デプロイメント
イントロダクション
モデルオペレーションに関する イントロダクション / デプロイメント / マネジメントの紹介ビデオもご覧ください。
モデルの全ての価値を理解するには、運用を開始する必要があります。RapidMiner Studioのガイド付きのアプローチでは、以下があります。
オートモデル内から、一回のクリックでモデルをデプロイすることができます!
デプロイメントは同じ入力データを説明するモデルの集合です。最もシンプルな形では、デプロイメントはリポジトリ内に存在し、データにスコアをつけます(例えば、予測を行います)が、デプロイメントはこれ以上のことが可能です!
- デプロイメントはモデルを整理し、重要なデータを一つの場所に保管します(例えば、 GDPRなどの規則を遵守するため)。
- デプロイメントはモデルのパフォーマンスを経時的に追跡し、ドリフトやバイアスを警告します。
- デプロイメントは共通のプロジェクトで協力しているグループで共有することが可能です。
- デプロイメントはwebサービスを提供しているため、他のソフトウェアと統合することが可能です。
デプロイメントロケーションは複数のデプロイメントのコンテナです。
- 複数のデプロイメントを共通のデプロイメントロケーションで保管可能です。
- 別々に動いているチームで別のデプロイメントロケーションを持つことも可能です。
基本的な考え方は、運用するモデルが多いほど良くなるというものです。したがって、デプロイはできるだけ簡単に行える必要があります。モデルを無駄にするのをやめませんか?
目次に飛びます
デプロイメントの計画
デプロイメントロケーションはローカルもしくはリモートで、空のフォルダから開始します。 このフォルダを作成したら、デプロイメントを壊さないように、これに触れないのがベストです。
| デプロイメントロケーション | フォルダロケーション |
|---|---|
| Local | RapidMiner Studio リポジトリ |
| Remote | RapidMiner AI Hub リポジトリ |
RapidMiner AI Hub上に保存したデプロイメントロケーションは共有することができ、 ユーザーとグループを適切に設定することでアクセスを制御することができます。
デプロイメントの計画時に注意していなければ、重要な コンポーネントが不足していることが後からわかるかもしれません。以下に注意してください。
- モニタリング は長期間のスコアリングの統計量の収集に役立ちます。モニタリングを有効にするには、 データベースと接続する必要があります。
- リモートデプロイメント はデプロイメントを共有でき、他のソフトウェアと統合できます。
適切な デプロイメントロケーションを作成できているか確認しましょう。
デプロイメントのコンポーネント
デプロイメントロケーション内に、 デプロイメントを作成します。デプロイメントは、デプロイメントロケーションの位置によって、以下のコンポーネントのサブセットを提供します。
モニタリングありの リモートデプロイメントを作成すると、全てのコンポーネントが利用可能です。
| コンポーネント | 概要 |
|---|---|
| ダッシュボード | 経時的に計測された、スコアリングの統計量を表示します。 |
