトピックに書き戻され、モデルの学習などに利用されます。
使用例
- 入力される2つのKafkaストリームは、2つの別々の生産工場の監視サービスからのイベントです。数百万件の入力イベントのうち、早期警告システムにとって重要なものは、「warning」とタグ付けされたもののみです。
- ストリームは、2つのWebショップサイトからのクリックイベントとなることもあります。その場合は例えば、リテンションイベントをトリガーするために、キーとなる「キャンセル」と付いたイベントのみを分析すべきです。
以下のプロセスは、異なるアセットからの2つのデータストリームが、まずUnionオペレータによって結合される様子を示しています。そして得られたストリームは、次に「warning」タグを持つイベントのみを含むようにフィルタリングされます。こうしてフィルタリングされた結果は、新しいKafkaトピックに書き戻されます。
ストリームへのモデルの適用
上記の例を基に、2つ目の例では、ストリーミングクラスタ上で任意のRapidMinerモデルを訓練し適用する方法を紹介します。
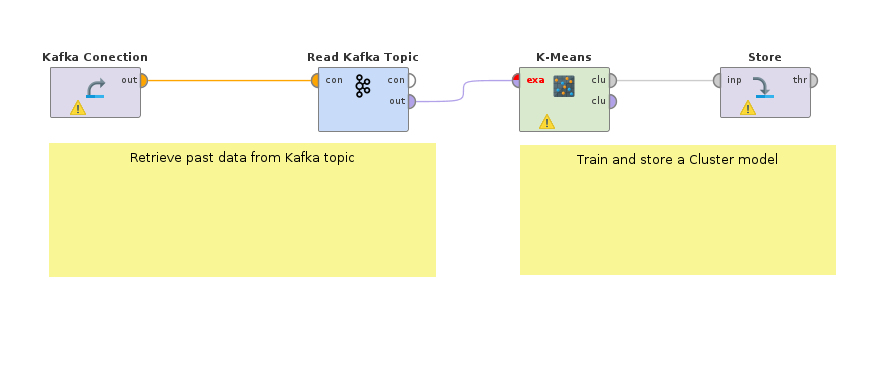
まず最初のステップでは、データを取得し、過去のデータでモデルを学習させます。例えば、Kafka ConnectorエクステンションのRead Kafkaオペレータを使用すると、工場のモニタリングデータから「warning」タグの付いた過去のイベントを取得できます。k-Meansクラスタリングモデルは、アラームのサブグループを検出し、異なるタイプの問題を自動的に区別するのに役立ちます。ラベル付けされたデータを利用できる場合は、教師あり学習モデルでも学習できます。例えば、アラームの重大度レベルを予測するモデルなどです。
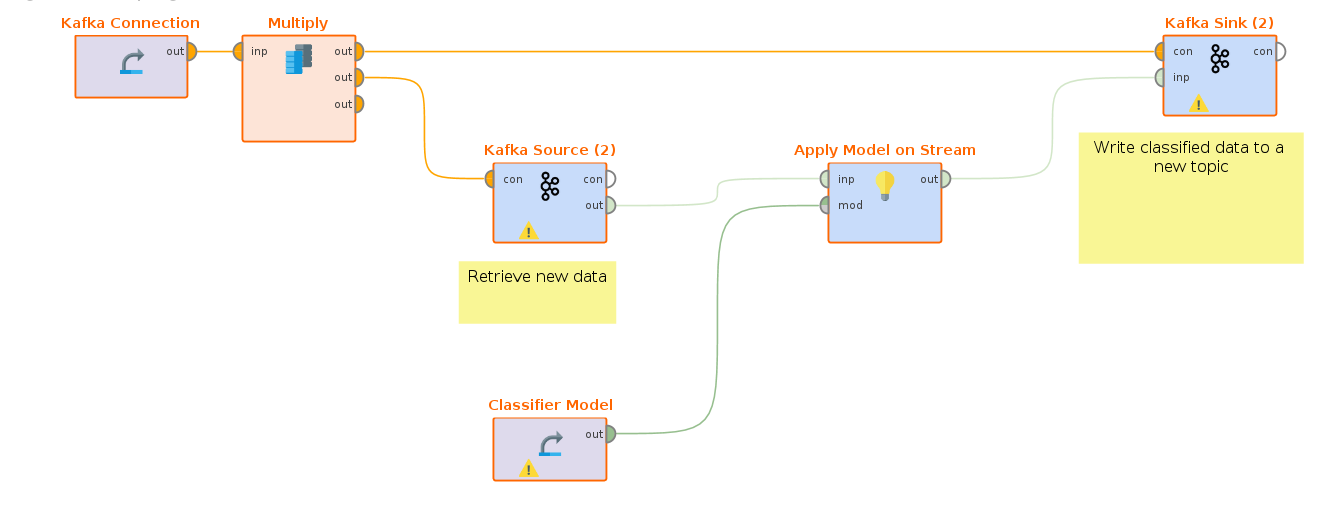
こうして、学習されたモデルがStreamingワークフロー内に配置されます。このモデルは、フィルタリングされたアラームイベントのストリームに適用され、予測の付いた結果がさらに別のトピックにプッシュされます。
プロセスの監視
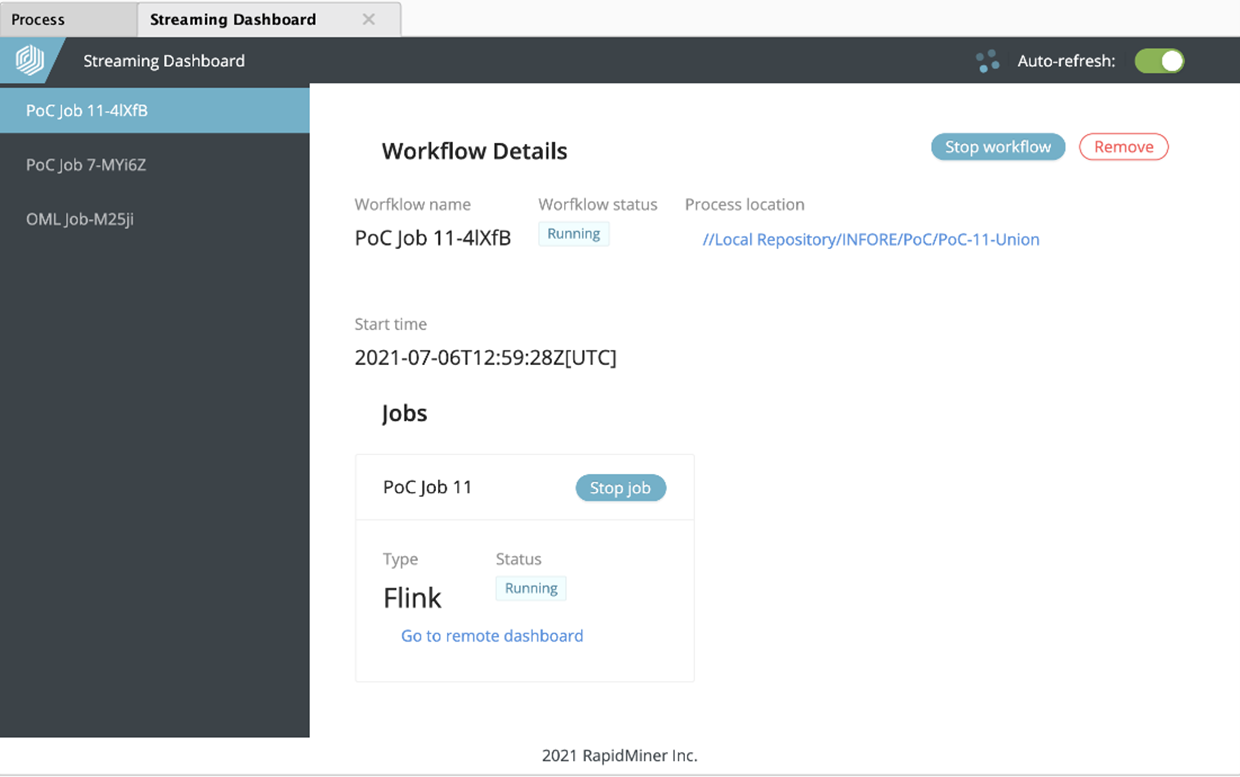
Streamingエクステンションは、RapidMiner Studioに新しいパネル、「Streaming Dashboard」を追加します。ユーザーインタフェースの「ビュー」->「パネルの表示」->「Streaming Dashboard」で追加することができます。