| モデル | 同じか、少なくとも似たデータセット(同じ列、同じデータ型を持つ)で構築された、競合モデルのリストです。一つのモデルはアクティブで、残りはチャレンジャーです。 GDPRのような規則を遵守するため、モデルの構築に使用されたオリジナルの入力データセットやプロセスを含む、各モデルへの全ての詳細が含まれます。 |
| パフォーマンス | 経時的に計測された、モデル毎のスコアリングの統計量の詳細を表示します。 |
| ドリフト | 入力データの分布とスコアリングデータの分布の差です。この差は、入力データが実態を代表するものではなかったためにバイアスがかかっているか、もしくはスコアリングデータがドリフトしてしまったために生じます。計測されたドリフトが大きい場合は、モデルの再構築も必要かもしれません。 |
| シミュレータ | オートモデルでご存知のように、モデルシミュレータです。 |
| スコアリング | スコアを付け、その結果を確認したいデータのアップロードを行うインタフェースです。 |
| アラート | デプロイメントで異常な挙動や、望ましくない動きがあった場合、アラートで警告します。 |
| インテグレーション | webサービスを利用することで、デプロイメントの共有や他のソフトウェアとの統合が可能になります。 |
デフォルトでは、どのデプロイメントロケーションもモデル、シミュレータ、スコアリングを含んでいます。下のテーブルは、以下の場合に利用可能になる追加コンポーネントを表しています。
- モニタリングを有効にしたとき
- リモートデプロイメント ロケーションを作成したとき
| RapidMiner Studio | + データベース接続 | |
|---|---|---|
| RapidMiner Studio |
|
|
| + RapidMiner AI Hub |
|
|
デプロイメントロケーションの作成
リモートデプロイメント ロケーションを作成するには、 RapidMiner AI Hub リポジトリに接続する必要があります。
以下のスクリーンショットは モニタリングありの リモートデプロイメント ロケーションの作成を説明したものです。ローカルデプロイメントロケーションの作成ステップはほとんど同じです。状況が異なる場合は、コメントを残しています。
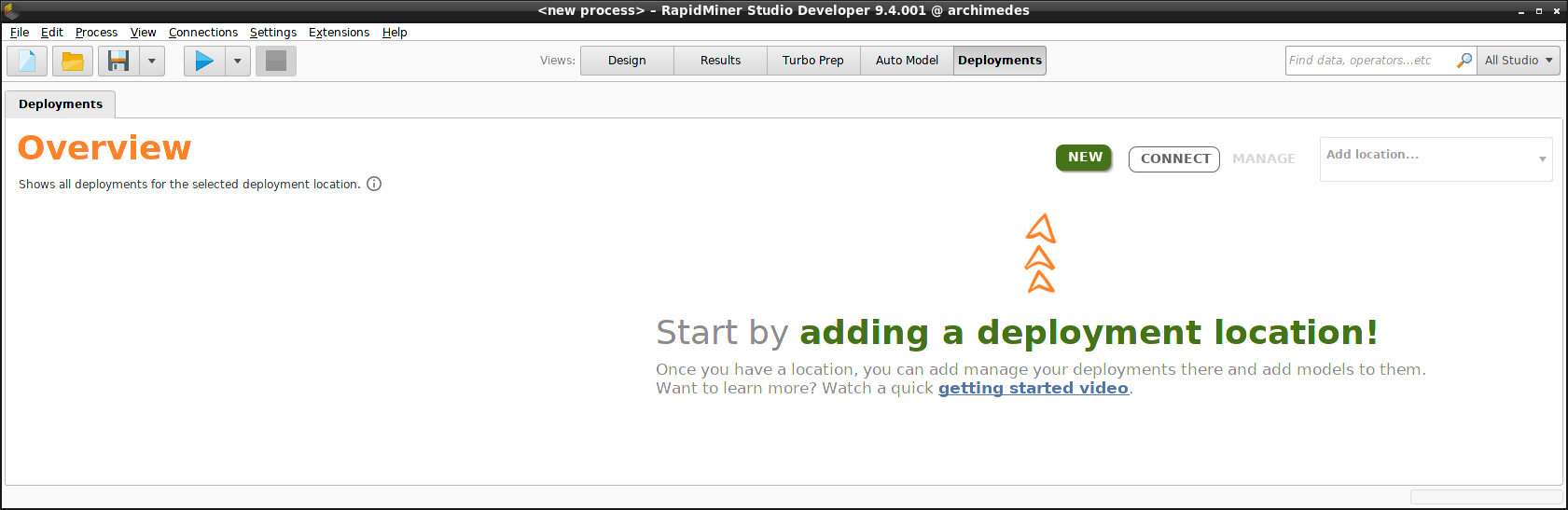
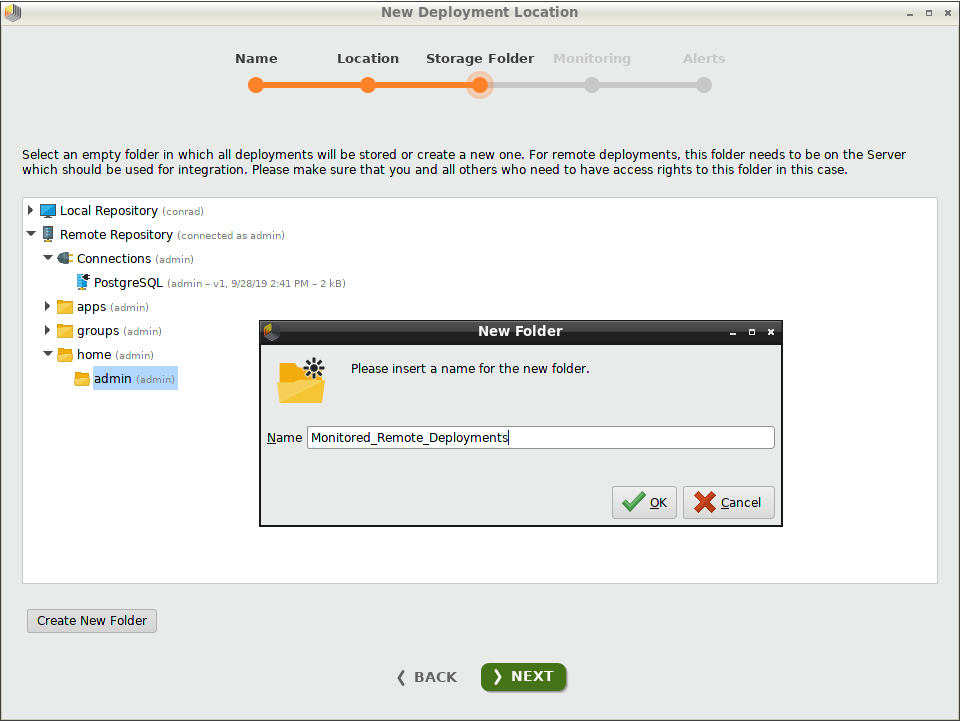
Deployments のOverview内から、 New をクリックし、ダイアログに名前を入力してデプロイメントロケーションを追加します。今回の例では、”Monitored_Remote_Deployments”と入力し、 Nextをクリックします。
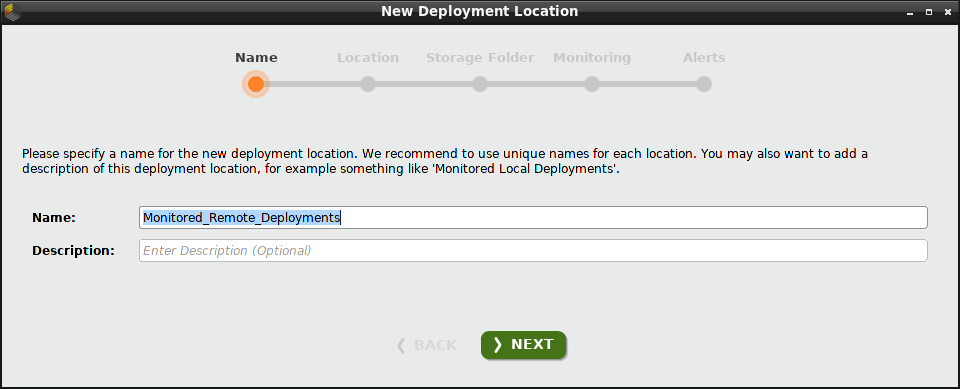
Remote デプロイメントロケーションの作成を選択します。このロケーションでのデプロイメントは アラート や インテグレーションを含みます。反対に、 Local デプロイメントロケーションはこれらのコンポーネントを含みません。
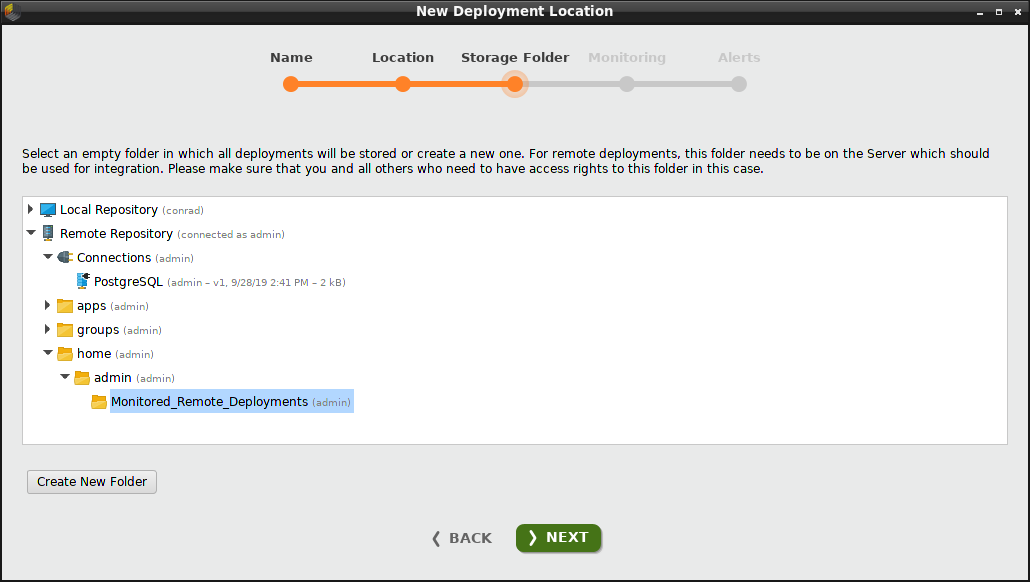
リポジトリ内に空のフォルダをまだ作成していない場合は、 Create New Folderをクリックして作成できます。今回の例では、”Remote Repository”内の /home/adminの下に”Monitored_Remote_Deployments”というフォルダを作成し選択します。フォルダが空である限り、どこにでもフォルダを作成できます。
モニタリングを有効にする際に必要なため、このリポジトリは”PostgreSQL”接続を含んでいることに注意してください。
モニタリングを有効にするには、 データベース接続が必要です。
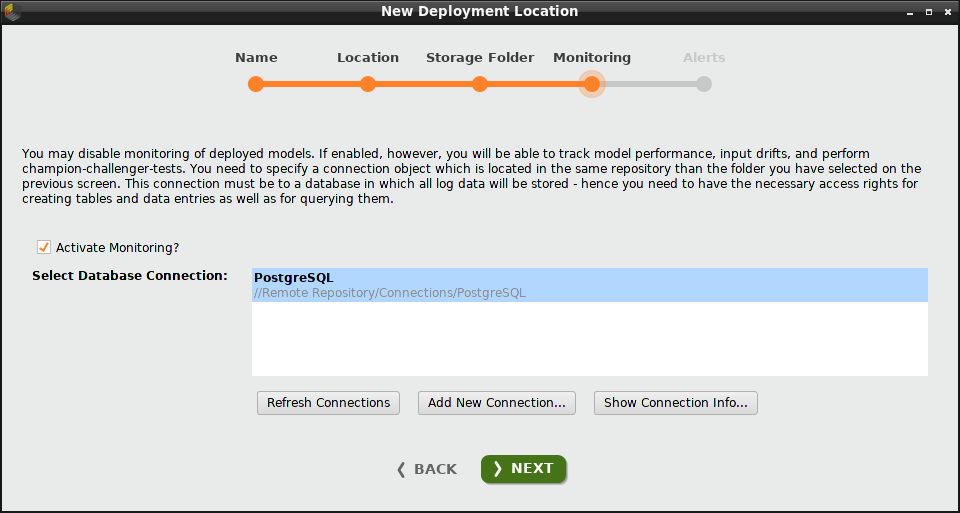
モニタリングを有効にするには、チェックボックスをクリックし、データベース接続を選択します。 接続を作成する必要がある場合は、 Add New Connection をクリックします。今回の例では、既にある”PostgreSQL”接続を選択します。
モニタリングのおかげで、このロケーションにあるすべてのデプロイメントは ダッシュボード や パフォーマンスのサマリー、 ドリフトを含みます。モニタリングがなければ、これらのコンポーネントは含まれません。
アラートを作成するには、 リモートデプロイメント ロケーションが必要で、 モニタリングを有効にする必要があります。
メールアラートを有効にするには、チェックボックスをクリックし、メール送信接続を選択します。 接続を作成する必要がある場合は、 Add New Connection をクリックします。今回の例では、”Email_Alert”という メール接続 を作成し選択します。
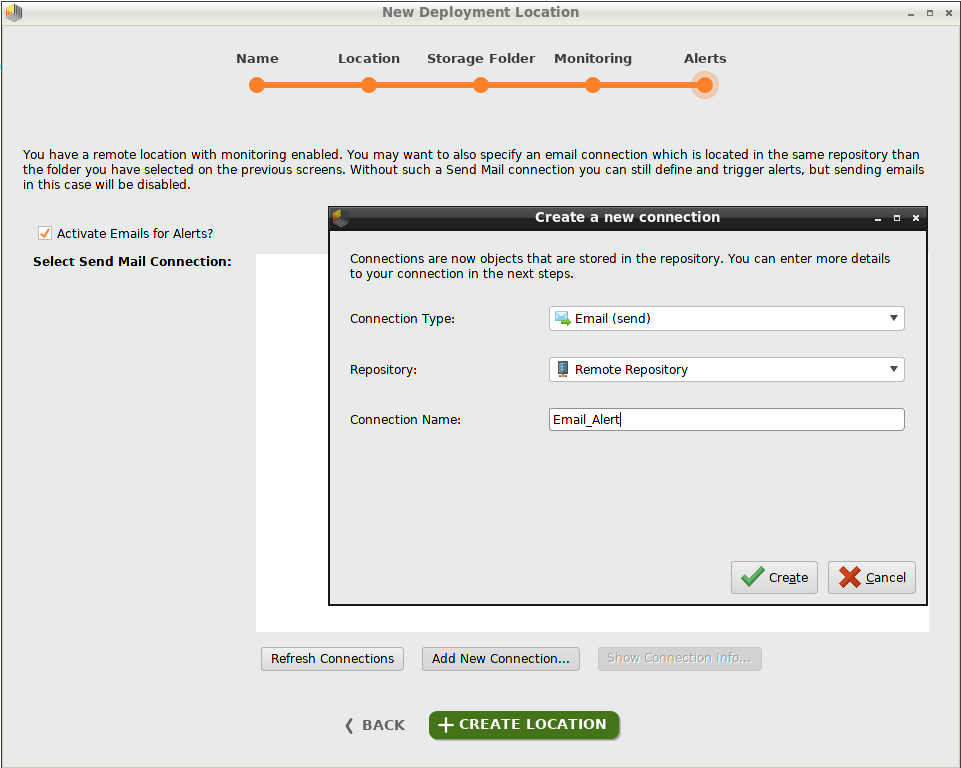
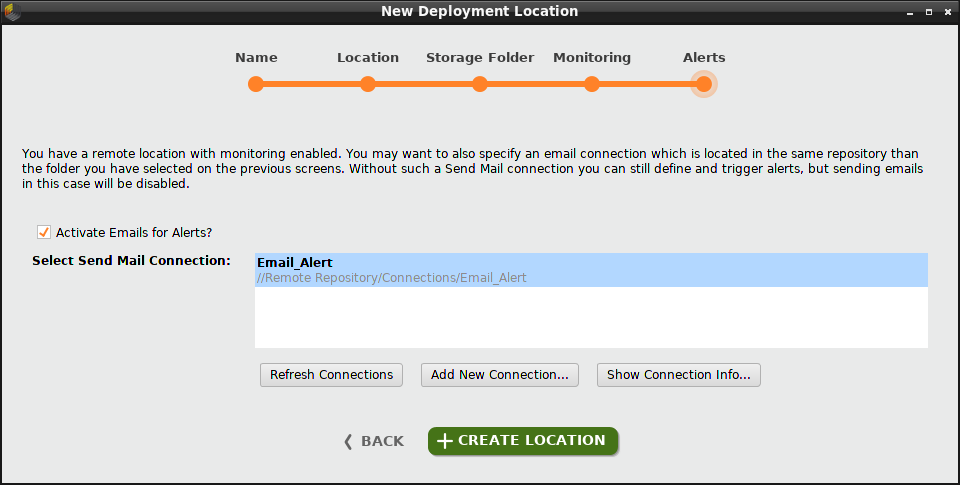
Create Locationをクリックすると、デプロイメントを追加する準備ができました。overviewの右上の角に作成したデプロイメントロケーションが現れ、他のデプロイメントロケーションもドロップダウンリストに表示されます。
このDeploymentsのOverview内から、新規のデプロイメントロケーションの 追加 や既存のデプロイメントロケーションの 管理 が可能です。
デプロイメントの作成
この段階で Add Deployment をクリックしデプロイメントを作成できます。しかし、モデルを追加しない限りそのデプロイメントはコンテンツを持ちません。”Churn”というデプロイメントを作成し、今回の問題は分類であると定めてから、 オートモデルを使用してモデルを作成しましょう。
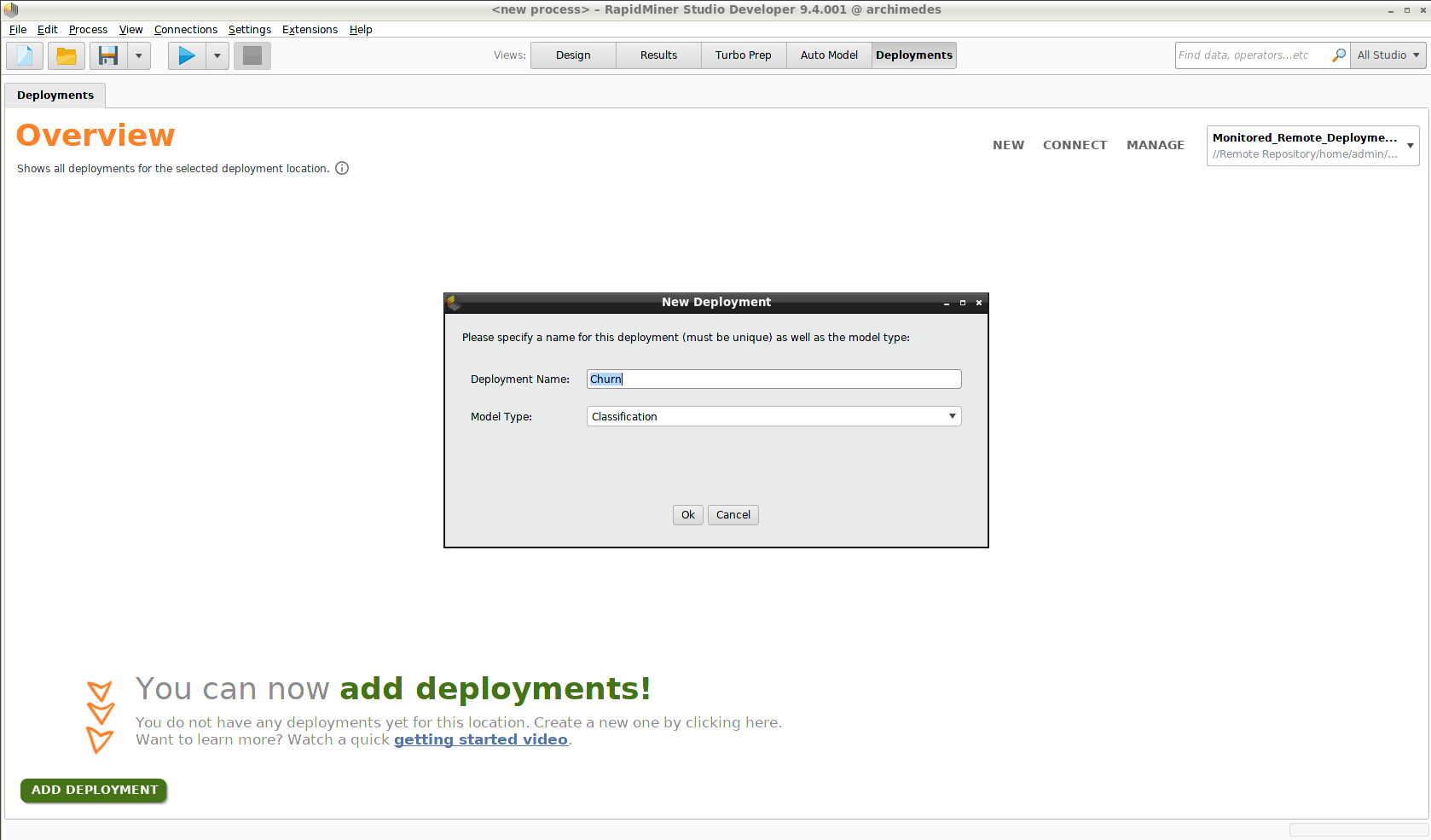
例: Churn
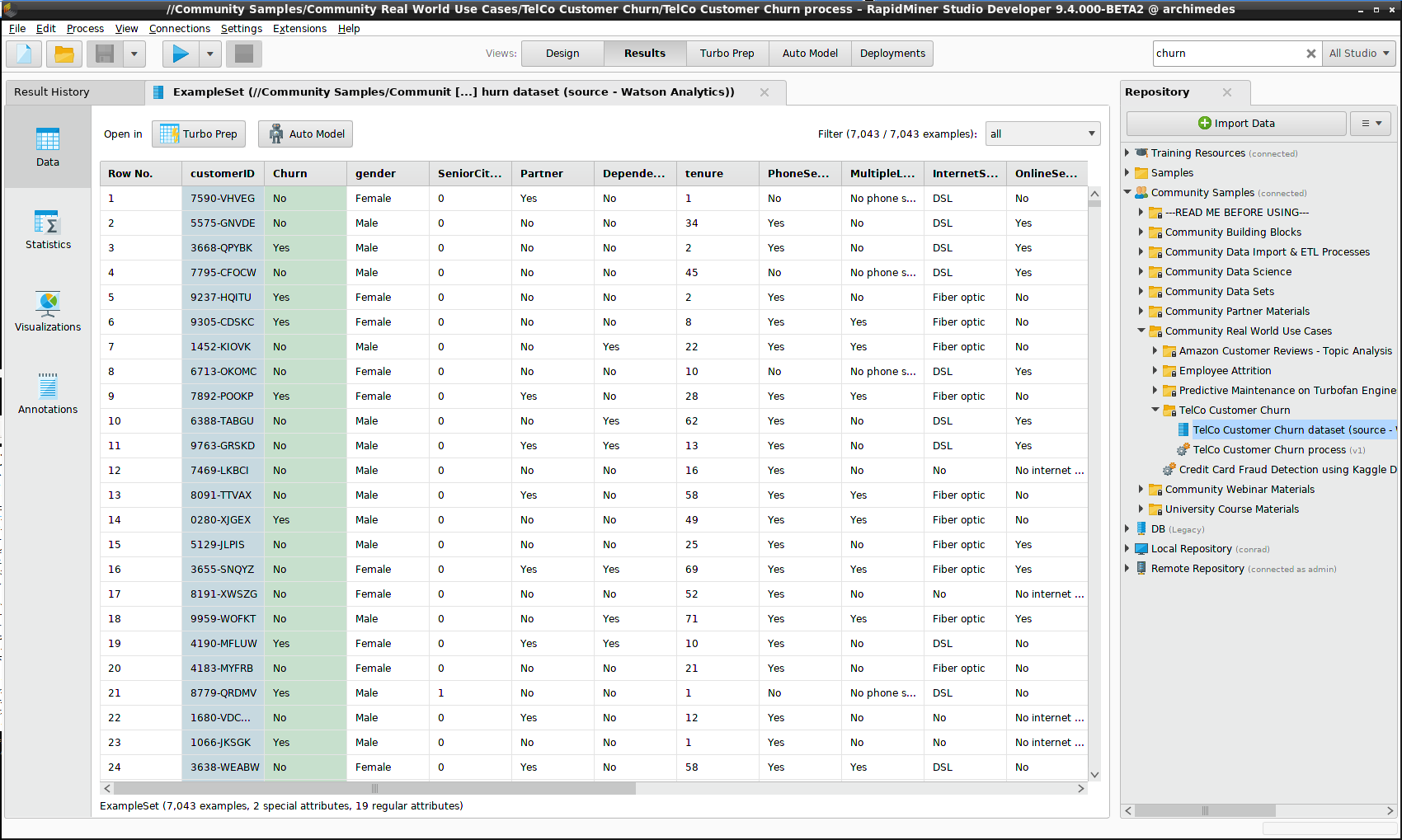
デプロイメントにコンテンツを提供するには、 Community Samples リポジトリで提供されているデータセットを使用します。データセットは Community Samples > Community Real World Use Cases > TelCo Customer Churnにあります。このデータセットの一部をモデル用に、残りをスコアリングのシミュレートに用います。
ここでの問題は、単に電話会社の顧客がサブスクリプションをやめるかを予測するだけでなく、電話会社はリベートによって顧客を維持できると仮定して、もしモデルが解約者を正確に特定できれば、モデルによって得られるゲインはどのくらいかを計算することです。
ゲイン