デプロイされているすべてのストリーミングプロセスを一覧表示し、監視・管理することができます。Streamingのネスト構造をもつオペレータの実行により、Streaming Dashboardにエントリ(ワークフロー)が作成されます。ワークフロー名、ステータス、RapidMinerプロセスの定義場所、開始時刻がダッシュボードに表示されます。
また、デプロイされているすべてのストリーミングジョブも表示されます。個々のジョブだけでなく、ワークフロー全体の停止もダッシュボードから行うことができます。ワークフローのエントリは、ボタンでダッシュボードから削除することができます。
またStreaming Dashboardでは、プラットフォーム固有の(FlinkまたはSpark)リモートダッシュボードを開くこともできます。
ストリームへのRapidMinerモデルの適用
Apply Model on Streamオペレータを使用するには、ストリーミングクラスタにいくつかの変更が必要です。ストリーミングエンジン(FlinkまたはSpark)は、RapidMinerのモデルの扱い方を知るために追加のプラグインが必要です。もちろん、実際にモデルを実行するには、RapidMinerの実行エンジンも必要です。
クラスタ上でRapidMiner Studioのインストール
RapidMiner Studioのインストールガイドはこちらです。特殊なモデル(例えばDeep Learningエクステンション)を使用する場合は、エクステンションの*.jarファイルも必要となり、クラスタ内の.RapidMiner/extensionsフォルダに配置する必要があります。エクステンションのファイルはRapidMinerマーケットプレイスからダウンロードするか、ローカルインストールの.RapidMinerからコピーすることができます。
RapidMinerプラグインのインストール
RapidMinerプラグインファイルはエクステンションとともに配布されます。Streamingエクステンションをマーケットプレイスからインストールした後、RapidMinerホームフォルダのパス.RapidMiner/extensions/workspace/rmx_streamingで確認できます。