オプションとして、オートモデルには混同行列の各要素にコストを割り当てることができる評価指標が含まれており、結果が単に真か偽かで判別されるのではなく、利益と損失の観点から識別されるようになります。
オートモデル(Prepare Target)の段階で、 Define Costs / Benefitsボタンを押すとダイアログが開きます。コストは負の値で、利益は正の値で定義されます。
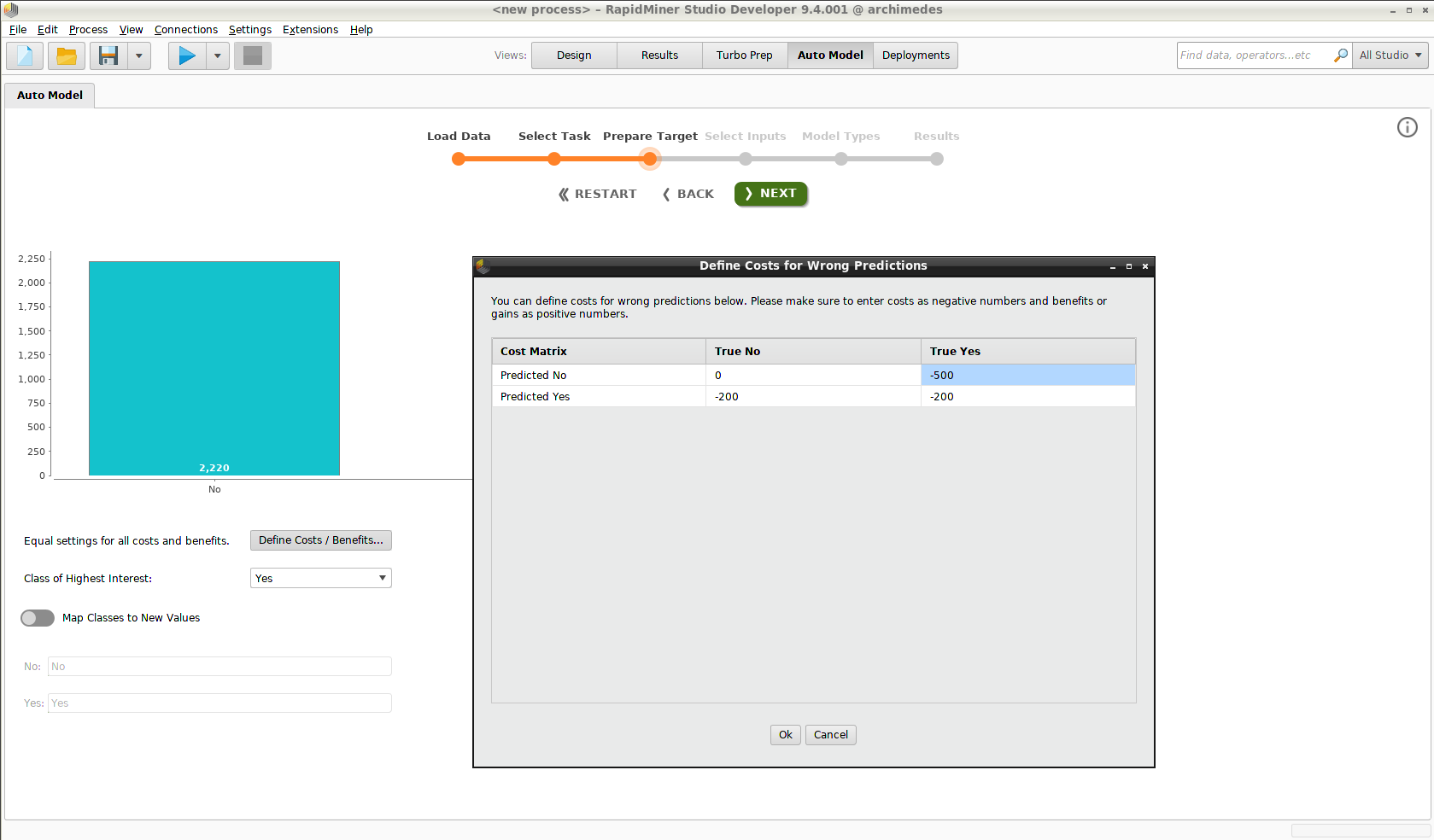
- コストや利益がゼロのデフォルトの状態は、顧客はサブスクリプションを継続しているということです。
- モデルによって離反者と判断された顧客には、継続させるために$200相当のリベートが提供されます。
- 偽陽性(モデルは継続すると予測したが、実際には離反した)は最も悪いケースシナリオです。リベートがあれば、顧客は継続してくれると想定します。したがって、$500のコストがマトリックスのその要素、失った顧客に関連する収益に割り当てられます。
これらの値を用いて、モデルを適用した際のコストを計算し、ベースラインコストと比較します。これにより、離反する(リベートが提供されなかった)すべての顧客は$500の損失と表現されます。モデルによって提供されるゲインは、これら二つの値の差です。
スコアリング、 ダッシュボード、 パフォーマンスサマリーを含む、以下のセクションでは、結果を表示する際、モデルに関連するコストとゲインが含まれます。
オートモデル
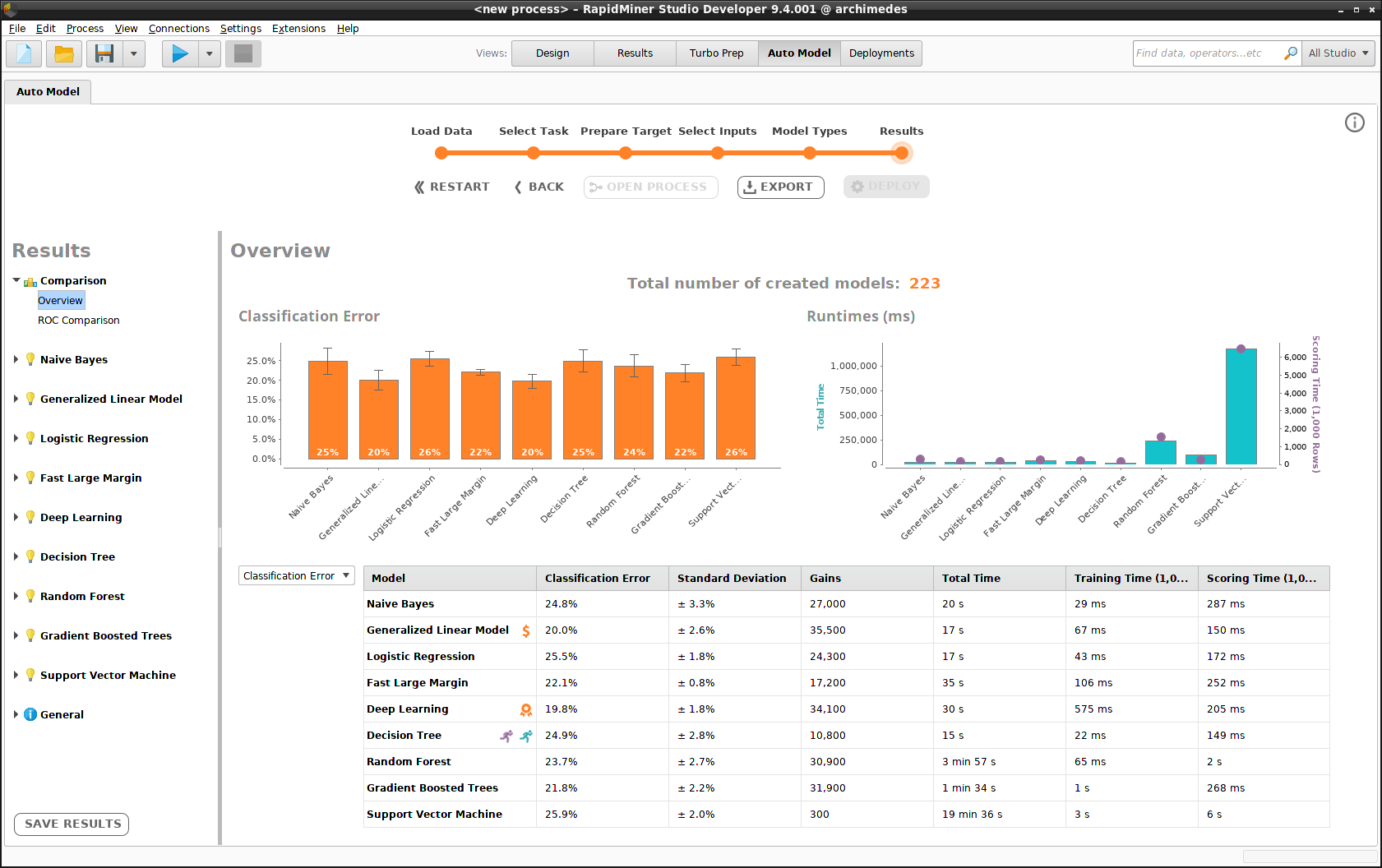
モデルのセットを構築する過程は、 オートモデルで既に述べました。上で述べたように、コスト行列を定義する以外は今回も同じです。全てデフォルトのまま進み、モデルを作成した後は、オートモデルのoverview画面に行きます。
サイドパネルのモデルをクリックして、サブメニューの一つを選択し Deployをクリックして、”Churn”デプロイメントにモデルを一つ、もしくはすべて含めましょう。
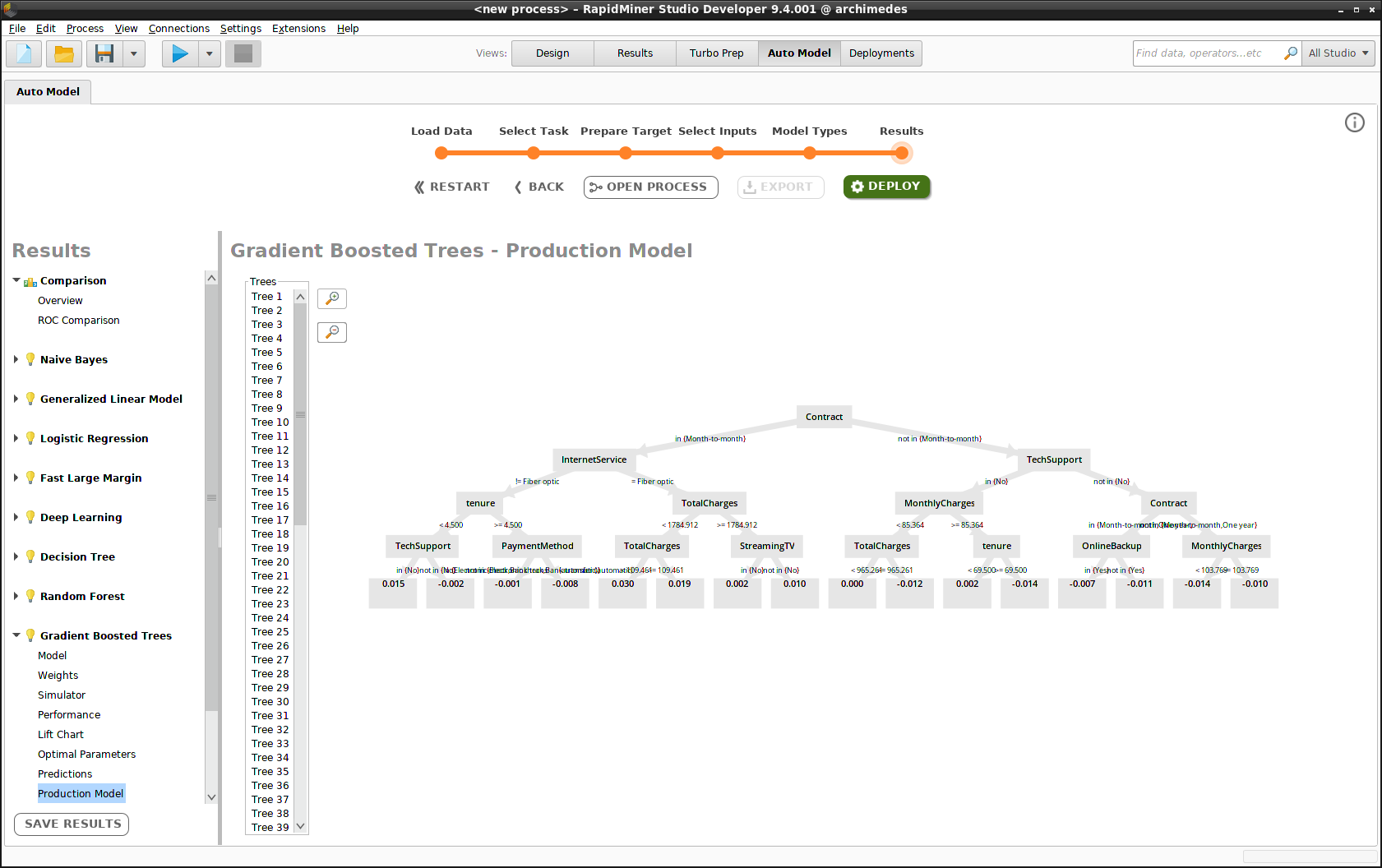
モデルのデプロイ
モデルのデプロイは、三つのステップで構成されます。
- モデルの名前付け(例、”Gradient Boosted Trees”)
- デプロイメントロケーションの選択(例、”Monitored_Remote_Deployments”)
- デプロイメントフォルダの選択(例、”Churn”)
デプロイメントロケーション もしくは デプロイメントをまだ作成していない場合は、このプロセスの中で行うことができます。
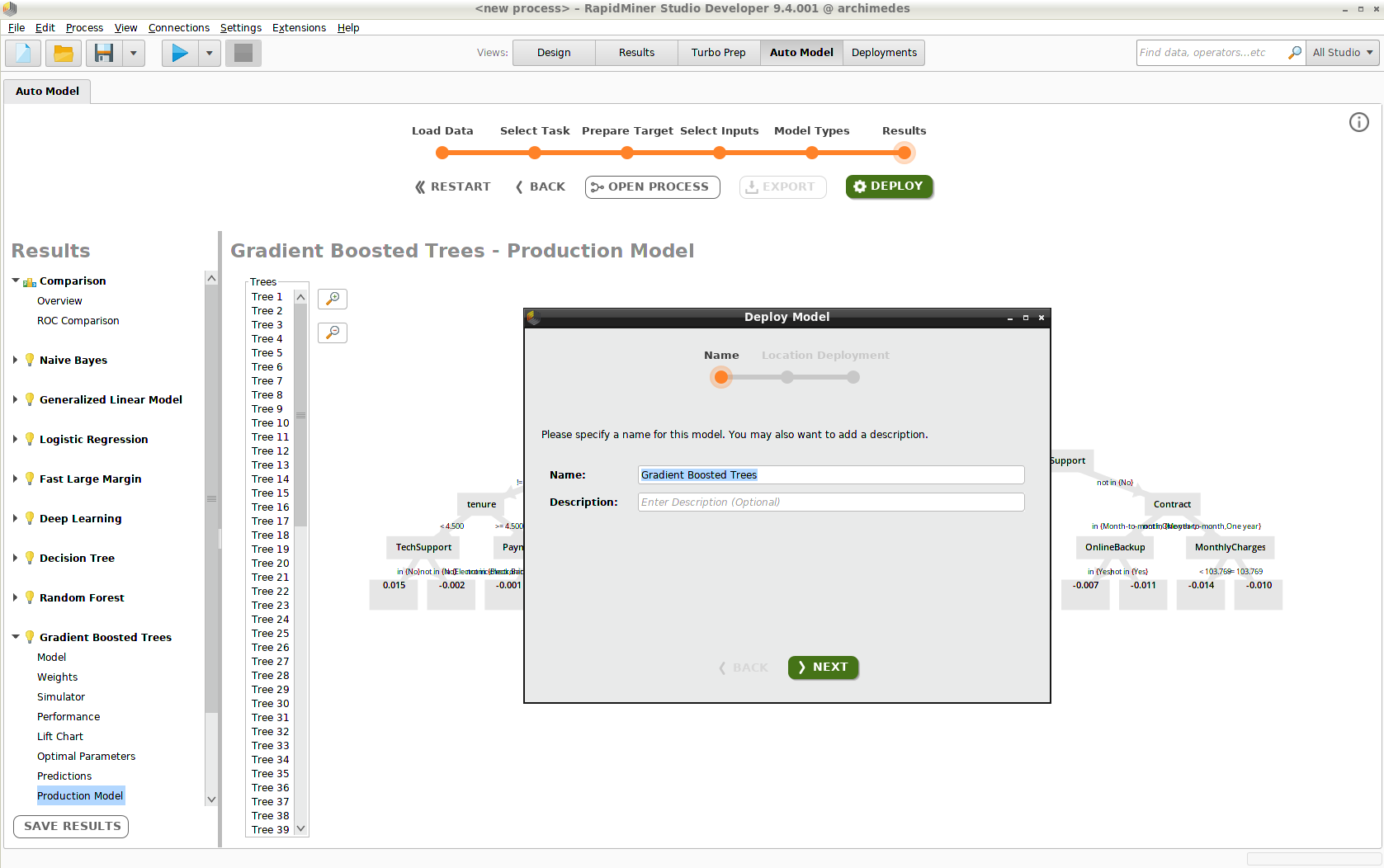
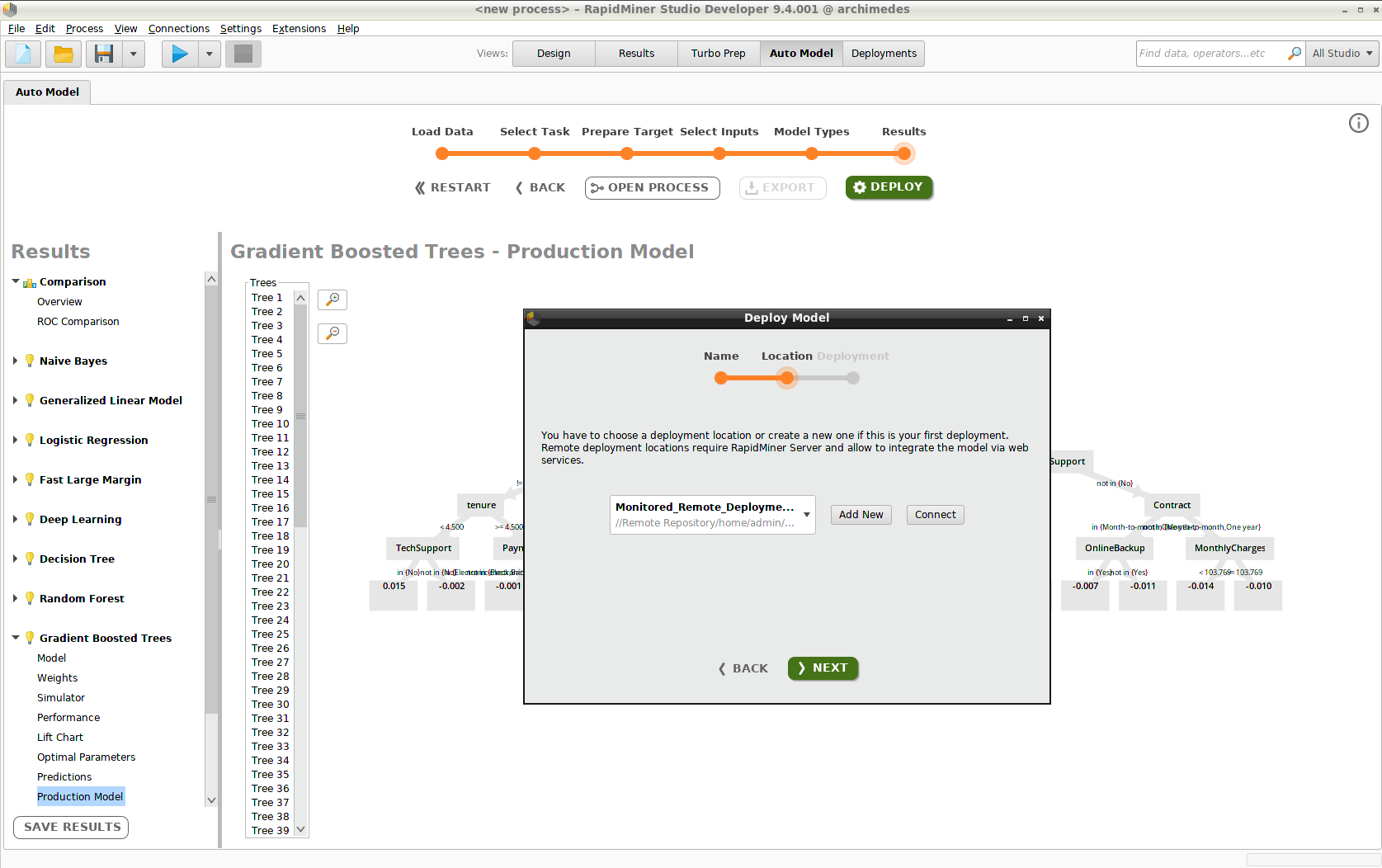
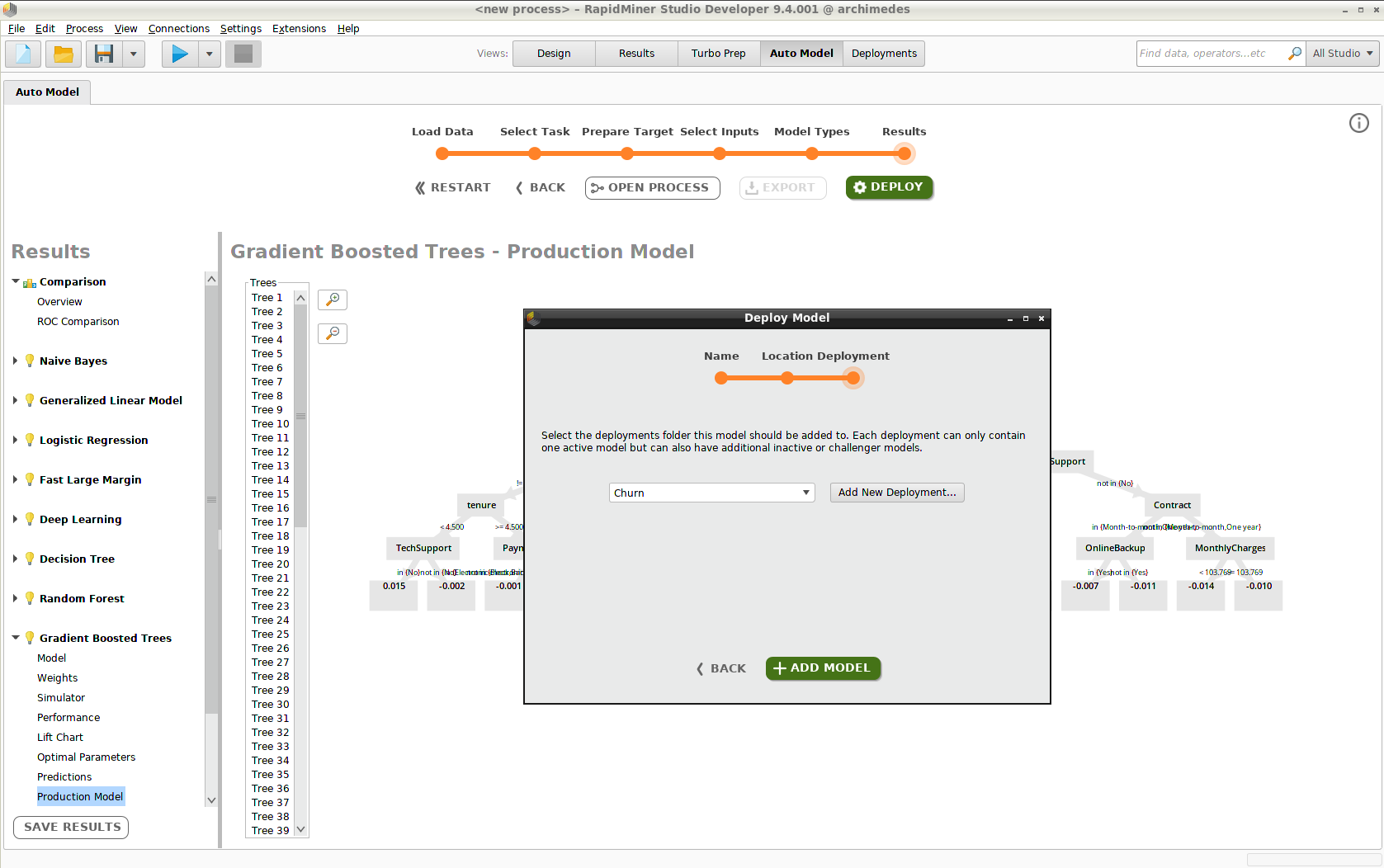
Add Modelをクリックすると、Deployments画面にモデルが現れます。デプロイメントにさらにモデルを追加するには、オートモデルに戻る必要があります。
モデルとスコアリング
このセクションと次のセクションではデプロイメントの コンポーネント について詳細に説明します。
どのデプロイメントでも重要なコンポーネントは、 モデル、モデル シミュレータ、 スコアリングです。データをスコア付けするだけでなく、経時的にスコア付けされたデータの統計量を計算したい場合は、さらに モニタリングを有効にする必要があります。
モデル
通常は、デプロイメントは複数のモデルを含みます。理想では、ベストなパフォーマンスを持つモデルのみを使用したいところですが、世界が変化し入力データが ドリフトしてしまうように、時間の経過とともに状況が変化する可能性を排除できません。
一つのモデルを Activeにマークし、残りのモデルを Challengersにマークするのが良いでしょう。どれをアクティブモデルにするかは、あなた次第です。もっとも良いパフォーマンスのモデルを選ぶかもしれませんし、スコアリングタイムが最も短いモデルを選ぶかもしれません。デプロイメントを使用して新規データのスコア付けを行う度に、アクティブモデルとチャレンジャーの両方が結果を計算します。後になって、あなたの問題にはチャレンジャーモデルのほうが適していると判明した場合、アクティブモデルを置き換えることができます。
以下の例では、デプロイ前のモデルの構築時では、 Generalized Linear Model が最も良いパフォーマンスを得ていました。しかし、予想していたよりも良かったため緑にマークされている Deep Learningと、予想よりわずかに悪いため黄色でマークされている Gradient Boosted Treesに取って変わられていることに注目してください。 Naive Bayes と Decision Tree はどちらもあまり良くありません。これらのモデルのパフォーマンスが低い状態が続く場合は、 Inactiveにマークしておくと、スコアリングにかかる時間を無駄にしないで済むかもしれません。
Gradient Boosted Trees は Deep Learningより良いパフォーマンスを得たため、モデルを右クリックし、 Change to Activeを選択します。
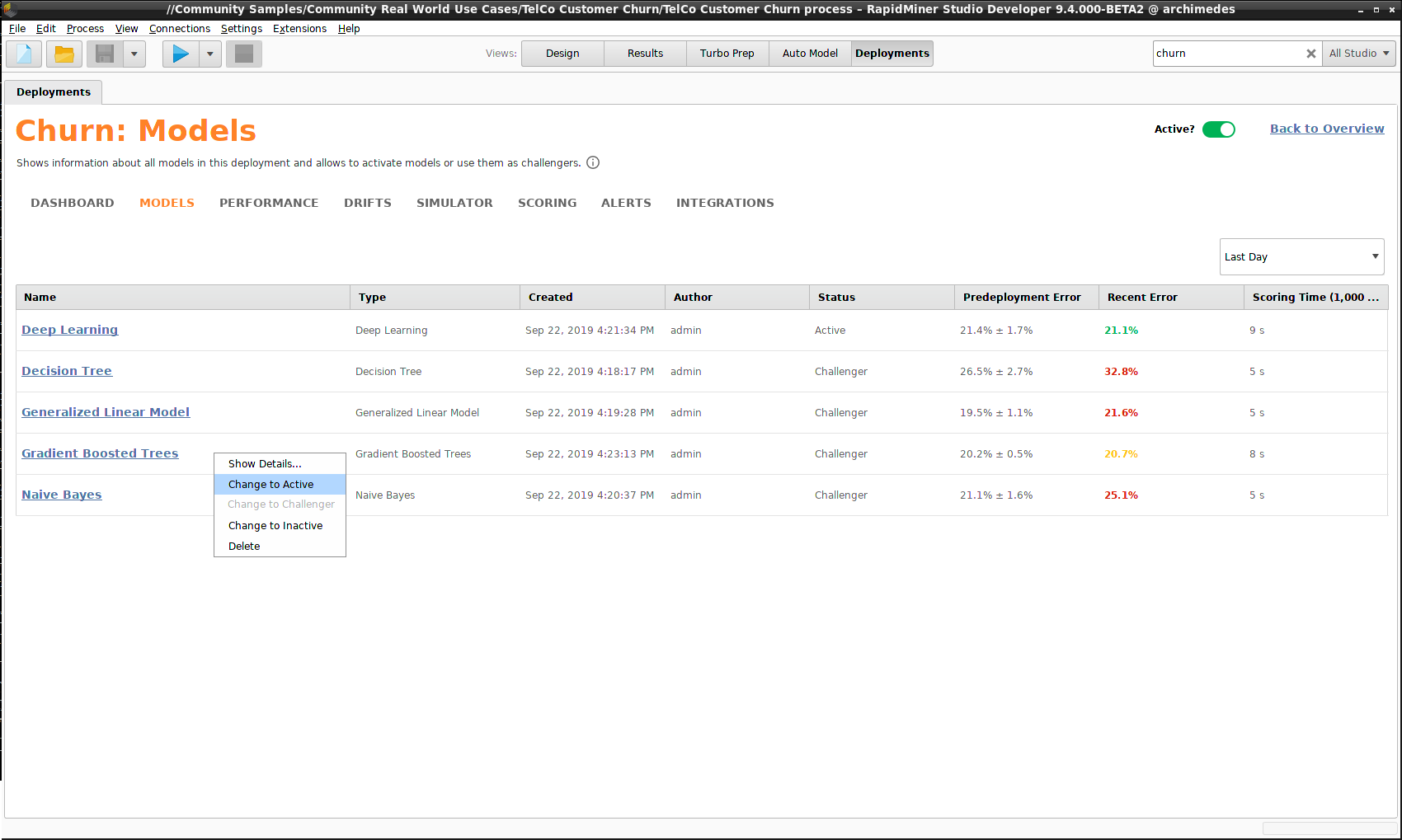
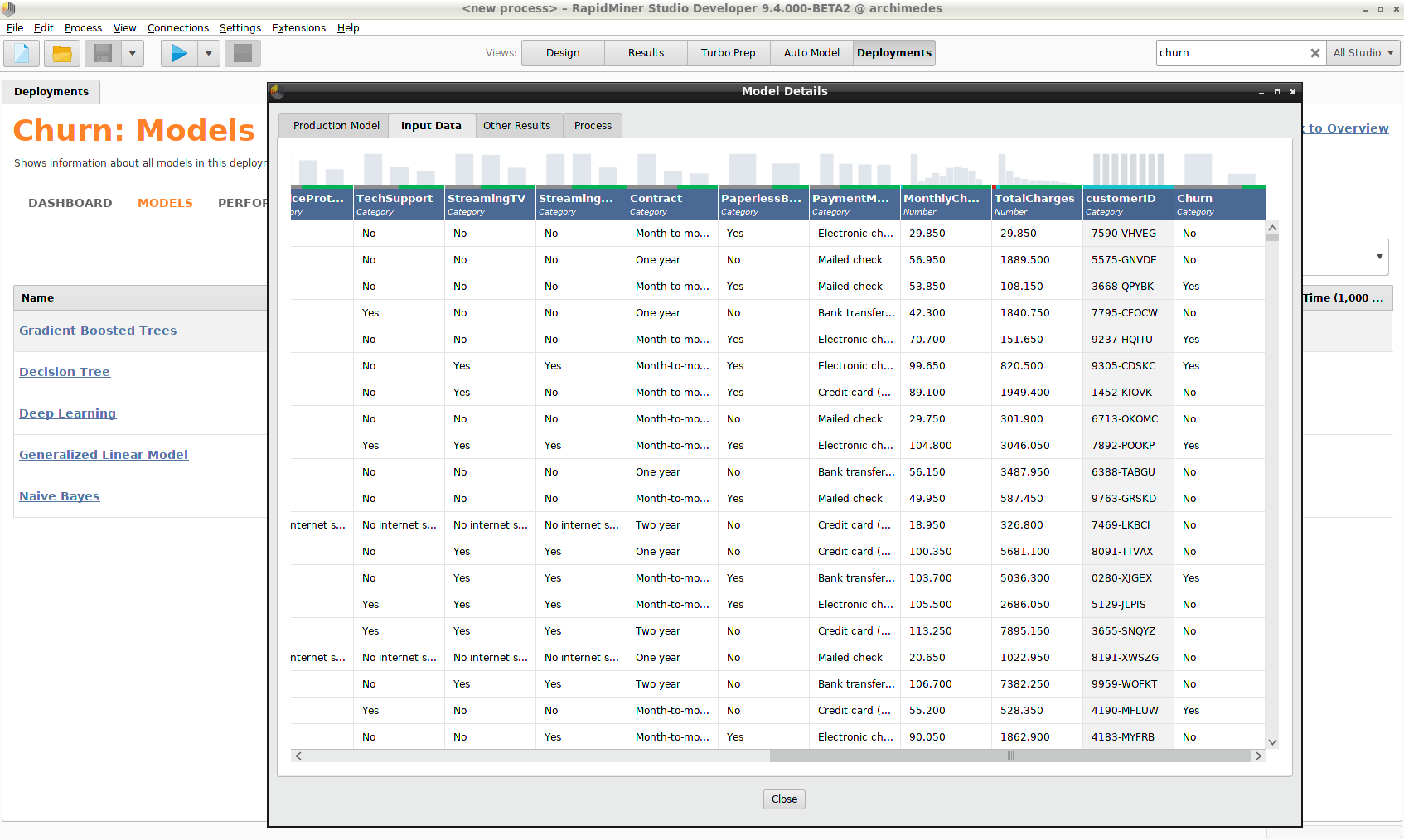
モデルを右クリックし、 Show Detailsを選択すると、モデルには他の情報も含まていることがわかります。
- モデルの作成に使用された完全な Input Data セット
- モデルの構築に使用された Process をXMLで表したもの
GDPRのような規則を遵守するには、この情報が不可欠です。
Process に注釈が付いているバージョンは、 デザイン画面で表示可能です。
シミュレータ
モデルシミュレータについては、 オートモデルで詳細に述べられています。各デプロイメントに付属するシミュレータはアクティブモデルのシミュレータです。
スコアリング
データのスコアリングに関して、プログラム的なアプローチは インテグレーションをご覧ください。
ほぼ間違いなく、デプロイメントの主な目的はデータをスコア化することでしょう。モデルは新しいデータを入力として受け取り、結果を返します。 モニタリングを有効 (強くお勧めします)にしている場合、結果が収集されるので長期的な統計をとることができます。
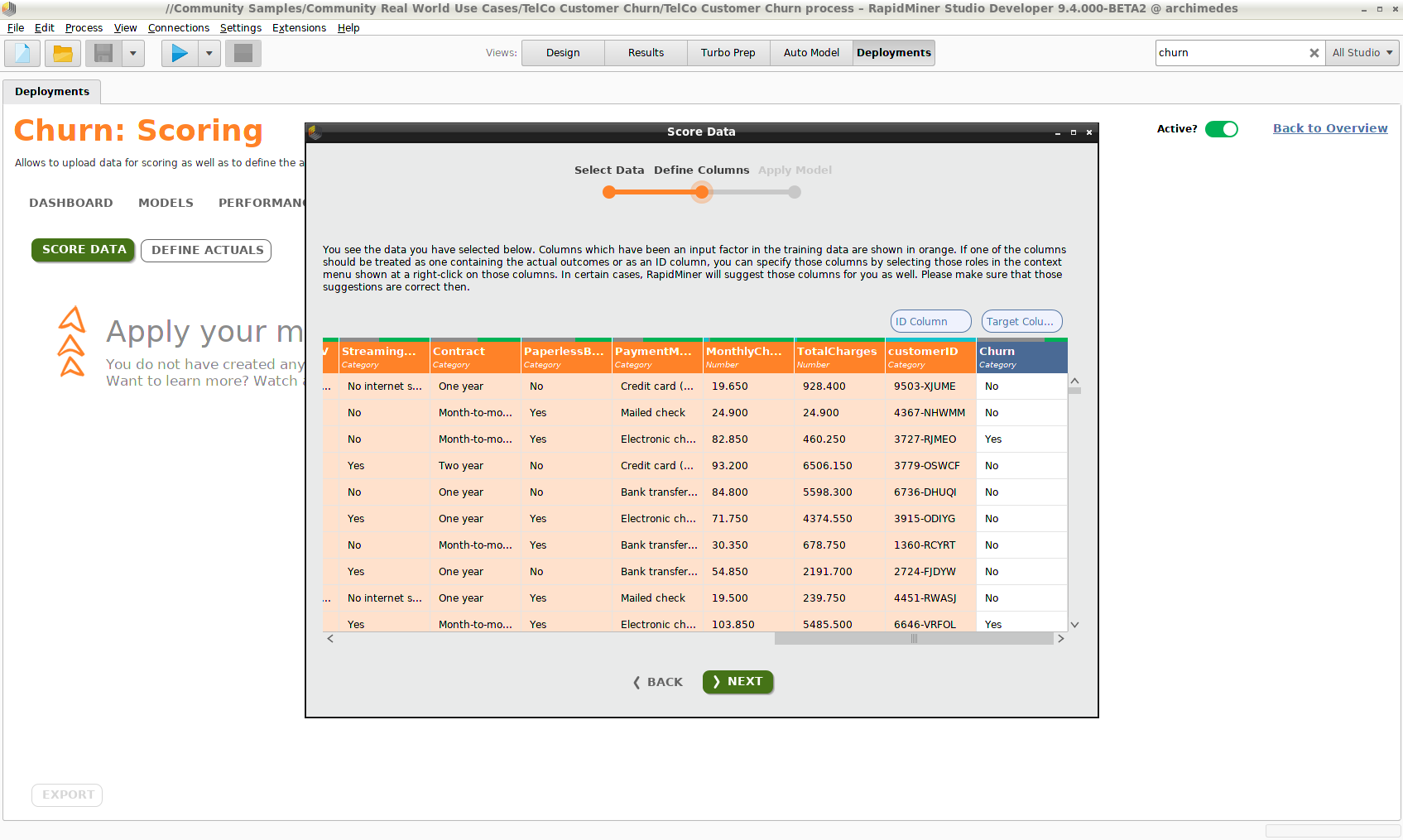
Score Dataをクリックし、リポジトリからデータセットを選択します。以下のポイントに注意してください。