このフォルダの中には、rapidminer-as-plugin-common.jarとrapidminer-as-plugin.jarという二つのファイルがあり、末尾にはエクステンションのバージョン番号が付きます。
rapidminer-as-plugin-common.jarファイルをクラスタインストールの/libフォルダに配置します(例: /opt/flink/lib/)。
rapidminer-as-plugin-common.jarの準備には、もう少し手順が必要です。- 空のlibフォルダを作成します。- このフォルダに、新しくRapidMinerをインストールした時のlibフォルダの内容をコピーします(jdbcとpluginsのサブフォルダは除きます)。- rapidminer-as-plugin.jarもこのフォルダにコピーします。- plugin.propertiesファイルを作成し、以下のように記述します。
plugin.class=com.rapidminer.extension.streaming.raap.wrapper.RapidMinerPlugIn
plugin.id=rm-as-plugin
plugin.version=9.9.0
plugin.description=RapidMiner as Plugin
plugin.license=Apache Licents 2.0
libフォルダと内部にplugin.propertiesを含むzipアーカイブを作成し、rm-as-plugin.zipという名前を付けます(コードがこのファイルを探すので、名前が合っているか確認してください)。
このzipファイルを、RapidMinerのインストール先の新しいフォルダ %RM_INSTALLATION%/lib/rm-as-pluginに配置します(つまり、*.jarファイルがコピーされた場所のサブフォルダです)。
その後、FlinkやSparkが新しいプラグインを読み込めるように、クラスタインスタンスを再起動します。
これで、Apply Model on Streamオペレータが使えるようになりました。必要なパラメータは二つで、(rm-as-pluginがインストールされていた)RapidMinerのインストールフォルダの場所と、(エクステンションやユーザーデータが保存されている)RapidMinerのホームフォルダの場所です。
典型的なLinuxクラスタでは、パスは/opt/rapidminer-9-9-0と/home/$UserName/.RapidMinerのようなものになります。