- スコアリングデータセットには、モデルの構築に使用されたデータセットと似た列を含めるべきです。スコアリングプロセスは同じスーパータイプ(例えば、realやinteger型などはどちらも数値です)をもつ限り、少し異なるデータ型も受け入れるのに十分なロバスト性を持っています。また、データ型や分布が入力データに似ている限り、プロセスは列名の変更も検出することが可能です。
- モデルの構築時に含まれなかったデータ列は無視されます。
- モデルに必要ですが、欠損しているデータ列は、平均値や最頻値を使用して提供されます。
データの二列は特別なステータスを持ちます。
- 目的変数 – スコアリングデータの目的変数が既知の場合、予測と比較してモデルのエラー率の統計量を生成することができます。スコアリングの時点ではこの情報を持っていないことが多いです(そのために、予測を得たいのですから)。しかし、 ID列を介してデータを特定できれば、後から追加可能です。
- ID列 – スコアリングデータに 目的変数 はなくても、 ID列がある場合は、目的変数の値がわかったときに、後から同じIDをもつデータを再提出することで、エラー率と他の統計量を生成することができます。 Define Actuals をクリックし、データの再提出が可能です。
スコアリングデータを提出する際には、IDと目的変数を識別するステップがあります。たとえこれらの列が誤って識別された場合でも、設定する列を右クリックし、 Use as ID もしくは Use as targetを選択すると、正しい値を割り当てることができます。モデルに入力として使用されないデータ列のみ、IDもしくは目的変数と識別することができます。
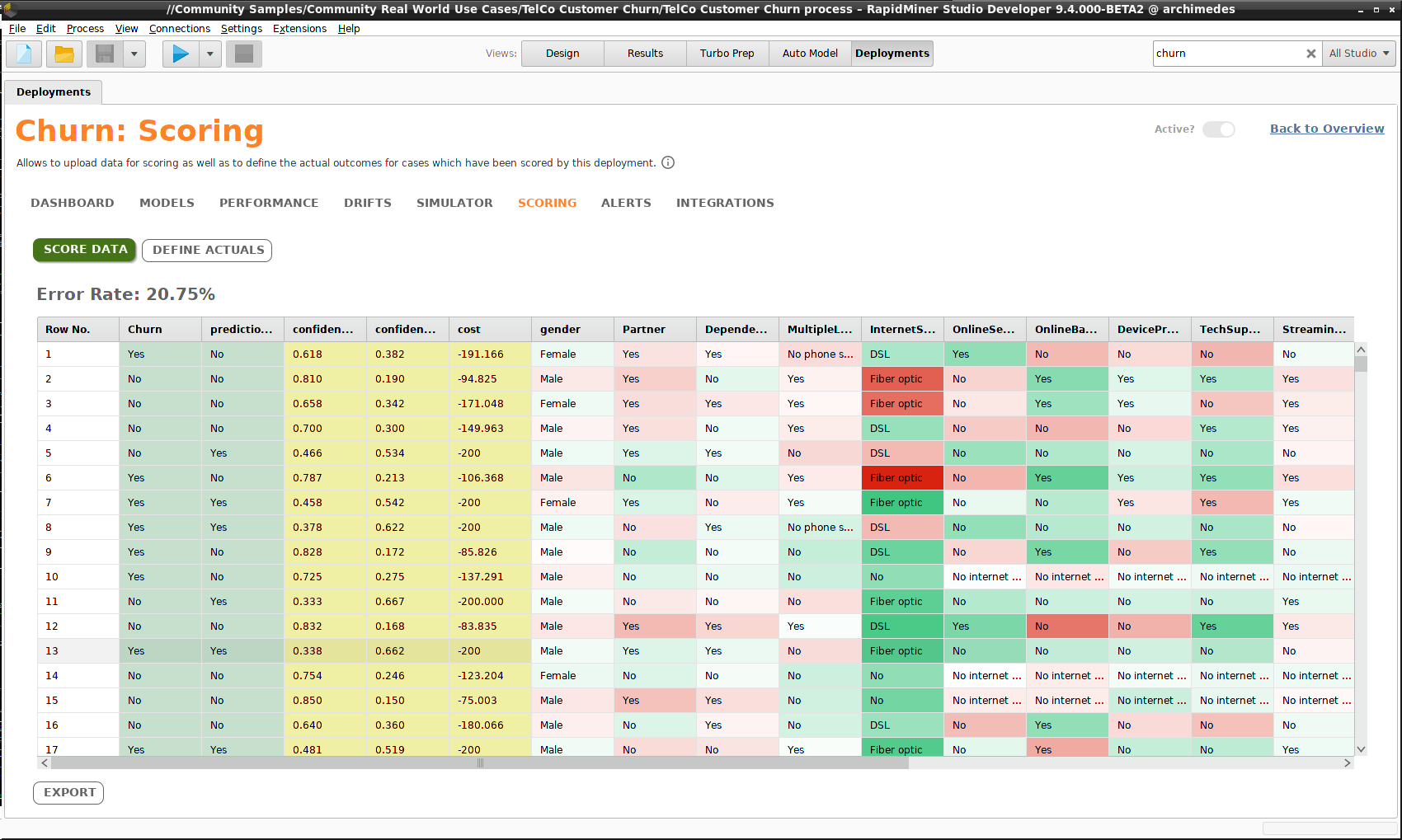
結果はいくつかの追加データ列を含むテーブルで返されます。
- prediction(予測)
- confidence values(確信度)
- costs(コスト)
今回の例では、スコアリングデータに目的変数が含まれているため、エラー率が計算されます。結果をファイルやリポジトリに エクスポート することができます。
オートモデルを実行したときに、 Explain Predictions のチェックボックスがチェックされているとき、スコアリングデータは予測の重要性によって色分けされます。濃い緑色の値はその行の予測を強く支持し、濃い赤色の値はその行の予測とは異なる予測を強く支持し、薄い色はあまり重要ではありません。
モニタリング
モニタリングを有効にするには、 データベース接続を作成する必要があります。現在、MySQLとPostgreSQLがサポートされています。
モデルオペレーションデータベースは RapidMiner AI Hub データベースと独立していることに注意してください。もしRapidMiner AI HubデータベースをMySQLもしくは PostgreSQLでインストールした場合、同じデータベースを使用できますが、その必要はありません。
データにスコアをつける度に、結果が出ます。すべての結果を手動で収集して分析する方法もありますが、もっと良い方法があります。
モニタリングを有効にすると、スコアリングの統計が収集されるため、すべてが期待通り動作しているかを確認できます。モニタリングをすることで、以下の問いに答えることができます。
- 定期的にデータをスコア付けしていますか? それはどのくらいのデータ量ですか?
- モデルのエラー率はいくつですか?
- モデルをデータに適用することで得た ゲイン はどのくらいですか?
- スコアリングデータの分布はモデルと一致していますか(ドリフト)?
- 異常なイベントが アラートのトリガーになっていますか?
- データをスコア付けする際の、平均レスポンスタイムはどのくらいですか?
これらの質問に対する回答は ダッシュボード に累積して表示され、(モデル毎の)詳細は パフォーマンス サマリーに表示されます。
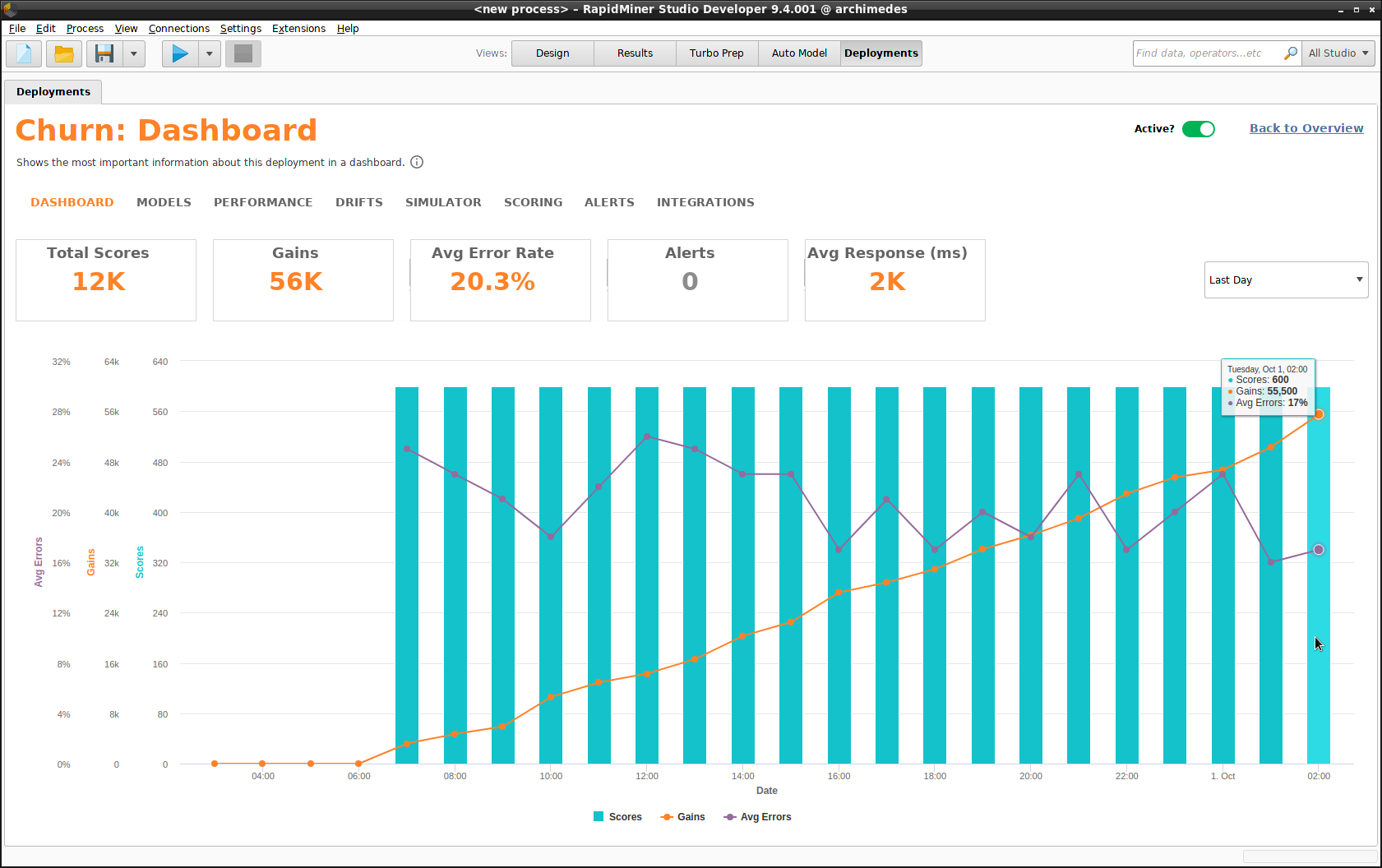
ダッシュボード
ダッシュボードでは以下の統計量が経時的にに表示されます。時間の間隔は毎日、毎週、毎月、または四半期ごとを選択できます。詳細は、 パフォーマンス サマリーをご覧ください。
- Scores(スコア)
- Gains(ゲイン)
- Average errors(平均エラー率)
- Alerts(アラート)
- Average response time(平均レスポンスタイム)
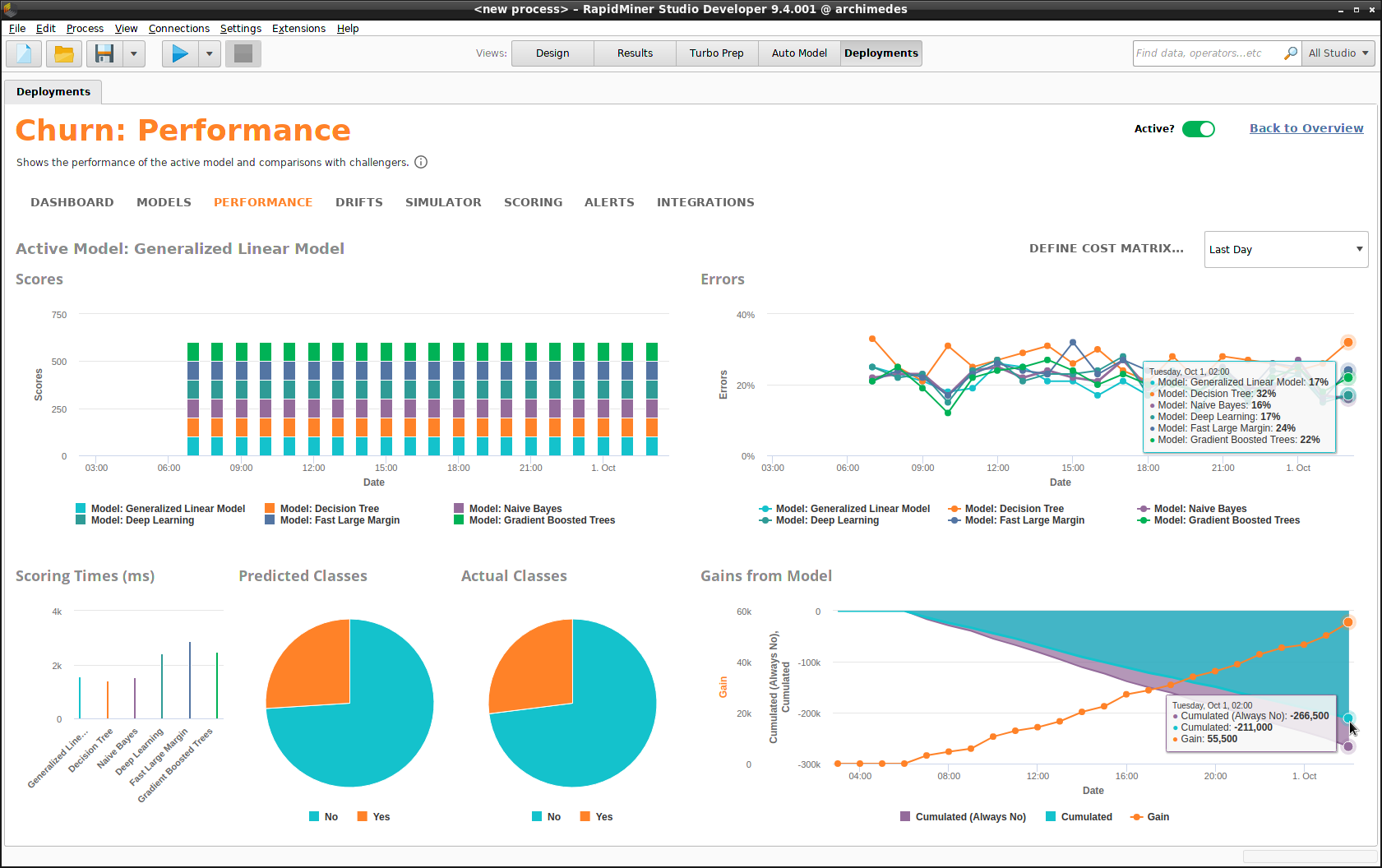
パフォーマンス
パフォーマンスサマリーは ダッシュボードより詳細な統計量をモデル毎に経時的に表示します。時間の間隔は毎日、毎週、毎月、または四半期ごとを選択できます。パフォーマンスサマリーはモデルオペレーションの心臓部です。
- Scores(スコア)
- Errors(エラー率)
- Scoring Times(スコアリングタイム)
- Predicted Classes versus Actual Classes(予測クラス 対 実際のクラス)
- Gains from Model(モデルから得られたゲイン)
Define Cost Matrixをクリックすると、以前作成した コスト行列 を再定義でき、 Gains from Modelのチャートも修正されます。
ドリフト
デプロイメントモデルを構築するのに使用された入力データの各列には、値によってユニークな分布があります。スコアリングデータが入力データと同一になるとは期待できませんが、モデルの成功はある程度データの分布の安定性に依存します。スコアリングデータが入力データと異なる分布を持つ場合、これはドリフトと呼ばれます。
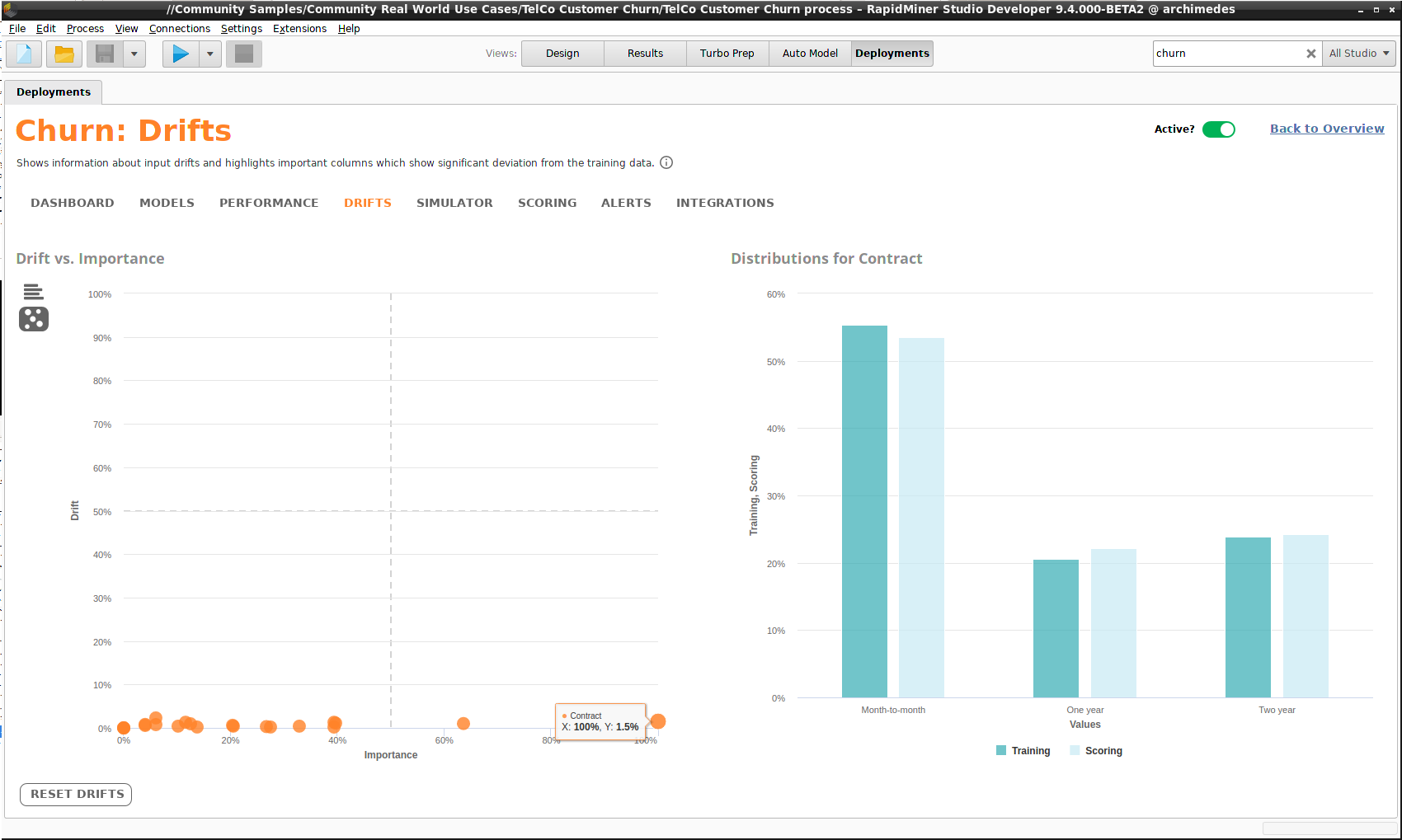
ドリフトは珍しいことではありません。世界は変化するため、データの分布も変化します。しかし、変化が大きければ、モデルを作り直したほうが良いでしょう。変化が大きいか、どうすればわかるでしょうか? Driftコンポーネントが答えを得るのに役立ちます。入力データの各列ごとに、Driftは入力データの分布とスコアリングデータの分布を比較します。二種類のチャートを利用できます。
- Drift for Factors – ドリフトの大きい順に列名を並べた棒グラフです。棒グラフをクリックすると、分布を確認できます。
- Drift vs. Importance – 各列の重要度に対するドリフトを計算した散布図です。データ点をクリックすると、分布を確認できます。
スコアリングで重要な役割をもつ列のドリフトが大きい場合に、問題が発生します。最悪のケースでは、散布図の右上の象限にデータ点が現れます。下の例では、そのような問題はありません。”Contract”は重要な列ですが、ドリフトはゼロに近く、右の二つの分布は非常に似ていることが確認できます。
リモートデプロイメント
アラート と インテグレーションを利用するには、RapidMiner AI Hubをインストールし、リモート デプロイメントロケーションを作成する必要があります。
アラート
アラートを作成するには、 リモートデプロイメント ロケーションが必要になり、 モニタリングを有効にする必要があります。
さらに、メールアラートを送信するには、 デプロイメントロケーション に メール送信接続を含む必要があります。
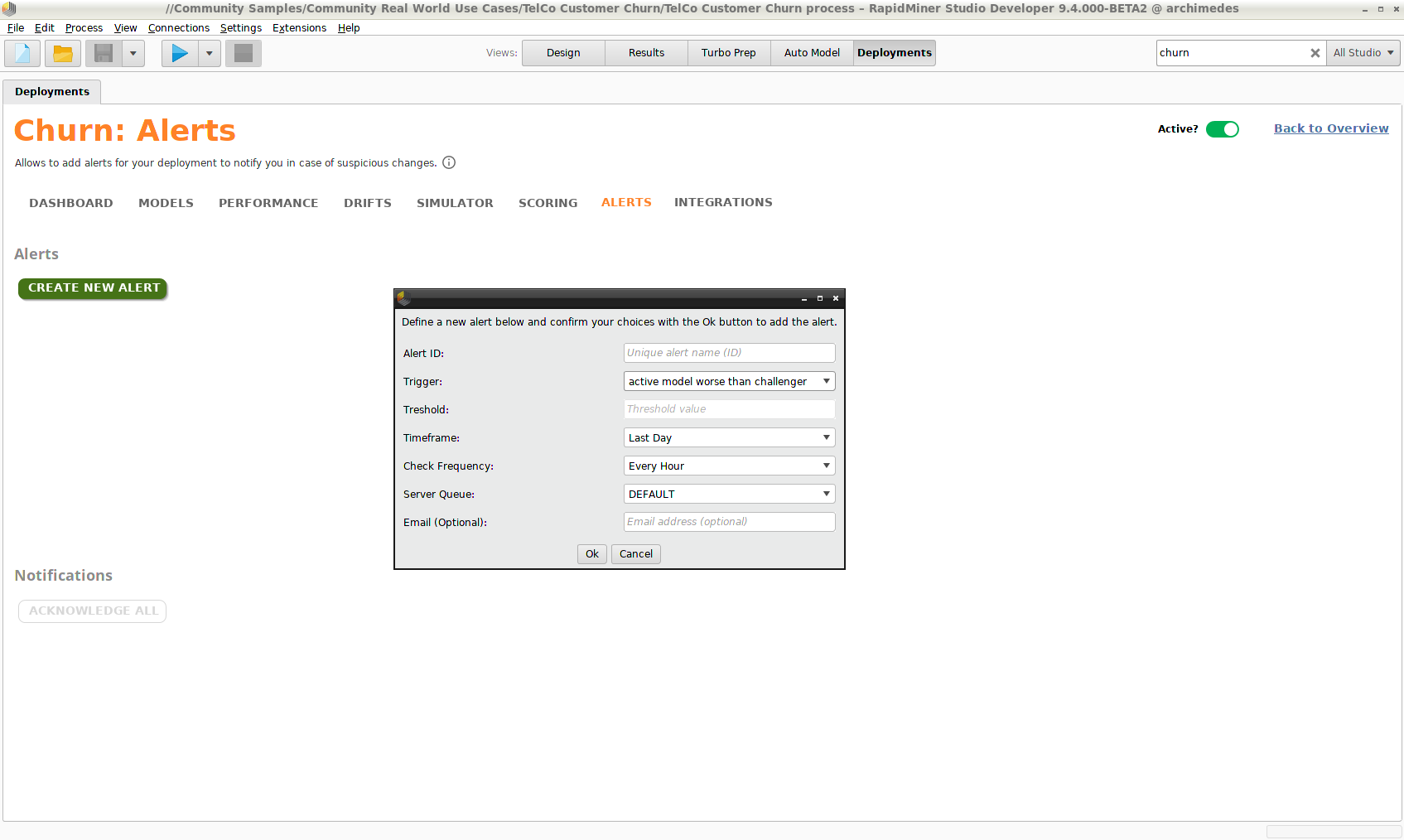
デプロイメントに異常や望ましくない動きがあった場合、アラートが警告します。アラートのトリガーには次のようなものがあります。
- 平均エラー率がユーザーが設定した閾値を超える
- 平均スコアリングタイムがユーザーが設定した閾値より大きい
- 与えられた期間内で想定よりスコアが少ない
- アクティブモデルがチャレンジャーよりエラーが多い
- ドリフト がユーザーが設定した閾値より大きい
アラートを作成するには、 Create New Alertをクリックします。アラートが始動すると、 ダッシュボードに現れるだけでなく、メールを送信するように設定することも可能です。
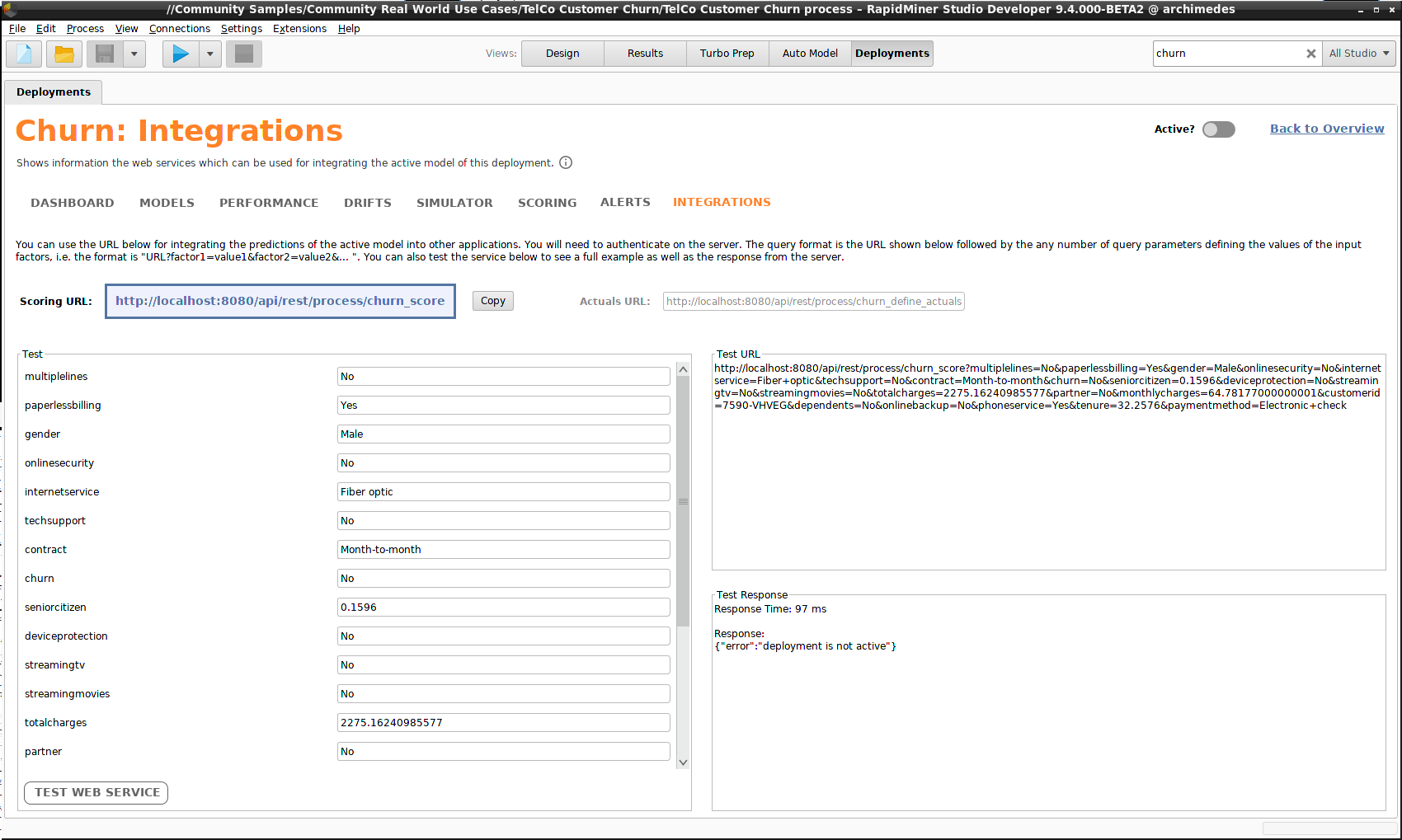
インテグレーション
インテグレーションとは、スコアリング用のデータを送信できる Scoring URLを提供する webサービスです。このコンテキストでは、 スコアリング インタフェースの Define Actuals に相当する Actuals URLも提供します。スコアリングプロセスの自動化を計画している場合、まさに必要なのはwebサービスです。RapidMiner AI Hubは REST APIを提供しており、他のソフトウェアとデプロイメントを統合するのに役立ちます。
Integrationsコンポーネントは Scoring URL を表示し、スコアリングデータの任意の値でテストすることができます。以下のスクリーンショットの右側に、 Test URL と Test Responseを確認できます。この例では、画面右上の Active? スイッチを押し忘れたため、サーバーからのレスポンスは”deployment is not active”となっていますが、通常レスポンスにはJSON形式で確信度ありの予測が含まれます。